Getting to know the Solaris filesystem, Part 3
How is file data cached?
July 1999
|
|
Getting to know the Solaris filesystem, Part 3How is file data cached?
|
July 1999 |
One of the most important features of a filesystem is its ability to cache file data. Ironically, however, the filesystem cache isn't implemented in the filesystem. In Solaris, the filesystem cache is implemented in the virtual memory system. In Part 3 of this series on the Solaris filesystem, Richard explains how Solaris file caching works and explores the interactions between the filesystem cache and the virtual memory system. (4,000 words)
|
Mail this article to a friend |
read system call
into the operating system. The filesystem must then find the corresponding
disk block for the file (by looking up the block number in the direct/indirect blocks
for that file) and request that block from the I/O system. The
I/O system retrieves the block from disk the first time, and
subsequential reads are satisfied by reading the disk block from the
block buffer cache. Note that even though the disk block is cached
in memory, we have to invoke the filesystem and look up the physical
block number for every cached read because this is a physical block
cache.
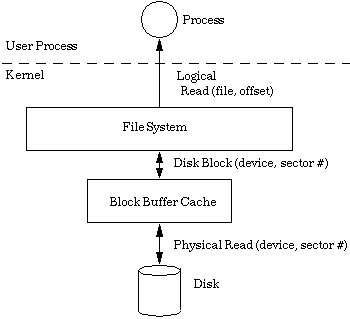
Figure 1. The old buffer cache |
The old buffer cache is typically sized statically by a kernel configuration parameter. Changing the size of the buffer cache requires a kernel rebuild and a reboot.
The Solaris page cache
Solaris has a new method of caching filesystem data, known as the
page cache. The page cache was developed at Sun as part of the
virtual memory rewrite in SunOS 4 in 1985, and is used by System V
Release 4 Unix. Page cache derivatives are now also used in Linux
and Windows NT. The page cache has two major differences. First,
it's dynamically sized and can use all memory that isn't being used
by applications. Second, it caches file blocks rather than disk
blocks. The key difference is that the page cache is a virtual file
cache, rather than a physical block cache. This allows the operating
system to retrieve file data by simply looking up the file reference
and seek offset, rather than having to invoke the filesystem to
look up the physical disk block number corresponding to the file and
retrieving that block from the physical block cache. This is far
more efficient.
Figure 2 shows the new page cache. When a Solaris process reads a
file the first time, file data is read from disk though the file
system into memory in page-size chunks and returned to the user. The
next time the same segment of file data is read it can be retrieved
directly from the page cache, without having to do a
logical-to-physical lookup though the filesystem. The old buffer cache is
still used in Solaris, but only for filesystem data that is only
known by physical block numbers. This data only consists of metadata
items -- direct/indirect blocks and inodes. All file data is
cached though the page cache.
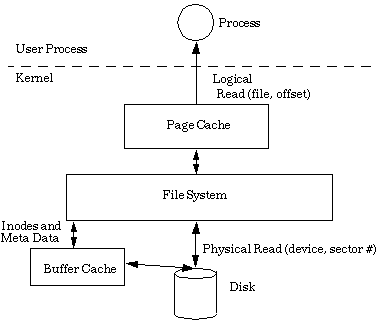
Figure 2. Filesystem caching via the page cache |
The diagram in Figure 2 is somewhat simplified. The filesystem is still involved in the page cache lookup, but the amount of work the filesystem needs to do is dramatically simplified. The page cache is implemented in the virtual memory system. In fact, the virtual memory system is architected around the page cache principle, and each page of the physical memory is identified the same way, by file and offset. Pages associated with files point to regular files, while pages of memory associated with the private memory space of processes point to the swap device. We aren't going to go into too much detail about the Solaris virtual memory system in this article. A more detailed description of the Solaris memory system can be found in my Solaris memory white paper at http://www.sun.com/sun-on-net/performance/vmsizing.pdf. The important thing to remember is that file cache is just like process memory. And, as we will see, file caching shares the same paging dynamics as the rest of the memory system.
The old buffer cache in Solaris
The old buffer cache is used in Solaris to cache inodes and
file metadata, and is now also dynamically sized. In old versions
of Unix, the buffer cache was fixed in size by the nbuf kernel
parameter, which specified the number of 512-byte buffers. We now
allow the buffer cache to grow by nbuf as needed, until it reaches a ceiling
specified by the bufhwm kernel parameter. By default, the buffer
cache is allowed to grow until it uses two percent of physical
memory. We can look at the upper limit for the buffer cache using
the sysdef command.
# sysdef
*
* Tunable parameters
*
7757824 maximum memory allowed in buffer cache (bufhwm)
5930 maximum number of processes (v.v_proc)
99 maximum global priority in sys class (MAXCLSYSPRI)
5925 maximum processes per user id (v.v_maxup)
30 auto update time limit in seconds (NAUTOUP)
25 page stealing low water mark (GPGSLO)
5 fsflush run rate (FSFLUSHR)
25 minimum resident memory for avoiding deadlock (MINARMEM)
25 minimum swappable memory for avoiding deadlock (MINASMEM)
Now that we only keep inodes and metadata in the buffer cache, we
don't need a very large buffer. In fact, we only need 300 bytes per
inode, and about 1 MB per 2 GB of files that
we expect to be accessed concurrently. (Note that this rule of thumb
is for the Unix filesystem (UFS).) For example, if we have a database
system with 100 files totaling 100 GB of storage space and we estimate that we'll
access only 50 MB of those files at the same time, then at
most we would need 3 KB (100 x 300 bytes = 3 KB) for the inodes, and
about 25 MB (50 / 2 x 1 MB = 25 MB) for the metadata (direct
and indirect blocks). On a system with 5 GB of physical memory, the
defaults for bufhwm would provide us with a bufhwm
of 102 MB, which would be more than sufficient for the buffer cache. We could
limit bufhwm to 30 MB to save memory. This can be done
by setting the bufhwm parameter in the /etc/system file. The units
for bufhwm are in kilobytes. To set bufhwm smaller for this example,
we would put the following line into /etc/system.
* * Limit size of bufhwm * set bufhwm=30000
You can monitor the old buffer cache hit statistics using sar -b.
The statistics for the buffer cache show the number of logical reads
and writes into the buffer cache, the number of physical reads and
writes out of the buffer cache, and the read/write hit ratios.
# sar -b 3 333 SunOS zangief 5.7 Generic sun4u 06/27/99 22:01:51 bread/s lread/s %rcache bwrit/s lwrit/s %wcache pread/s pwrit/s 22:01:54 0 7118 100 0 0 100 0 0 22:01:57 0 7863 100 0 0 100 0 0 22:02:00 0 7931 100 0 0 100 0 0 22:02:03 0 7736 100 0 0 100 0 0 22:02:06 0 7643 100 0 0 100 0 0 22:02:09 0 7165 100 0 0 100 0 0 22:02:12 0 6306 100 8 25 68 0 0 22:02:15 0 8152 100 0 0 100 0 0 22:02:18 0 7893 100 0 0 100 0 0
On this system, we can see that the buffer cache is caching 100 percent of the reads, and the number of writes are small. This measurement was taken on a machine with 100 GB of files being read in a random pattern. You should try to obtain a read cache hit ratio of 100 percent on systems with few, but very large files (e.g., database systems), and a hit ratio of 90 percent or better for systems with many files.
|
|
|
|
|
The page cache and the virtual memory system
The virtual memory system is implemented around the page cache, and
the filesystem makes use of this facility to cache files. This
means that to understand filesystem caching behavior, we need to
look at how the virtual memory system implements the page cache. The
virtual memory system divides physical memory into chunks known as
pages; on UltraSPARC systems each page is 8 KB. To read data
from a file into memory, the virtual memory system reads in one page
at a time. The operation of reading in file pages this way is known
as paging in a file. The page-in operation is initiated in the
virtual memory system, which then requests the filesystem for that
file to page in a page from storage to memory. Every time we read in
data from disk to memory we cause paging to occur, which is what we
see when we look at the virtual memory statistics. For example,
a file read will be reflected in vmstat as page ins.
# ./rreadtest testfile& # vmstat procs memory page disk faults cpu r b w swap free re mf pi po fr de sr s0 -- -- -- in sy cs us sy id 0 0 0 50436 2064 5 0 81 0 0 0 0 15 0 0 0 168 361 69 1 25 74 0 0 0 50508 1336 14 0 222 0 0 0 0 35 0 0 0 210 902 130 2 51 47 0 0 0 50508 648 10 0 177 0 0 0 0 27 0 0 0 168 850 121 1 60 39 0 0 0 50508 584 29 57 88 109 0 0 6 14 0 0 0 108 5284 120 7 72 20 0 0 0 50508 484 0 50 249 96 0 0 18 33 0 0 0 199 542 124 0 50 50 0 0 0 50508 492 0 41 260 70 0 0 56 34 0 0 0 209 649 128 1 49 50 0 0 0 50508 472 0 58 253 116 0 0 45 33 0 0 0 198 566 122 1 46 53
In our example, we can see that by starting a program that does
random reads of a file we cause a number of page ins to occur,
as is indicated by the numbers in the pi column of
vmstat. Note that the free memory column in vmstat
has dropped to a very low value. In
fact, the amount of free memory is almost zero. Have you
noticed that when you boot your machine there's a lot of free
memory, and as the machine is used, memory continues to fall to
zero and then just hangs there? This is because the filesystem
consumes a page of physical memory every time it pages in a page-size
chunk of a file. It's normal -- the filesystem is using all
available memory to cache the reads and writes to each file. Memory
is put back on the free list by the page scanner, which looks for
memory pages that haven't been used recently. The page scanner runs
when memory falls to a system parameter known as lotsfree. In this
example, we can see that the page scanner is scanning about 50 pages
per second to replace the memory used by the filesystem.
There is no equivalent parameter to bufhwm for the
page cache. The page cache simply grows to consume all available
memory, which includes all process memory that isn't being used by
applications. The rate at which the system pages and the rate at
which the page scanner runs is proportional to the rate at which
the filesystem is reading or writing pages to disk. On large systems, this
means that you should expect to see large paging values. Consider a
system that is reading 10 MBps though the filesystem; this translates
to 1,280 page ins per second. The page scanner must scan enough memory to be able to
free 1,280 pages per second. The page scanner must actually scan
faster than 1,280 pages per second because not all memory the page
scanner comes across will be eligible for freeing. (The page scanner
only frees memory that hasn't been recently used.) If the page
scanner only finds one out of three pages eligible for freeing,
it will actually need to run at 3,840 pages per second. Don't worry about
high scan rates. If you're using the filesystem heavily, it's
normal. There are many myths about high scan rates indicating a
shortage of memory. You can now see that high scan rates
are normal in many circumstances.
filesystem paging tricks
It should be noted that some filesystems try to reduce the amount
of memory pressure by doing two things: enabling free behind with
sequential access and freeing pages when free memory falls to
lotsfree. As mentioned in last month's article,
free behind is invoked on UFS when a file is accessed
sequentially so that we don't pollute the cache when we do a
sequential scan though a large file. This means that when we
create or sequentially read a file we don't see high scan rates.
There are also checks in some filesystems to limit the filesystem's use of
the page cache when memory falls to lotsfree. There
is an additional parameter that is used by the UFS filesystem,
pages_before_pager. This parameter reflects the amount of memory
above the point where the page scanner will start. By default this
is 200 pages. This means that when memory falls to 1.6 MB (on
UltraSPARC) above lotsfree, the filesystems start throttling back
the use of the page cache. To be more specific, when memory falls to
lotsfree + pages_before_pager, Solaris filesystems do the following:
Is all that paging bad for my system?
Although I stated earlier that it may be normal to have high paging
and scan rates, it is likely that the page scanner will be putting
too much pressure on your applications' private process memory. If
we scan at a rate of several hundred pages per second or more,
the amount of time the page scanner takes to check if a page has
been accessed reduces to a few seconds. This means that any pages
that haven't been used in the last few seconds will be taken by the
page scanner when you're using the filesystem. This can have a
very negative effect on application performance. We introduced
priority paging to address this problem.
If you've ever noticed that your system feels slow while filesystem I/O is going on, this is because your applications are being paged in and out as a direct result of the filesystem activity. For example, consider an OLTP (online transaction processing) application that makes heavy use of the filesystem. The database is generating filesystem I/O, making the page scanner actively steal pages from the system. The user of the OLTP application has paused to read the contents of a screen from the last transaction for 15 seconds. During this time, the page scanner has found that those pages associated with the user application have not been referenced and makes them available for stealing. The pages are then stolen. When the user types the next keystroke, he is forced to wait until his application is paged back in -- usually several seconds. So, the user is forced to wait for an application to page in from the swap device, even though the system has sufficient memory to keep all the application in physical memory!
The priority paging algorithm effectively places a boundary around the file cache, so that filesystem I/O does not cause unnecessary paging of applications. It does this by prioritizing the different types of pages in the page cache, in order of importance:
When the dynamic page cache grows to the point where free memory falls to almost zero, the page scanner wakes up and begins scanning. Even though there is sufficient memory in the system, the scanner will only steal pages associated with regular files. The filesystem effectively pages against itself, rather than against everything else on the system.
Should there be a real memory shortage where there is insufficient
memory for the applications and kernel, the scanner is again allowed
to steal pages from the applications. By default, priority paging is
disabled. It is likely to be enabled by default in a Solaris release
subsequent to Solaris 7. To use priority paging, you will need
either Solaris 7, Solaris 2.6 with kernel patch 105181-13, or
Solaris 2.5.1 with 103640-25 or higher. To enable priority paging,
set the following in /etc/system:
* * Enable Priority Paging * set priority_paging=1
Setting priority_paging=1 in /etc/system causes a new memory
tunable, cachefree, to be set to two times the old paging high-water mark,
lotsfree. The cachefree memory tunable is a new parameter, which
scales with minfree, desfree, and lotsfree.
(See the complete discussion of priority paging at http://www.sun.com/sun-on-net/performance/priority_paging.html.)
Priority paging distinguishes between executable files and regular files by recording whether or not they are mapped into an address space with execute permissions. This means that regular files with the execute bit that are mapped into an address space with the memory map system call are treated as executables, and care should be taken to ensure that data files that are being memory mapped do not have the execute bit set.
Under Solaris 7, there is an extended set of paging counters that
allow us to see what type of paging is occurring. We can now see the
difference between paging caused by an application memory shortage
and paging though the filesystem. The paging counters are visible
under Solaris 7 with the memstat command. The output from the
memstat command is similar to that of vmstat, but with extra fields
to break down the different types of paging. In addition to the
regular paging counters (sr,po,pi,fr), the memstat command shows the
three types of paging broken out as executable, application, and
file. The memstat fields are listed in the table below.
| Column | Description |
| pi | Total page ins per second |
| po | Total page outs per second |
| fr | Total page frees per second |
| sr | Page scan rate in pages per second |
| epi | Executable page ins per second |
| epf | Executable pages freed per second |
| api | Application (anonymous) page ins per second from the swap device |
| apo | Application (anonymous) page outs per second to the swap device |
| apf | Application pages freed per second |
| fpi | File page ins per second |
| fpo | File page outs per second |
| fpf | File page frees per second |
If we use the memstat command we can now see that as we randomly
read our test file, the scanner scans several hundred pages per
second though memory and causes executable pages to be freed.
Application pages are also paged out to the swap device as they are
stolen. On a system with plenty of memory, this isn't the desired
mode of operation. Enabling priority paging will stop this from
happening when there is sufficient memory.
# ./readtest testfile& # memstat 3 memory ------- paging ------- -executable- -anonymous- --filesys - -- cpu --- free re mf pi po fr de sr epi epo epf api apo apf fpi fpo fpf us sy wt id 2080 1 0 749 512 821 0 264 0 0 269 0 512 549 749 0 2 1 7 92 0 1912 0 0 762 384 709 0 237 0 0 290 0 384 418 762 0 0 1 4 94 0 1768 0 0 738 426 610 0 1235 0 0 133 0 426 434 738 0 42 4 14 82 0 1920 0 2 781 469 821 0 479 0 0 218 0 469 525 781 0 77 24 54 22 0 2048 0 0 754 514 786 0 195 0 0 152 0 512 597 754 2 37 1 8 91 0 2024 0 0 741 600 850 0 228 0 0 101 0 597 693 741 2 56 1 8 91 0 2064 0 1 757 426 589 0 143 0 0 72 8 426 498 749 0 18 1 7 92 0
If we enable priority paging, we can observe the difference using
the memstat command.
# ./readtest testfile& # memstat 3 memory --------- paging -------- -executable - anonymous - - filesys -- -cpu --- free re mf pi po fr de sr epi epo epf api apo apf fpi fpo fpf us sy wt id 3616 6 0 760 0 752 0 673 0 0 0 0 0 0 760 0 752 2 3 95 0 3328 2 198 816 0 925 0 1265 0 0 0 0 0 0 816 0 925 2 10 88 0 3656 4 195 765 0 792 0 263 0 0 0 2 0 0 762 0 792 7 11 83 0 3712 4 0 757 0 792 0 186 0 0 0 0 0 0 757 0 792 1 9 91 0 3704 3 0 770 0 789 0 203 0 0 0 0 0 0 770 0 789 0 5 95 0 3704 4 0 757 0 805 0 205 0 0 0 0 0 0 757 0 805 2 6 92 0 3704 4 0 778 0 805 0 266 0 0 0 0 0 0 778 0 805 1 6 93 0
With priority paging enabled, we can see different behaviors of the
virtual memory system. Using the same test program, random reads on
the filesystem again cause the system to page, and the scanner is
actively involved in managing the pages. But now the scanner is only
freeing file pages. We can clearly see from the rows of zeros in the
executable and anonymous memory columns that the scanner chooses
file pages first. The activity is in the fpi and fpf columns -- this
means that file pages are read in, and an equal number are freed by
the page scanner to make room for more reads.
Paging parameters that effect filesystem performance
When priority paging is enabled, you will notice that the filesystem
scan rate is higher. This is because the page scanner must
skip over process private memory and executables. It needs to scan
more pages before it finds file pages that it can steal. High scan
rates are always found on systems that make heavy use of the filesystem
and shouldn't be used as a factor for determining memory
shortage. If you have Solaris 7, the memstat command will
reveal whether you're paging to the swap device -- if so, the system
is short of memory.
If you have high filesystem activity, you will find that the
scanner parameters are insufficient and will limit filesystem
performance. To compensate for this, you will need to set some of
the scanner parameters to allow the scanner to scan at a high enough
rate to keep up with the filesystem. By default, the scanner is
limited by the fastscan parameter, which reflects the number of
pages per second that the scanner can scan. It defaults to scan a
quarter of memory every second and is limited to 64 MBps. The scanner
runs at half of fastscan when memory is at
lotsfree, which limits it to 32 MBps. If only one in
three physical memory pages are file pages, the scanner will
only be able to put 11 MB (32 / 3 = 11 MB) of memory on the free
list, thus limiting filesystem throughput.
You will need to increase fastscan so that the page scanner works
faster. I recommend setting it to one quarter of memory with an
upper limit of 1 GB per second. This translates to an upper limit of
131072 for the fastscan parameter. The handspreadpages parameter
should also be increased with fastscan to the same value.
Another limiting factor for the filesystem is maxpgio. The maxpgio
parameter is the maximum amount of pages the page scanner can push.
It can also limit the amount of filesystem pages that are pushed.
This in turn limits the write performance of the filesystem. If
your system has sufficient memory, I recommend setting maxpgio to
something large -- 65536. On E10000 systems this is the default for
maxpgio.
For example, on a 4-GB machine, one quarter of memory is 1 GB, so we
would set fastscan to 131072. Our parameters for this machine would
be:
* * Parameters to allow better filesystem throughput * set fastscan=131072 set handspreadpages=131072 set maxpgio=65536
We've now seen how Solaris uses a virtual file cache, the page
cache, to integrate filesystem caching with the memory system. In
future articles we will explore some of the filesystem-specific
caching options that can be used to relieve some of the memory
pressure caused by filesystem I/O.
![]()
|
|
Resources
About the author
![]() Richard McDougall is an established engineer in the Enterprise Engineering Group
at Sun Microsystems where he focuses on large system performance and
operating system architecture. He has more than 12 years of performance
tuning, application/kernel development, and capacity planning experience
on many different flavors of Unix. Richard has authored a wide range of
papers and tools for measurement, monitoring, tracing and sizing of Unix systems including the memory sizing methodology for Sun, the set of tools known as MemTool allowing fine-grained instrumentation of memory
for Solaris, the recent priority paging memory algorithms in Solaris
and
Richard McDougall is an established engineer in the Enterprise Engineering Group
at Sun Microsystems where he focuses on large system performance and
operating system architecture. He has more than 12 years of performance
tuning, application/kernel development, and capacity planning experience
on many different flavors of Unix. Richard has authored a wide range of
papers and tools for measurement, monitoring, tracing and sizing of Unix systems including the memory sizing methodology for Sun, the set of tools known as MemTool allowing fine-grained instrumentation of memory
for Solaris, the recent priority paging memory algorithms in Solaris
and man of the unbundled Tools for Solaris. Richard is currently coauthoring with Jim Mauro the Sun Microsystems book, Solaris Architecture, which details Solaris architecture.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-07-1999/swol-07-filesystem3.html
Last modified: