Advertisement: Support SunWorld, click here!
|
|
Kernel synchronization primitives
Jim provides a look at the various systems architectures for building multiprocessor systems, and describes how Solaris keeps things synchronized
Summary
Multiprocessor systems are mainstream these days. From the desktop to
the datacenter, systems with more than one processor are used for everything
from high-end desktop applications to large datacenter backends. This month, Jim takes a brief look at the multiprocessor systems architectures in use today, including the shared memory multiprocessor architecture, Sun's choice for its multiprocessor systems. His discussion will provide a solid background for a segue into the locking primitives used by the Solaris kernel to facilitate multiprocessor platform support. (5,500 words)
| |
INSIDE SOLARIS
|
|
|
| By Jim Mauro |
 ultiprocessor (MP) systems from Sun are implemented as shared
memory multiprocessor (SMP) systems. Symmetric multiprocessor is
also a common expansion of the SMP acronym, and Sun's MP systems
meet the criteria for both definitions. Symmetric multiprocessor
describes a system in which a peer-to-peer relationship exists among
all the processors (CPUs) on the system. A master processor,
defined as the only CPU on the system that can execute operating
system code and field interrupts, does not exist. All processors are
equal. The shared memory definition describes an architecture in
which all the processors have a uniform view of all the systems'
physical and virtual address space, and a single image of the
operating system is shared by all CPUs. Sun SMP systems are built on
interconnects that provide very high sustainable bandwidth and low,
uniform latency. Additionally, Sun SMP systems have a uniform view
of I/O space and uniform I/O access characteristics. In other words,
the I/O interfaces are the same distance from all the processors on
the system, in terms of latency and bandwidth, regardless of where
they reside physically.
ultiprocessor (MP) systems from Sun are implemented as shared
memory multiprocessor (SMP) systems. Symmetric multiprocessor is
also a common expansion of the SMP acronym, and Sun's MP systems
meet the criteria for both definitions. Symmetric multiprocessor
describes a system in which a peer-to-peer relationship exists among
all the processors (CPUs) on the system. A master processor,
defined as the only CPU on the system that can execute operating
system code and field interrupts, does not exist. All processors are
equal. The shared memory definition describes an architecture in
which all the processors have a uniform view of all the systems'
physical and virtual address space, and a single image of the
operating system is shared by all CPUs. Sun SMP systems are built on
interconnects that provide very high sustainable bandwidth and low,
uniform latency. Additionally, Sun SMP systems have a uniform view
of I/O space and uniform I/O access characteristics. In other words,
the I/O interfaces are the same distance from all the processors on
the system, in terms of latency and bandwidth, regardless of where
they reside physically.
Alternative MP architectures change the SMP model in different ways.
Massively parallel processor (MPP) systems are built on nodes that
contain a relatively small number of processors, some local memory,
and I/O. Each node contains its own copy of the operating system,
which allows each node to address its own physical and virtual address space.
The address space of one node is not visible to the other nodes on
the system, and the nodes are connected together with a high-speed, low
latency interconnect, and node-to-node communication is done through
an optimized message passing interface. MPP architectures require a
new programming model in order to achieve parallelism across nodes.
The SMP does not work because
address spaces are not visible across nodes; memory pages cannot be
shared by threads running on different nodes. Thus, an API that
provides an interface into the message-passing path in the kernel
must be used by code that wishes to scale across the various nodes
in the system. There are other issues around the nonuniform nature
of the architecture with respect to I/O processing, as the I/O
controllers on each node are not easily made visible to all the
nodes on the system. Some MPP platforms attempt to provide the
illusion of a uniform I/O space across all the nodes using kernel
software, but the nonuniformity of the access times to nonlocal
I/O devices still exists.
NUMA and ccNUMA (nonuniform memory access and cache coherent NUMA)
architectures attempt to address the programming model issue
inherent in MPP systems. From a hardware architecture point of view,
NUMA systems resemble MPPs -- small nodes with few processors, a
node-to-node interconnect, local memory, and I/O on each node. The
operating system software is designed to provide a single system
image, where each node has a view of the system's memory address
space. In this way, the shared memory model is preserved. However,
the nonuniform nature of memory access is a factor in the
performance and potential scalability of the platform. When a thread
executes on a processor node on a NUMA or ccNUMA system and incurs a
page fault (references an unmapped memory address), the latency
involved in resolving the page fault varies, depending on whether the physical memory page is on the same node as the executing
thread or on a node somewhere across the interconnect. The latency
variance may be substantial. As the level of memory page sharing
increases across threads executing on different nodes, there is a
potentially higher volume of page faults that need to be resolved
from a nonlocal memory segment, adversely effecting performance and
scalability.
At this point, you should have a sufficient enough background in parallel architectures to understand our upcoming discussion on building a scalable operating system for an SMP
architecture. Keep in mind that we've barely scratched the surface of this very
complex topic; entire texts (see Resources) have been devoted to parallel architectures, and I recommend you reference them for
additional information. The diagram in Figure 1 below illustrates the different
architectures.
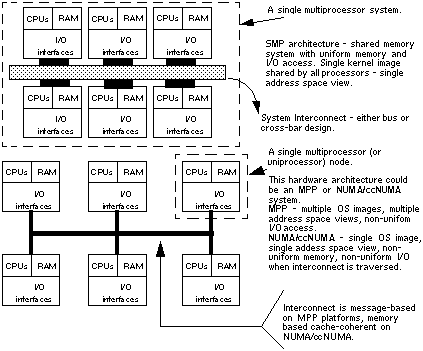
Figure 1. Various parallel architectures
|
As I alluded to earlier, Solaris is currently designed for optimum
performance on SMP architectures. The challenge in building an
operating system that provides scalable performance on an SMP
platform is maintaining data integrity. Multiple processors can run
kernel code, handle interrupts, etc. Kernel data and state
information must be preserved -- multiple processors cannot
update or change the same set of data at the same time. In addition, access
to such data must be synchronized system wide.
The definition of scalable performance is somewhat subjective. Our
working definition in the context of this column defines scalability
as getting more work done on a system when the system grows. Adding
more processors means getting more work done, or reducing the amount
of time it takes to get the same amount of work done. The system must be able
to have multiple processors executing operating system code
concurrently -- concurrency is key to scalability.
The problem, as I said, is maintaining data integrity on data
structures, data links, and state information in the kernel. We cannot allow threads running on multiple processors to manipulate
pointers to the same data structure on the same linked list all at
the same time. We should prevent one processor from reading a bit of
critical state information (for example, is a processor online?) while a
thread executing on another processor is changing the same state
data (for example, in the process of bringing a processor online, but the
processor is still in a state transition).
To solve the problem of data integrity on SMP systems, the
kernel implements locking mechanisms and requires that all
operating system code be aware of the number and type of locks that
exist in the kernel, and comply with the locking hierarchy and rules
for acquiring locks before writing or reading kernel data. It is
worth noting that the architectural issues of building a scalable
kernel are not very different from those of developing a
multithreaded application to run on an SMP system. Multithreaded
applications must also synchronize access to shared data, using the
same basic locking primitives that are used in the kernel (discussed in more
below). Other synchronization problems exist in kernel code that make the problem significantly more complex for operating systems development, such as dealing with interrupts and trap events, but the fundamental problems are the same.
Solaris implements several different types of locks (kernel
synchronization is not a one-size-fits-all problem), each designed
to address a specific requirement for data integrity while minimally
impacting performance.
Mutex locks
Kernel threads executing on the system need to acquire locks when
they enter different areas of the kernel. There are only two
possible states a lock can be in when a thread attempts to get
ownership: free or not free (owned, held, etc.). A requesting thread
gets ownership of a free lock when the get-lock (I'm using a
generic term here) function is entered. If the lock is not free, the
thread most likely needs to block and wait for it to become
available. So we need a sleep queue facility for managing threads
blocking on locks. This is where turnstiles come into play. We
discussed turnstiles in detail last month.
When a thread releases a lock, two possible conditions need to be handled: either threads are sleeping, waiting for
the lock, or no waiters exist. With no waiters, the lock can
simply be freed. With waiters, the thread (or threads) must be
removed from the sleep queue and made runable so it can take
ownership of the lock. Figure 2 provides an overview.
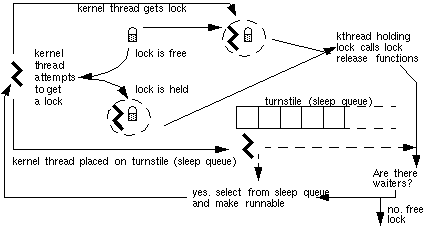
Figure 2. Kernel thread/lock process overview
|
Our discussion so far may seem quite rudimentary, but it's easy to get mired in the low-level implementation details and lose sight of the big picture -- it's the old forest and trees problem. We've covered the forest. Now, here are the trees.
Mutual exclusion, or mutex, locks are the most common type of
synchronization primitive used in the kernel. Mutex locks serialize
access to critical data, where a kernel thread must acquire the
mutex specific to the data region being protected before it can read
or write the data. The thread is the lock owner while it's holding
the lock, and the thread must release the lock when it's finished
working in the protected region, allowing other threads to access the
protected data.
If a thread attempts to acquire a mutex lock that is being held, it
can basically do one of two things: it can spin, or it can block.
Spinning means that the thread will enter a tight loop, attempting
to acquire the lock in each pass through the loop. The term spin
lock is often used to describe this type of mutex. Blocking refers
to the thread being placed on a sleep queue while the lock is being
held, and the kernel sending a wakeup to the thread when the lock is
freed. There are pros and cons to both approaches. The spin approach
has the benefit of not incurring the overhead of context switching
required when a thread is put to sleep. This approach also has the advantage
of a relatively fast acquisition when the lock is freed, because
there is no context-switch operation. The downside comes in the form of CPU consumption while the thread is in the spin loop; the CPU is not
really doing any useful work.
The blocking approach has the upside of freeing the processor to
execute other threads while the lock is being held, and the downside
of requiring context switching to get the waiting thread off the
processor and a new runable thread on the processor. There's also a
little more lock acquisition latency because a wakeup and context
switch are required before the blocking thread can become owner of
the lock it awaits.
In addition to the issue of what to do if a requested lock is being
held, we also need to resolve the question of lock granularity. Let's take a simple example. The kernel maintains a process table, which is a linked list of process structures, one for each of the processes running on the system. A simple table-level mutex could be implemented, which would require any thread needing to manipulate a process structure to first acquire the process
table mutex.
This level of locking is very coarse. It has the advantage of
simplicity, and minimal lock overhead. It has the obvious
disadvantage of potentially poor scalability because only one thread
at a time can manipulate objects on the process table. Such a lock
is likely to have a great deal of contention (become a hot lock).
The alternative is to implement a finer level of granularity -- a
lock-per-process table entry vs. one table-level lock. With a
lock on each process table entry, multiple threads can manipulate
different process structures at the same time, which provides
concurrency. The downside is that such an implementation is more
complex, increases the chances of deadlock situations, and results in
more general overhead because there are more locks to manage. In
general, the Solaris kernel implements relatively fine-grained
locking whenever possible. The wealth of talent and experience in
building SMP kernels that exists in Solaris kernel engineering goes
a long way in addressing the downside trade-offs to fine-grained
locking, as you will soon see.
Solaris implements two types of mutex locks: spin locks and adaptive
locks. We already discussed spin locks, which spin in a tight loop
if a desired lock is being held when a thread attempts to acquire
the lock. Adaptive locks are the most common type of lock, and
are designed to dynamically either spin or block when a lock is
being held, depending on the state of the holder. We already
discussed the trade-offs of spinning versus blocking. Implementing a
locking scheme that only does one or the other can severely impact
scalability and performance. It is much better to use an adaptive
locking scheme, which is precisely what we do.
The mechanics of adaptive locks are fairly straightforward: when a
thread attempts to acquire a lock, and the lock is being held, the
kernel examines the state of the thread that holds the lock. If the
lock holder (owner) is running on a processor, the thread attempting
to get the lock will spin. If the thread holding the lock is not
running, the thread attempting to get the lock will block. This
policy works quite well because the code is such that mutex hold
times are very short (the goal being to minimize the
amount of code to be executed while holding a lock); so if a thread
is holding a lock and running, the lock will likely be freed very
soon, probably in less time than it takes to context switch off and
on again -- thus, it's worth spinning. On the other hand, if a lock
holder is not running, then we know there's at least one context
switch involved before the holder will release the lock (getting the
holder back on a processor to run). Therefore, it makes sense to
simply block and free up the processor to do something else. The
kernel will place the blocking thread on a turnstile and wake up the
thread when the lock is freed by the holder.
The other distinction between adaptive locks and spin locks has to
do with interrupts, the dispatcher, and context switching.
High-level interrupts can interrupt the dispatcher (the code that
selects threads for scheduling and does context switches), which
means we cannot do context switches in a high-level interrupt
context. The dispatcher code required to do the context switch cannot execute when a processor is running at a high priority interrupt
level (PIL). Adaptive locks can block, and blocking means context
switching, which means that only spin locks can be used in high-level
interrupt handlers. Also, spin locks can raise the interrupt level
of the processor when the lock is acquired.
The block of pseudo code below illustrates the general mechanics of
mutex locks. A lock is declared in the code -- in this case, it is
embedded in the data structure it is designed to protect. Once
declared, the lock is initialized with the kernel mutex_init()
function. Any subsequent reference to the kdata structure requires
that the klock mutex be acquired with mutex_enter(). Once the work
is done, the lock is freed with mutex_exit(). The lock type, spin or adaptive, is determined in the mutex_init() code by the kernel.
Assuming an adaptive mutex in this example, any kernel threads that
make a mutex_enter() call on klock will either block or spin,
depending on the state of the kernel thread that owns klock when the
mutex_enter() is called.
struct kdata {
mutex_lock klock;
long counter;
int data[DATASIZE];
} mydata;
.
.
mutex_init(mydata.klock);
mutex_enter(mydata.klock);
counter = value;
myfield = data[index];
mutex_exit(mydata.klock);
.
.
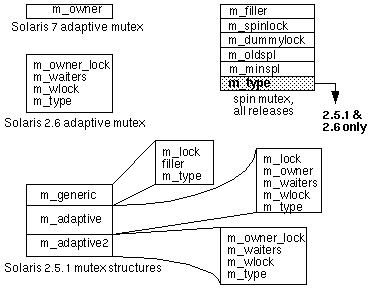
Figure 3. Two mutex lock structures
|
Figure 3 shows the structure of the two different types of mutex locks, distinguishing the differences in implementations between Solaris
7, 2.6, and 2.5.1.
The adaptive mutex in Solaris 7 contains only one field, m_owner, which
reflects the kernel thread ID of the owner while the lock is being held. This field plays a double role, in that it also serves as the actual lock; successful
lock acquisition for a thread means it has its kthread ID is set in the target
lock. Any thread attempting to get the lock while it's being held is termed a waiter, and the low-order bit (bit 0) of m_owner is set to reflect that a thread is waiting for the lock.
Solaris 2.6 defines several fields in the adaptive mutex structure. m_owner_lock reflects the kthread ID of the owner and serves as the actual lock as well. m_waiters is the ID of the turnstile if threads are sleeping (blocked) on the lock. m_wlock synchronizes access to the m_waiters field when a thread is being placed on a turnstile, and m_type reflects the lock type (adaptive).
Note that the spin lock in 2.5.1 and 2.6 also includes a type field,
where Solaris 7 does not. Solaris 2.5.1 declares a large mutex
structure as a C language union, defining several different possible
instantiations of the mutex, which get resolved when the kernel is
built (compiled -- C language unions are resolved at compile time).
I don't want to get mired in subtle differences that would not
add real value to our discussion, but at the same time I want to be sure to point out relevant
differences in implementations. The 2.5.1 diagram serves two
purposes: it illustrates the disparity in the way the mutex
structures are defined across releases, and it also shows how the fields
are conceptually very similar (identical in some cases) to those in
2.6. For spin locks, the lock structure is virtually identical
across all three releases.
In addition to the difference in mutex structure definitions, the
mutex code in 2.5.1 also defines a mutex operation's vector array.
Each element in the array is a mutex_ops structure -- one structure
for each type of mutex defined in 2.5.1. The array is indexed based
on the lock type and the function call. The design is such that
there are specific functions to handle lock operations for each of
the different types of mutex locks. Solaris 2.5.1 defines the required
adaptive and spin locks, as well as variations on these locks types;
note the adaptive2 lock type in Figure 3. Common
entry points into the mutex code pass control to the lock-specific
functions by switching through the operation's array based on the
lock type and function offset. This design is not implemented in either 2.6
or 7.
The spin mutex, as we discussed earlier, is used at high interrupt
levels, where context switching is not allowed. The m_minspl field
stores the priority level of the interrupt handler when the lock is
initialized, and m_oldspl gets set to the priority level the
processor was running at when the lock code is called. When we enter
an interrupt handler, the PIL of the processor handling the
interrupt may be elevated. Consequently, we need to save the PIL the
processor was running so it can be restored when the interrupt
handler exits. The m_spinlock field is the actual mutex lock.
Kernel mutex locks are implemented throughout the operating system.
There are literally hundreds, which accounts in part for the
excellent scalability Solaris provides on MP platforms. Each module
implementing one or more mutex locks calls into a common set of
mutex functions. All locks must first be initialized using the
mutex_init() function, where the lock type is determined, based on
an argument passed in the mutex_init() call. The most common type
passed into mutex_init() is MUTEX_DEFAULT, which results in the init
code determining what type of lock should be used -- adaptive or
spin. It is possible for a caller of mutex_init() to be specific
about a lock type (for example, MUTEX_SPIN), but that is rarely done. If the
init code is called from a device driver, or any kernel module that
registers and generates interrupts, an interrupt block cookie is
added to the argument list. The mutex_init() code checks the
argument list for an interrupt block cookie, which in abstraction
is used by device drivers when they set their interrupt
vector and parameters. If mutex_init() is being called from a device
driver to initialize a mutex to be used in a high-level interrupt
handler, the lock type is set to spin. Otherwise, an adaptive lock
is initialized.
The test is the interrupt level in the passed interrupt block.
Levels above 10 (on SPARC systems) are considered high-level
interrupts and require spin locks. The init code will clear
most of the fields in the mutex lock structure as appropriate for
the lock type and Solaris release (for example, 2.6 adaptive locks have more
lock structure fields to initialize to a zero state). The
m_dummylock field in spin locks is set to all ones (0xff) in all
releases (you'll see why in a minute).
The primary mutex functions called, aside from mutex_init(), which
is called only one time for each lock at initialization time, are:
mutex_enter() to get a lock, and mutex_exit() to release it. mutex_enter() assumes an available, adaptive lock. If the lock is held, or is a spin lock, mutex_vector_enter() is entered to reconcile what should happen. This is a performance optimization.
mutex_enter() is implemented in assembly code. By designing the entry point for a simple case (adaptive lock, not held), the amount of
code that gets executed to acquire a lock when those conditions are
true is minimal. The test for a lock held or spin lock is very fast
as well. This is where the m_dummylock field comes into play.
mutex_enter() executes a compare-and-swap instruction on the first
byte of the mutex, testing for a zero value.
On a spin lock, the m_dummylock field gets tested, due to its
positioning in the data structure and the endian nature of SPARC
processors. Because m_dummylock is always set (it is set to all ones in mutex_init()), the test will fail for spin locks. The test will also fail for a held adaptive lock because such a lock will have a
nonzero value in the byte field tested against.
If the two conditions are not true, we enter the mutex_vector_enter() function to sort things out. For spin locks,
the m_oldspl field is set based on the current PIL of the processor, and the lock is tested. If it's not being held, the lock is set
(m_spinlock), and the code returns to the caller. A held lock forces the caller into a spin loop, where a loop counter is incremented
(for statistical purposes), and the code checks if the lock is still
held in each pass through the loop. Once the lock is freed, the code
breaks out of the loop, grabs the lock, and returns to the caller.
Adaptive locks require a little more work. When the adaptive code
path is entered, the cpu_sysinfo.mutex_adenters (adaptive lock
enters) field is incremented, which is reflected in the smtx column
in mpstat(1M); it is worth noting that this value does not reflect
spin locks. If the adaptive lock is not being held, the lock is set
by setting the kernel thread ID in the m_owner field of the mutex.
Then the code returns. A held lock requires determining whether or
not the lock owner is running, which is done by looping through the
CPU structures and testing the lock m_owner against the cpu_thread
field of the CPU structure (cpu_thread contains the kernel thread ID
of the thread currently executing on the CPU). A match indicates the
holder is running, which means the adaptive lock will spin. No match
means the owner is not running, and the caller must then block. The
kernel turnstile code is entered to locate or acquire a turnstile
and place the kernel thread on a sleep queue associated with the
turnstile.
The turnstile placement happens in two phases. After it is
determined that the lock holder is not running, a turnstile call is
made to look up the turnstile, and the waiters bit is set in m_owner
(Solaris 7). In 2.5.1 and 2.6, the m_waiters field in the mutex is
tested. If there are no waiters, a turnstile allocation function is
called to get a turnstile. If waiters were already sleeping on
the lock, a turnstile already exists, so a function is called to
fetch the pointer to the existing turnstile. In all cases, we now
have a turnstile for the lock and can proceed.
Another test is made to see if the owner is running. If the answer
is yes, we release the turnstile and grab the lock; otherwise, place the
kernel thread on a turnstile (sleep queue) and change the thread's
state to sleep. It is here that the kernel addresses a potential
problem known as priority inversion.
Priority inversion describes a scenario where a higher-priority
thread is unable to run due to a lower-priority thread holding a
resource it needs (for example, a lock). The Solaris kernel addresses the
priority inversion problem in its turnstile implementation,
providing a priority inheritance mechanism, where the higher-priority thread can will its priority to the lower-priority thread
holding the resource it requires. The benefactor of the inheritance,
the thread holding the resource, will now have a higher scheduling
priority, and thus get scheduled to run sooner so it can finish its
work and release the resource, at which point the thread is given
its original priority back.
That effectively concludes the sequence of events in
mutex_vector_enter() (and the equivalent functions in 2.5.1).
When we drop out of that code, either the caller ended up with the lock
it was attempting to acquire, or the calling thread is on a
turnstile sleep queue associated with the lock. Once the turnstile
code has completed, the kernel swtch() function is called, which is
an entry point into the kernel dispatcher.
When a thread is done working in a lock-protected data area, it
calls the mutex_exit() code to release the lock. The entry point is
implemented in assembly language, and handles the simple case of
adaptive lock with no waiters. With no threads waiting for the lock,
it's a simple matter of clearing the lock fields (m_owner or
m_owner_lock, depending on the OS release) and returning. In Solaris 2.5.1, mutex_exit() calls mutex_vector_exit() for spin locks or adaptive locks with waiters, which transfers control to either
mutex_spin_exit() or mutex_adaptive_release(), depending on the lock type. In Solaris 2.6, it's the same basic flow, only
mutex_vector_exit() deals with releasing spin locks, and
mutex_adaptive_release() deals with adaptive locks with waiters. In
Solaris 7, mutex_vector_exit() handles the all cases if the code
drops out of the mutex_enter() assembly function.
Function name disparities between releases notwithstanding, along
with differences in the turnstile structures and code, the work
that needs to get done is the same. In the case of a spin lock, the
lock field is cleared and the processor is returned back to the PIL
level it was running at prior to entering the lock code. For
adaptive locks, a waiter must be selected from the turnstile (if
there is more than one), have its state changed from sleeping to
runable, and be placed on a dispatch queue so it can execute and get
the lock. If the thread releasing the lock was the benefactor of
priority inheritance, meaning that it had its priority improved when
a calling thread with a better priority was not able to get the
lock, the thread releasing the lock will have its priority reset to
what it was prior to the inheritance. In Solaris 2.5.1 and 2.6, the
thread with the highest dispatch priority is selected for wakeup. If
there are multiple threads at the same (highest) priority, the
thread that has been sleeping longest is selected.
Solaris 7 behaves a little differently. When an adaptive lock is
freed, the code clears the waiters' bits in m_owner() and calls the
turnstile function to wake up all the waiters, not just one waiter, as is
the case in 2.5.1 and 2.6. Readers familiar with operating systems'
sleep/wakeup mechanisms have likely heard of a particular behavior
known as the "thundering herd" problem, which is intended to
describe a situation where many threads that have been blocking for
the same resource are all woken up at the same time and make a mad
dash for the resource (a mutex in this case).
System behavior tends to go from a relatively small run queue to a
large run queue. This occurs because all the threads sleeping on the
resource are awakened when the resource is freed. They're
all made runable and appear on the run queue at the same time.
The CPU utilization goes very high until one of the threads gets the
resource, at which point the other threads must be put back on the
sleep queue. The run queue will normalize, and CPU utilization will
flatten out. This is a generic problem that can occur on any
operating system.
The wakeup mechanism used when mutex_vector_exit() is called in
Solaris 7 might seem like an open invitation to thundering herds,
but in practice it doesn't turn out to be a problem. First and
foremost, the blocking case for threads waiting for a mutex is rare
-- most of the time the threads will spin. If a blocking situation
does arise, it typically does not reach a point where there are very
many threads blocked on the mutex. One of the characteristics of the
thundering herd problem is resource contention resulting in a number of
sleeping threads. The kernel code segments that implement mutex
locks are short and fast, so locks are not held for very
long. Code that requires longer lock hold times use a reader/writer
write lock, which provides mutual exclusion semantics with a
selective wakeup algorithm.
The rationale for changing the wakeup behavior in Solaris 7 resulted from exhaustive testing and a thorough examination of all possible
options. When a lock
is being freed with waiters, there are essentially three options.
The first option involves choosing a waiting thread from the
turnstile and giving it lock ownership before waking it, which is
known as direct handoff of ownership. This approach has a huge
drawback when there is even moderate lock contention, in that it
defeats the logic of adaptive locks. If direct handoff is used,
there is a window between the time the thread was given ownership
and the time the new owner is running on a processor (it must go
through a state change and get context switched on). If, during that
window, other threads come along and try to get the lock, they'll
enter the blocking code path because the "is the lock owner
running?" test will fail. A lock with some contention will result in
most threads taking the blocking path instead of the spin path.
The second option, free the lock and wake one waiter, (what 2.5.1
and 2.6 do), has a much more subtle complication, which is due to
maintaining the integrity of the waiter's bit when there is more
than one waiter. It has to do with the potential latency between the
time a lock with multiple waiters is released and a new owner is
selected (woken up) but not yet executed. The state of things is
such that there are multiple waiters on the lock, but no owner; they
no longer have anyone to will their priority to. This means that if
another thread grabs the lock, it has to check in mutex_enter() to
determine whether to start inheriting from the blocking chain for
that lock.
The third option, wake up all the waiters, (what we do in Solaris
7), has the benefit of not having to preserve the waiter's bit.
Because we're waking all the waiters, it can simply be cleared in
one operation. And, as we discussed previously, it has been determined
through extensive testing that the blocking case is relatively rare,
which results in this behavior working quite well.
Statistical information on mutex locks is readily available, but not
in 2.5.1. Releases 2.6 and 7 include a lockstat(1M) utility, which
collects and displays information on mutex and reader/writer lock
activity. lockstat(1M) is implemented with a pseudo device,
/dev/lockstat, and associated pseudo device driver. The interfaces
are not public, meaning there are no open, read, write, etc., calls
into the lockstat driver. The lockstat(1M) manual page provides
information on how to use lockstat(1M) and interpret the displayed
data. There are several options available on which events to watch,
which data collection methods (for example, statistics, stack tracing, etc.) to
use, and on how to display data, so go through the man page
carefully.
That's a wrap for this month. Next month, we'll take a look at
reader/writer locks.


|
 |
About the author
Jim
Mauro is currently an area technology manager for Sun Microsystems
in the Northeast, focusing on server systems, clusters, and high
availability. He has a total of 18 years of industry experience,
working in educational services (he developed and delivered courses on
Unix internals and administration) and software consulting.
|
Advertisement: Support SunWorld, click here!
|
 |
Resources and Related Links |
| |
- Scalable Parallel Computing: Technology, Architecture, and Programming, Kai Hwang and Zhiwei Xu (WCB McGraw-Hill, 1998):
http://www.amazon.com/exec/obidos/ASIN/0070317984/sunworldonlineA - "Turnstiles and priority inheritance," (Inside Solaris, August 1999):
http://www.sunworld.com/sunworldonline/swol-08-1999/swol-08-insidesolaris.html - The Magic Garden Explained: The Internals of Unix System V Release 4, Berny Goodheart and James Cox (Prentice Hall, 1994 ):
http://www1.fatbrain.com/asp/bookinfo/bookinfo.asp?theisbn=0130981389 - Unix Internals: The New Frontiers, Uresh Vahalia (Prentice Hall, 1996):
http://www.amazon.com/exec/obidos/ASIN/0131019082/sunworldonlineA Additional SunWorld resources
| |
|
Tell Us What You Thought of This Story
|
| |
| |
If you have technical problems with this magazine, contact
webmaster@sunworld.com
URL: http://www.sunworld.com/swol-09-1999/swol-09-insidesolaris.html
Last modified: