The Solaris process model, Part 3Jim reveals the inner workings of the process, kernel thread, and lightweight process relationship, and begins a discussion of process scheduling classes, dispatch tables, and the kernel dispatcher |
October 1998 |
The multilayer thread model implemented in Solaris is a drastic departure from the traditional Unix process model. It's useful to have a solid understanding of the rationale behind this design, and how the key structures are related. Additionally, Solaris offers a redesign of the original Unix SVR4 scheduling model. Process/thread scheduling in Solaris involves the management of potentially thousands (or even tens of thousands) of executable threads in different scheduling classes. In this column, we'll further examine the process, kernel thread, and lightweight process (LWP) model, and venture forth into scheduling classes, priorities, and dispatch tables. (3,800 words)
|
Mail this article to a friend |
![]() n last month's column, we introduced several data
structures that make up the Solaris process model: the process
(proc) structure, which has the user area (uarea) embedded in it in
Solaris 2.X; the lightweight process (LWP); and the kernel thread
(kthread). A nonthreaded process running on a Solaris system will
have exactly one LWP and one kthread associated with it, even though
the code doesn't make an explicit thread_create(3T) or
pthread_create(3T) call. The kernel will create and link the
structures when the process is created. Additional LWPs and
kthreads will be created by the operating system for multithreaded
processes, either by explicit request in the
thread_create(3T)/pthread_create(3T) call, or through the use of the
thr_setconcurrency(3T) call. Additionally, user threads can be bound
to an LWP for their entire existence, using the appropriate flag in
the create library calls. Once a user thread is bound to an LWP,
that LWP will not be available for use by any other user threads.
n last month's column, we introduced several data
structures that make up the Solaris process model: the process
(proc) structure, which has the user area (uarea) embedded in it in
Solaris 2.X; the lightweight process (LWP); and the kernel thread
(kthread). A nonthreaded process running on a Solaris system will
have exactly one LWP and one kthread associated with it, even though
the code doesn't make an explicit thread_create(3T) or
pthread_create(3T) call. The kernel will create and link the
structures when the process is created. Additional LWPs and
kthreads will be created by the operating system for multithreaded
processes, either by explicit request in the
thread_create(3T)/pthread_create(3T) call, or through the use of the
thr_setconcurrency(3T) call. Additionally, user threads can be bound
to an LWP for their entire existence, using the appropriate flag in
the create library calls. Once a user thread is bound to an LWP,
that LWP will not be available for use by any other user threads.
The intention of the multilayer threads model is to decouple the scheduling and management of user threads from the kernel. User-level threads have their own priority scheme and are scheduled with a scheduling thread that is created by the library when a multithreaded program is compiled and executed. This way, multithreaded applications can have literally thousands of threads and not impose any significant load on the kernel. In fact, user threads aren't visible to the kernel; they're made visible when they're bound to an LWP, which has some state in the operating system. The user-level threads are made executable by the thread's scheduler mapping them onto an LWP, which is associated with a kernel thread for execution on a processor.
In Solaris, every LWP has a kernel thread, but not every kernel thread has an LWP. The lwp_create() code in the kernel will also invoke the kernel thread_create() routine (which creates kernel threads, not user threads), and set the pointers such that the newly created LWP and kernel thread are pointing to each other. This establishes a one-to-one relationship that will be maintained throughout the life of the LWP. As we said, not every kernel thread is associated with an LWP. Solaris is a multithreaded operating system, and as such creates kernel threads to perform operating system-related tasks.
Generally, multithreaded applications will have many more user threads than LWPs. An interface, thr_setconcurrency(3T), can be used to allow the application to advise the kernel as to how many concurrent threads can be run, such that the operating system will maintain a sufficient number of LWPs for thread execution. Extended coverage of what goes on in user thread land with respect to user thread priorities, scheduling of user threads, and LWP management will be covered in the next month or two. Our discussion this month will focus on the layers below user threads: the LWP and kthreads.
Now and again, in various books and whitepapers that discuss the Solaris threads model, LWPs and kthreads appear to be the same thing. I've seen the term LWP used where kthread would have been more technically accurate, and vice versa. The fact is that LWPs and kernel threads are distinctly different structures, each defined by its own header file (sys/klwp.h and sys/thread.h). However, in the context of user processes (as opposed to the kernel), it's harmless to think of them as one large entity, because there is, without exception, a one-to-one relationship between LWPs and kthreads.
The LWP structure contains, among other things, an embedded structure that maintains various bits of resource utilization information:
struct lrusage {
u_long minflt; /* minor page faults */
u_long majflt; /* major page faults */
u_long nswap; /* swaps */
u_long inblock; /* input blocks */
u_long oublock; /* output blocks */
u_long msgsnd; /* messages sent */
u_long msgrcv; /* messages received */
u_long nsignals; /* signals received */
u_long nvcsw; /* voluntary context switches */
u_long nivcsw; /* involuntary context switches */
u_long sysc; /* system calls */
u_long ioch; /* chars read and written */
};
The information is updated during execution per LWP. Note that the
process structure also contains an lrusage structure, which gets
updated from each LWP as the LWP exits. In other words, the lrusage
data at the process level is the sum of all the LWP's resource usage
data. According to the proc(4) man page, this usage data is
available when microstate accounting has been enabled for the
process, which is done in code using PCSET and the PC_MSACCT
flag. The resource usage information can be examined using the /proc
file system. The /proc directory hierarchy contains a subdirectory
for each LWP in the process, where the lwpusage data is accessible
using open(2) and read(2) on the /proc path (e.g.
/proc/
Other interesting bits of information maintained on the LWP include:
The kernel thread is the entity that is actually put on a dispatch
queue and scheduled. This fact is probably the most salient
departure from traditional Unix implementations, where processes
maintain a priority and are put on run queues and
scheduled. Here, it's the kthread, not the process, that is assigned a
scheduling class and priority. You can examine this on a running
system using the -L and -c flags to the ps(1) command:
Or, for all processes running on the system:
(In the interest of space I've removed most of the lines from the above listing.)
The columns in the ps(1) output above provide the process
ID (PID), the LWP number within the process (LWP), the scheduling
class the LWP is in (CLS), and the priority. It's interesting that
the output indicates that the LWP has a priority and scheduling
class, when technically it's the kthread associated with the LWP
that actually maintains this information (note the above comment on how
we often think of LWPs and kthreads as the same thing).
Other interesting bits in the kthread include:
Reference sys/thread.h for a complete definition of the kernel
thread structure.
Scheduling with class
The RT class provides realtime scheduling behavior, meaning threads
in this class have a higher global priority than TS and SYS
threads. Even with these enhancements, additional changes
needed to be made in order to provide realtime application support.
First, the kernel had to be made preemptable, such that a realtime thread in need of a
processor could preempt the kernel. The second
thing that needed to be addressed was memory locking. A realtime
thread cannot afford to be exposed to the latency involved in
resolving a page fault. This was addressed by providing a memory
locking facility, so that the developer of a realtime application
can use the memcntl(2) system call or mlock(3C) library function to
lock a range of pages in physical memory.
The TS, IA, and RT scheduling classes are implemented as dynamically
loadable kernel modules. The kernel binaries for the TS class are
in /kernel/sched. The IA and RT class reside in the
/usr/kernel/sched directory. The SYS class is an integral part of
the kernel, and thus not built as a dynamically loadable module.
The Solaris scheduler adds several features that enhance the
overall usability and flexibility of the operating system, among them are:
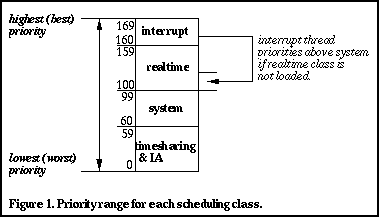
See Figure 1 below for a pictorial representation.
The class init routine is called at boot time for all the
preloaded scheduling classes. By default, the timeshare, system, and
interactive classes are loaded. Only the realtime class is not. When
a thread is set to the realtime class, via the priocntl(1) command
or priocntl(2) system call, the realtime class module is
dynamically loaded by the operating system. You can examine which
scheduling classes are currently loaded on the running system via
the dispadmin(1M) command:
Or, for a bit more information, there's a class function in the /etc/crash(1M) utility:
Let's put a process in the realtime scheduling class (process PID 833, my test program, sleeps for a minute then exits):
Now take another look at which scheduling classes are loaded on the system:
The class function in /etc/crash(1M) provides the class name, init
function address, and the address of the class-operations table, also
known as the class-functions structure or class-operations vector
table. (Operations-vector table is a generic term that describes an
array of pointers to functions, which is precisely what the class-functions
[cl_funcs] structure is.)
The class-functions structure bundles together function pointers for
three different classes of objects that make use of these routines: the
scheduler class manager, processes, and threads.
Operations used by the class manager include a cl_admin() function used
to alter the values in the dispatch table for the class, in addition to functions
for gathering information, setting and getting parameters, and
retrieving the global priority value. Thread routines include
cl_swapin() and cl_swapout(), cl_fork(), cl_preempt(), cl_sleep(),
cl_wakeup(), and cl_donice(). Like the VFS/vnode implementation, the
kernel defines a set of macros that are used to resolve a generic
interface call to the appropriate class-specific routine. Just as
the VFS_OPEN() macro will resolve to the ufs_open() routine to open
a UFS file, the CL_FORK() macro will resolve to correct scheduler-specific
fork support code, such as ts_fork() for the timesharing
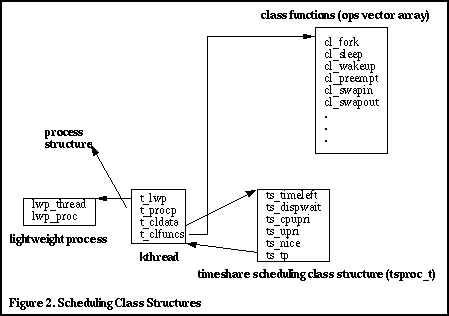
class. Linkage to the cl_funcs structure is also maintained in the kernel thread.
There are actually two pointers in the kernel thread directly related to
scheduling: the t_clfuncs pointer, which points to the cl_funcs structure,
and the t_cldata pointer, which points to a class-specific data structure.
The scheduling class-related structures are depicted in Figure 2
below. Every kernel thread is linked to a class-specific data
structure that maintains bits of information the dispatcher uses for
managing the execution time and scheduling of the kthread. We'll
cover the various fields involved when we discuss the dispatcher
algorithms.
Dispatch tables
(In the interest of space, we haven't replicated the whole table).
The dispatch table headers are defined in /usr/include/sys/ts.h
(along with the other TS-related data structures.) The values in the
table have the following meaning:
The values in the ts_quantum column are different. At priority 0,
instead of a quantum of 200 with a RES of 1000, we have a quantum of
20 with a RES of 100. However, the fractional unit is different.
Instead of 200 ms with a RES value of 1000, we get 20
tenths of a second, which is the same amount of time, just
represented differently (20 x .010 = 200 x .001). In general, it
makes sense to simply leave the RES value at the default of 1000,
which makes it easy to interpret the ts_quantum field simply in
milliseconds.
As you can see from examining the values in the table, lower
priority threads get larger time quantums. As the priority gets
better, the time quantum gets smaller because higher priority
threads are scheduled more frequently.
An interesting point is that the default values in the TS and IA
dispatch tables inject a 0 value in ts_maxwait for every priority
except the highest priority (59). So, just one increment in the
ts_dispwait field will cause the thread priority to be readjusted
to ts_lwait, except for priority-59 threads. The net effect of this
is that all but the highest priority (59) timeshare threads will have
their priority bumped to the 50 to 59 range (ts_lwait) every second.
This has the desirable effect of not penalizing a thread that is
CPU-bound for an extended period of time. Threads that are CPU hogs
will, over time, end up in the low 0 to 9 priority range as they keep
using up their time quantum, based on priority readjustments using
ts_tqexp. Once each second, they'll be bumped back up to the 50 to 59
range, and will only migrate back down if they sustain their CPU-bound
behavior.
Priority-59 threads are handled differently. These threads are
already at the maximum (highest) priority for a timeshare thread, so
there's no way to bump their priority via ts_maxwait and make it
better. The ts_update() routine, which is the kernel code segment
that increments the ts_dispwait value and readjusts thread
priorities using ts_lwait, reorders the linked list of threads on
the dispatch queues after adjusting the priority. (For each global
priority in the kernel, a linked list of threads is maintained --
we'll get into this in detail next month.) The reordering after the
priority adjustment puts threads at the front of their new dispatch
queue for that priority. The threads on the priority 59 linked list
would end up reordered, but still at the same priority.
Experimentation has shown that this results in some percentage of
priority-59 threads never getting processor time. Also, the threads
that ts_update puts on the front of the dispatch queue following
adjustment get scheduled more frequently. Setting the
ts_maxwait value to 32000 for priority 59 ensures the queue is never
reordered by ts_update(), so every thread gets a fair shot at
being scheduled.
The dispatch tables can have user-supplied values applied, using the
dispadmin(1M) command. This should be done with extreme caution, as
I've seen dispatch table "tweaks" drastically affect the performance
of a system and application behavior, not always for the better.
That's a wrap for this month. Next month, we'll cover the RT and IA
dispatch tables, get more into priorities, and discuss how the dispatcher
works. Following that, we'll examine interrupts, callout processing, and
turnstiles.
Stay tuned.
Resources
About the author
If you have technical problems with this magazine, contact
webmaster@sunworld.com
URL: http://www.sunworld.com/swol-10-1998/swol-10-insidesolaris.html
sunsys> ps -Lc
PID LWP CLS PRI TTY LTIME CMD
449 1 IA 58 pts/6 0:04 ksh
sunsys>
sunsys> ps -eLc
PID LWP CLS PRI TTY LTIME CMD
179 1 TS 58 ? 0:00 syslogd
179 2 TS 58 ? 0:00 syslogd
179 3 TS 58 ? 0:00 syslogd
179 4 TS 58 ? 0:00 syslogd
179 5 TS 58 ? 0:00 syslogd
179 6 TS 58 ? 0:00 syslogd
350 1 IA 59 ? 0:01 Xsession
230 1 TS 58 ? 0:00 sendmail
255 1 TS 58 ? 0:00 vold
255 2 TS 58 ? 0:00 vold
255 3 TS 58 ? 0:00 vold
255 4 TS 58 ? 0:00 vold
255 5 TS 58 ? 0:00 vold
227 1 TS 58 ? 0:00 powerd
240 1 TS 58 ? 0:00 utmpd
319 1 IA 54 ? 12:42 Xsun
317 1 TS 59 ? 0:00 ttymon
Advertisements
The framework on which the Solaris 2.X scheduler is built has its
roots in the Unix SVR4 scheduler, which represents a complete rework
of the traditional Unix scheduler. The SVR4 scheduler introduced the notion
of the scheduling class, defining the policies and algorithms applied to a
process or thread as belonging to a particular scheduling class,
based on values established in a dispatch table. For each scheduling
class, there exists a table of values and parameters the dispatcher
code uses for selecting a thread to run on a processor, in addition
to setting priorities based on wait time and how recently the thread
had execution time on a processor. Solaris 2.X originally shipped
with three scheduling classes by default: Systems (SYS), Timesharing
(TS), and Realtime (RT). Somewhere around the Solaris 2.4 timeframe,
the Interactive (IA) scheduling class was added to provide snappier
interactive desktop performance (more on this in a bit). The TS
class provides the traditional resource sharing behavior, such that
all processes on the system get their fair share of execution time.
The SYS class exists for kernel threads (e.g. the page daemon, clock
thread, etc.).
sunsys> dispadmin -l
CONFIGURED CLASSES
==================
SYS (System Class)
TS (Time Sharing)
IA (Interactive)
sunsys>
# /etc/crash
dumpfile = /dev/mem, namelist = /dev/ksyms, outfile = stdout
> class
SLOT CLASS INIT FUNCTION CLASS FUNCTION
0 SYS f00f7a50 f027b854
1 TS f5b2db64 f5b302f8
2 IA f5b2dc2c f5b30358
> q
#
# priocntl -s -c RT -i pid 833
# dispadmin -l
CONFIGURED CLASSES
==================
SYS (System Class)
TS (Time Sharing)
IA (Interactive)
RT (Real Time)
# /etc/crash
dumpfile = /dev/mem, namelist = /dev/ksyms, outfile = stdout
> class
SLOT CLASS INIT FUNCTION CLASS FUNCTION
0 SYS f00f7a50 f027b854
1 TS f5b2db64 f5b302f8
2 IA f5b2dc2c f5b30358
3 RT f67e5034 f67e5b60
> q
#
Each scheduling class loads with a corresponding dispatch table
containing default values for priorities and priority readjustment.
The dispatch tables can be examined and modified using the
dispadmin(1M) command:
fawlty> dispadmin -c TS -g
# Time Sharing Dispatcher Configuration
RES=1000
# ts_quantum ts_tqexp ts_slpret ts_maxwait ts_lwait PRIORITY LEVEL
200 0 50 0 50 # 0
200 0 50 0 50 # 1
200 0 50 0 50 # 2
200 0 50 0 50 # 3
200 0 50 0 50 # 4
200 0 50 0 50 # 5
.
.
.
fawlty> dispadmin -c TS -g -r 100
# Time Sharing Dispatcher Configuration
RES=100
# ts_quantum ts_tqexp ts_slpret ts_maxwait ts_lwait PRIORITY LEVEL
20 0 50 0 50 # 0
20 0 50 0 50 # 1
20 0 50 0 50 # 2
20 0 50 0 50 # 3
![]()
http://www.sunworld.com/sunworldonline/swol-08-1998/swol-08-insidesolaris.html
http://www.sunworld.com/sunworldonline/swol-09-1998/swol-09-insidesolaris.html
http://www.sunworld.com/swol-02-1998/swol-02-insidesolaris.html
http://www.sunworld.com/common/swol-backissues-columns.html#insidesolaris
http://www.amazon.com/exec/obidos/ISBN=0130981389/sunworldonlineA/
http://www.amazon.com/exec/obidos/ISBN=0131019082/sunworldonlineA/
http://www.amazon.com/exec/obidos/ISBN=0131723898/sunworldonlineA
Jim Mauro is currently an area technology manager for Sun
Microsystems in the northeast, focusing on server systems,
clusters, and high availability. He has a total of 18 years of industry
experience, working in educational services (he developed
and delivered courses on Unix internals and administration) and
software consulting.
Reach Jim at jim.mauro@sunworld.com.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Last modified: