Monitoring system and network performance metrics
Shrink-wrapped systems management solutions just don't cut it. We show you how we customized a fault and performance management system for one company to improve availability and response time for customers and internal users
|
|
Abstract
Our ability to construct complex applications and networks has far
outstripped our ability to manage these environments. The
application and network vendor communities try to convince us that
their products are readily adaptable to any environment and are
fully manageable with embedded utilities or standalone monitoring
software. It is naive to believe shrink-wrapped solutions can come
close to providing the level of management necessary to satisfy end
user requirements.
Here's how one company evolved their enterprise management system to
meet the challenges of distributed computing. (2,900 words)
 orporate and information technology management have followed the
lead of the pointy-haired boss in the Dilbert cartoon in
oversimplifying the problem of designing, implementing, and
especially, supporting enterprise client/server applications.
The typical IS department is now forced down one of two paths to
deal with the problem -- don't make waves, chuckle at relevant
Dilbert strips, and let the support fantasy continue or document
the real support requirements and be prepared to defend your
position. The don't-make-waves scenario is akin to an ostrich on a
busy freeway, where the operational support problems will run you
over even if you bury your head. This article provides no insight
for those who choose the ostrich mode of operational support.
orporate and information technology management have followed the
lead of the pointy-haired boss in the Dilbert cartoon in
oversimplifying the problem of designing, implementing, and
especially, supporting enterprise client/server applications.
The typical IS department is now forced down one of two paths to
deal with the problem -- don't make waves, chuckle at relevant
Dilbert strips, and let the support fantasy continue or document
the real support requirements and be prepared to defend your
position. The don't-make-waves scenario is akin to an ostrich on a
busy freeway, where the operational support problems will run you
over even if you bury your head. This article provides no insight
for those who choose the ostrich mode of operational support.
If, however, you are among the few brave persons willing to stand
your ground and fight for the tools you need to really support your
environment, then you may find this "real world perspective"
useful. It has been our experience that corporate managers will
respond positively to system/network system requests provided
alternatives are presented and a brief ROI analysis is
submitted. Alternatives can be as straightforward as conducting
a lost business or service analysis (i.e., if the application,
network, or server goes down for "X" amount of time, what is the real
world "$$$$$" impact on the business?). When conducting this type of
analysis, remember to consider the following cost points:
- Idle worker time x loaded wage per hour
- Lost business or sales
- Wasted machine cycles and carrier costs
- Damage to reputation
- Added cost of longer inventory periods
- Ripple effect on related business processes
In the information age, time is even more important than money.
Advertisements
Operating environment and requirements
Enterprise management systems need to meet a number of management
criteria. The OSI provides a definition that quantifies management
functions into discrete buckets: fault, performance, configuration,
security, and accounting. Although a full discussion of each of
these management functions would require far more words than
allocated to this article, a case study that focuses on some fault
and performance-management issues may be helpful in your
justification process.
A magazine publishing firm (Enterprise A) decided to make a bold
move by offering online subscriptions of their published
periodicals to Internet subscribers. This offering included
reformatting their periodicals into .PDF file types and building a
large Netscape server that could access periodicals stored on Oracle
databases while providing reliable access to Internet subscribers.
The primary online publication environment was comprised of four
Sun database servers, two Sun development servers, and a large 6-way
Sun Netscape server connected through a routed network comprised of
several Ethernet and fast Ethernet segments. The corporate
operational environment shared the network infrastructure and was
comprised of 800 Novell and Unix users with 18 Novell servers and 10
Solaris-based application servers distributed across four sites.
The task at hand was to implement a management system that could
provide fault and performance management for the online publication
systems and corporate end-user environment. The emphasis of the
system was to be able to provide high levels of service to online
subscribers and internal users.
After meeting with the end users and the online support team, it
became readily apparent that the primary business requirements for
the management system consisted of two metrics: availability and response
time. Armed with this information, our company, the Netplex Group,
designed and installed a platform-based management system that
provided the primary fault and performance management functions
needed to meet these main service objectives. The management system
was comprised of the following components:
- Platform hardware: a medium sized 2-way HP-UX server running HP-UX 10.2
- Platform software: OpenView Network Node Manager 4.1
- Network application: HP NetMetrix RMON management system
- Network agent: HP RMON probes
- System application: PerfView monitoring system
- Systems agent: MeasureWare agents for Sun, HP, and Novell servers
- Network application: Onion Peel's NDC Network Data Collector
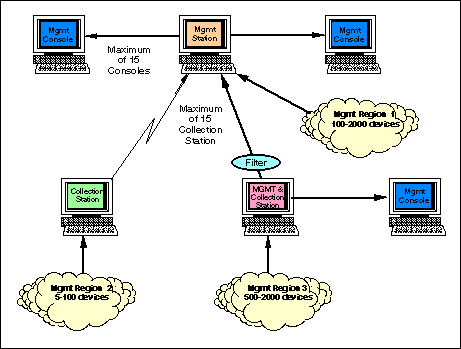
Network Node Manager -- the platform
The 4.1 version of the Network Node Manager (NNM) platform supports
over 300 third-party management applications (such as CiscoWorks,
3Com's Transcend, etc.), which allows the platform to become the
foundation for most element management requirements. The 4.1 NNM
platform is based on a fully distributed model that supports up to
15 domain managers and 15 management consoles. Events filters can
be created to allow enterprise-based information to be forwarded to
the master console. The distributed architecture will prove useful
with future implementations since each of the main sites has
enterprise and local support functions.
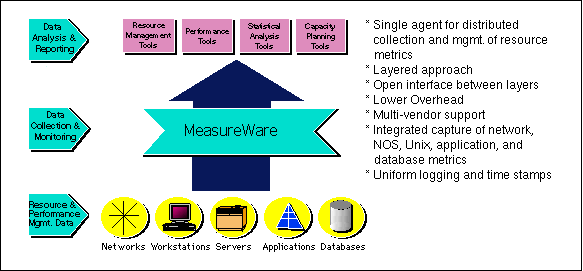
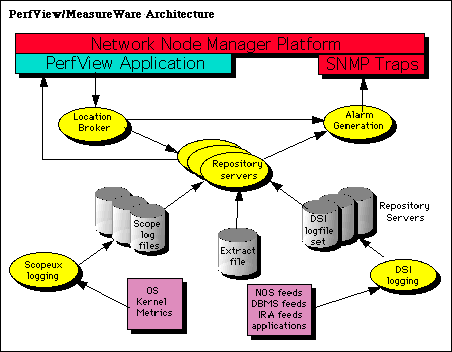
PerfView/MeasureWare -- The system/application performance monitor suite
The PerfView/MeasureWare product suite provides correlated threshold
based performance management for Unix, Novell 3.12 and 4.1, and NT
3.51 and 4.0 servers. The product suite is comprised of several
components: the server agent, which resides on the file servers; the
MeasureWare agent, which resides on a Unix server and functions as an
intermediate collection facility, a Unix station agent, and a
correlated data source collector; and the application suite which
must run on an HP-UX or NT server and includes the PerfView
analyzer, monitor, and trending modules. The applications can
provide on-screen and formatted reports of both real-time and
historical data. Historical data can be run through statistical
trending algorithms to provide capacity forecasting trends. The
PerfView/MeasureWare product suite is immensely scalable in both
architecture and data integration. The middle-level function of the
MeasureWare agent allows mid-level data collection facilities to be
separated or collocated with the management console. The
standards-based Data Source Integration (DSI) allows any SNMP- or
ASCII-based data to be integrated and correlated to other
MeasureWare parameters. The customized NetWare DSI template was
used to integrate the Novell SNMP data into the MeasureWare agent.
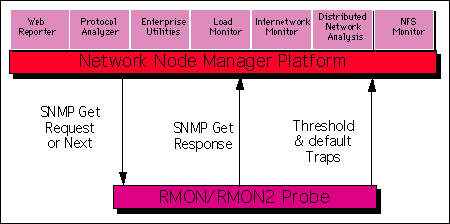
NetMetrix -- the network performance monitor suite
HP NetMetrix is an application that provides for remote monitoring
of Ethernet, Token ring, FDDI, and Fast Ethernet network segments.
RMON/RMON2 metrics that can be monitored include utilization,
various topology-based errors, packet size, and traffic generated
and received from specific network devices. NetMetrix monitors the
health of network segments and generates threshold-based events to a
management console. NetMetrix also has a protocol analyzer tool
that can be started via an application icon or triggered by a
network event threshold. Using Internet standard Echo MIB,
NetMetrix can perform response time monitoring of data packets for
different protocols. The Echo MIB has been integrated into the
standard HP RMON probes and is available as a server Internetwork
response time agent (IRA). The data collected by NetMetrix can be
displayed on-screen, integrated into printed reports or accessed via
the Web.
Onion Peel NDC -- the enhanced SNMP collection utility
The Onion Peel NDC software augments the base functionality of the
NNM platform. NDC is a fully integrated NNM software tool that is
comprised of software which facilitates the class-based collection
of MIB data. The class-based collection that supports wild cards
and SQL-like filters allows for general MIB object classes to be
specified for SNMP collection as opposed to manufacturer specific
MIBs. The NDC tool has a flexible output formatting function which
can also be used to import collected data into high-end modeling
tools like SAS, report generation engines, or spreadsheets.
Onion Peel ROVE -- the ROVE SNMP-enhanced, multiuser, and remote access utility
The Onion Peel ROVE (remote OpenView environment) product provides
enhanced remote access to the base NNM platform. ROVE is a fully
integrated NNM software tool that facilitates remote access into the
management station without incurring the process and communication
burden of remote X Windows sessions. ROVE Motif and VT-100 clients
provide a mechanism that allows support staff to remotely access the
management server from remote Motif and terminal clients
respectively. The Motif clients are configured to share a common
X-terminal session which limits the performance impact on the
management server. The VT terminal client provides a color-coded
tabular interface to critical OpenView data (object states, traplog,
etc.) for LAN and dial-based terminal connections. The VT-100
emulation is especially important to on-call IS personnel that live
a distance from the data center. A page in the middle of the night
can be assessed and many times resolved remotely.
Functional integration
The HP 9000/871 model D370 Server was installed and configured with
a mirrored boot partition to enhance the availability of the
enterprise management server. A color PostScript printer was
directly connected to HP management server ensure that cron-based
reports could be printed. With the server hardware fully operational
the NNM platform software and associated patches were loaded.
Remember, there are almost always patches out there that will make
your life a little easier. As previously specified, the platform
software needed to be installed first due to dependencies of the
subordinate element applications. We next loaded the correct
vendors' MIB versions, the most important being the Cisco router
MIB. With the MIBs loaded, seed router addresses were quantified
and the autodiscovery process was run. We were now ready to load our
applications.
The NetMetrix application modules were loaded and integrated into
the NNM platform. Nine critical segments were identified and
instrumented with RMON2 probes (intelligent LAN monitoring agents).
Once implemented, a two-week baseline was run for each segment to
determine current operating levels. Note that it was important to
monitor whether operational levels were viewed as acceptable
throughout the baseline period. Segment-specific baselines were
taken for protocol-specific (ICMP and Novell 802.3) response time,
utilization, broadcasts, and errors. The combination of
utilization, broadcasts, response time, and errors helped quantify
network availability, while the protocol-specific response time
clearly delineated network/system responsiveness.
It should noted that during the initial baseline, performance was
viewed as unacceptable, but the data was used to justify the
addition of a FastEthernet backbone segment. With network
operations brought to an acceptable level, a baseline was run a
second time and threshold-based alarms were set for each of the metrics
on each of the segments. Specific cron-based reports and Web-based
display formats were implemented for the monitored LAN segments. The
combination of the threshold-based notification, comprehensive
diagnostic tools, cron-based reports, Web-based interface, and
remote packet capture capability allowed the IS staff to
proactively support the network infrastructure.
The next focus was on the integration of the Onion Peel NDC product
and enhancement of the NNM platform to provide better management of
the Cisco routers. The NDC utility was used to provide a historical
SNMP collection of 30 of the 5,000+ Cisco MIB variables. The output
of the collection was stored in tabular flat file, which was then exported
to an Excel spreadsheet on a daily basis. A custom application was
created via the NNM application builder to view the same 30 MIB
variables on a real-time basis. The NNM tool menu was also expanded
to include a router interface reset function, which allowed the
support staff to remotely reset any router interface in the
network. The combination of the native Cisco traps, customized tool
bar, NNM diagnostic tools (Traceroute, ping, remote ping, ARP cache
display, etc.), historical date capture, and real-time views allowed
the IS team to proactively manage and thereby improve availability of
the Cisco routers.
Now that the network was reasonably solid, we turned our efforts
toward management of the systems. The PerfView application was
loaded and integrated into the NNM platform. Armed with a
system/application performance monitoring application, we focused on
instrumenting the servers that were critical to business
operations. Avanti SNMP agents were installed on the 18 Novell file
servers. The 18 remote data sources were integrated into the
MeasureWare agent running on the HP server via the DSI (data source
integration) function.
The alarm definition file and NOS connectivity module installed on
the HP server were configured to forward threshold-based NetWare
alarms to the OV_trap log on the NNM platform. The PerfView
applications graphs template were created and displayed critical
server functions (CPU_util, Memory_util, Disk_rate, Disk_util,
Network_rate, etc.) The combination of the baselined performance
metrics and the NNM discovery process provided the quantifiable
availability for the Novell file servers. The response time
requirement was addressed by including the Novell file servers in
the NetMetrix (ICMP and Novell_802.3) response time target lists.
The 17 Sun servers and the HP management server were instrumented with
dedicated MeasureWare agents. These agents can track over 300
metrics sampled from the Kmem portion of the kernel -- the same
portion of the kernel sampled by sar or iostat.
The sampling interval is
every five to 10 milliseconds, the process write interval is 1/min,
and the global and application write interval is 5/min.
The Unix-based MeasureWare agents were tuned by shutting off the
short-lived process sampling in the parameter definition file because
these processes typically do not have significant value from a
monitoring perspective and can significantly increase processor
utilization. We noticed high CPU utilization (13 to 15 percent) on
the Sun servers even after shutting of the data logging of
short-lived processes. Upon further investigation, we opted to load
the new TOPs process patch, which reduced the MeasureWare process
utilization to a cozy (two to three percent). We also grouped the
Oracle and Netscape processes into application groups and monitored
the application groups as separate entities so as to better quantify
the metrics directly associated with these critical applications.
Although this level of monitoring proved to be adequate for the
Oracle servers, the Netscape server would sporadically have one or
more processes that would fall into a zombie state. The MeasureWare
agent could detect missing processes but could not, in the default
configuration, detect zombie processes. Given the business-critical
function of the six-way Netscape server, we elected to make use of
the DSI functionality once again. A client application was tied to
a Unix cron process to periodically log into the Netscape server.
If the login failed, an exit code was generated and forwarded into
the DSI logging process. An automation and custom alarm script was
developed for the MeasureWare agent on the Netscape server that
would log and alarm on failed login attempts and automatically
restart the Netscape server processes if two login attempts failed.
Upon completion of the MeasureWare customization for the Netscape
server, PerfView application graph templates were created and used
to display critical server and application functions (CPU_util,
Memory_util, Memory_page_rate, Disk_rate, Disk_util, Network_rate,
etc.) The combination of the baselined performance metrics,
application group definitions, customized Netscape monitoring
scripts, and the NNM discovery process provided the quantifiable
availability for all of the Sun application and database servers.
The response time requirement was addressed by including the Sun file
servers in the NetMetrix ICMP response time target lists.
Once all the critical monitoring applications were operational we
needed to integrate the Onion Peel ROVE software and customize the
mailer interface on the NNM platform to improve accessibility
to and from the management station. Given the critical nature of an online publication application, many of the IS support people are on
call. Before the management system was installed, their only course
of action when they received a call from a help desk operator was to
drive into the site and repair the system. Needless to say, there
were more then a few false alarms. The integration of ROVE into the
NNM platform allowed the IS support team to remotely dial into the
management server and assess the severity of the problem. The
integration of the NNM into the sendmail daemon allowed an e-mail
message to be generated in the paging system for critical Netscape,
Oracle, router, or segment availability problems. This level of
integration was fine tuned to eliminate extraneous pages and proved
to be a valuable tool for improving availability.
As you would expect, all the fault and performance management tools
that were integrated into the NNM platform needed to be coupled
with processes in order to gain the maximum support benefit. This
support process topic was introduced in the April 1997 SunWorld Real
World Perspectives column,
"Cut workplace frustration -- take these steps to build an efficient help desk."
Future enhancements
Based on the requirements of this online firm, future selection and
integration of trouble ticketing and event correlation systems is
being considered. The benefit of selecting a management platform
that supports a wide variety of management applications will become
readily apparent as there are a number of trouble ticketing and
event correlation vendors that integrate into the OpenView NNM
platform. The integration of these tools will further enhance the
support of existing and future business-critical systems.
Proactive management
Network and systems administrators often are made to feel like
living scar tissue constantly in fire-fighting mode. By
developing applications performance toolsets on top of enterprise
networked systems management platforms, network and systems managers
can become proactive members of the business team that provide
return on investment by deploying mission-critical systems more
efficiently and offering superior service levels to end
users.

Resources
About the author
Frank Henderson is chief technology officer at The Netplex Group. His
expertise is in designing and installing networks and reengineering help
desks, and in ORB, distributed databases, and network management.
Dave Koehler is director of network strategies at The Netplex
Group. He has 13 years experience in distributed network design.
Koehler has written for several journals and has delivered papers at
ComNet, IEEE, and SunWorld Expo. Reach Frank Henderson at
frank.henderson@sunworld.com and Dave Koehler at dave.koehler@sunworld.com.
![[(c) Copyright Web Publishing Inc., and IDG Communication company]](/sunworldonline/icons/b-copyright97.gif)
If you have technical problems with this magazine, contact
webmaster@sunworld.com
URL: http://www.sunworld.com/swol-10-1997/swol-10-realworld.html
Last modified: