The return of the cluster
How to construct your cluster configuration
July 1999
|
|
The return of the clusterHow to construct your cluster configuration |
July 1999 |
This month, Peter takes a look at the state of the cluster. Is a cluster of Sun computers worth building? What steps need to be taken to do it successfully? Peter helps you decide if a cluster is in your future.And a little reminder: Last month, Peter asked for your contributions to his growing collection of sysadmin tips and tricks. He's received some excellent suggestions -- please continue to send him more! He'll be updating this valuable archive again soon. Many thanks to all those who have participated. (2,500 words)
|
Mail this article to a friend |
![]() any systems folk shy away from clustering. Often, they have
the scars to show for their experiences with previous generations of
computer clusters -- which, frankly, didn't work very well.
Unreliable system failover, touchy monitoring, and frequent
"split-brain" syndrome ruled these early systems. A "split brain"
occurs when the systems in a cluster no longer communicate with
each other, lose track of what functionality each is providing,
and fight with each other for resources. The result is chaos,
and a cluster that isn't clustering.
any systems folk shy away from clustering. Often, they have
the scars to show for their experiences with previous generations of
computer clusters -- which, frankly, didn't work very well.
Unreliable system failover, touchy monitoring, and frequent
"split-brain" syndrome ruled these early systems. A "split brain"
occurs when the systems in a cluster no longer communicate with
each other, lose track of what functionality each is providing,
and fight with each other for resources. The result is chaos,
and a cluster that isn't clustering.
Clustering is more reliable and functional now than before. The issues are well known, and only specific configurations of system, storage, and networking are supported to help prevent split-brain syndrome. However, clustering is still implemented by loading a few daemons and scripts on top of two or more systems. These components implement monitoring (at the system and application level), arrange to move ownership of disk groups, and start and stop applications. No black magic here.
The future of clustering multiple machines together for reliability and performance is bright. Many companies, including Sun, Veritas, and Microsoft, have published roadmaps showing that many hosts will be able to share storage, monitor each other, and recover from failures -- all invisibly to users. There are many components that need to be in place to make this picture complete. The following functions comprise Sun's roadmap:
Obviously, it will take more then daemons and scripts to make this roadmap a reality. A lot of the future of clustering involves kernel modification. At least the plans are in place to move to a future where clusters are the norm, not an exception. For details of the cluster roadmap, current and future, see the Sun Cluster white paper.
Unfortunately, the future isn't now. Rather, architecting and implementing a supported and well-performing Sun Cluster 2.X facility is still a challenge. There is the issue of choosing products and a facility architecture. Then there is the implementation of the shared storage. Finally, there is the implementation of the cluster.
Choosing the cluster architecture
The first task in architecting a new cluster facility is determining
what software services are going to be highly available (HA). Each HA
product has a list of supported services. Most, including Sun Cluster,
allow you to write your own support for products that are not
presupported. For example, major database packages have cluster
support already designed, implemented, and tested. However, should you
want a home-grown or less-common application to be HA, you'll need to
write your own monitoring, application stop, and application start
routines (not to mention the testing). Cluster software provides an
API and a set of services, so these do not need to be written from
scratch.
The first choice to make in cluster configuration is to decide how many machines will be in the cluster. Two hosts is most common, with one or more services (applications) running on the hosts (see Figure 1). There are also supported cluster configurations involving more than two machines. For example, two primary servers could be backed by one secondary server. In such a case, if either primary has a problem, the secondary can take over for it. In the vast majority of clusters being built today, the cluster is of the "simple" two-node variety. Clustering is complicated enough without, well, adding complication. Of course, the future of clustering involves SAN storage, in which a group of machines can share the same storage. When SAN becomes a reality, and cluster software improves, n-way clusters will be more feasible and should become more common.
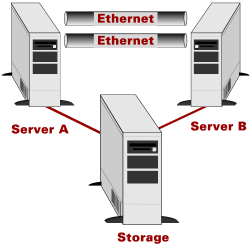
Figure 1. Typical two-node cluster configuration |
Selecting the type of cluster
Another complication in the current state of clustering is the
selection of the type of cluster. The three categories are asymmetric
failover, symmetric failover, and true database clustering. In asymmetric
failover (Figure 2), one host is the primary server and the other is a
secondary. The primary is the only one running an HA application. The
secondary is either idle or is running a "nonimportant" function
(say, development, testing, or reporting). If the primary has a problem,
the secondary takes ownership of the storage and starts the
application there (Figure 3). This failover can be done manually as
well, say to perform maintenance on the primary. The application can
then either fail back manually (via commands to the cluster software)
or automatically (when the primary recovers from its problem).
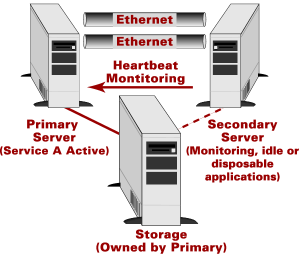
Figure 2. Asymmetric two-node cluster configuration (normal operation) |
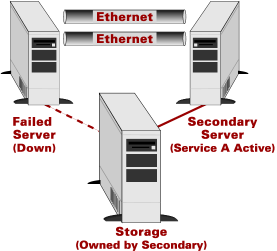
Figure 3. Asymmetric two-node cluster configuration (failover operation) |
Symmetric failover allows both hosts to run production applications (Figure 4). The hosts then monitor each other: should one service fail, the other would take over and runs both applications (Figure 5). Note that in symmetric failover, the hosts are generally configured with more compute and I/O power than is needed to run their individual applications. The effect of running both sets of applications on one host must be considered. If both are running at capacity and one fails, the performance of the remaining one will be poor.
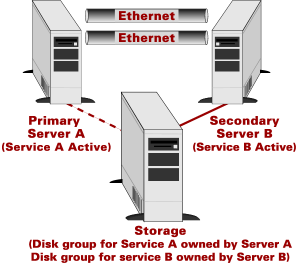
Figure 4. Symmetric two-node cluster configuration (normal operation) |
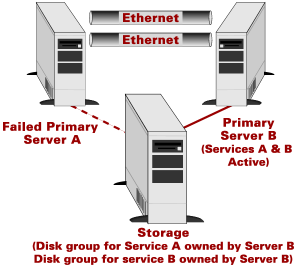
Figure 5. Symmetric two-node cluster configuration (failover operation) |
Note that each service in a Sun Cluster has its own IP address. The IP address moves to the host that is running that service. If a failover occurs, the server is failed to the alternate node, and that node is configured with the new IP address (as well as its old address). This way, client-side applications do not require reconfiguration to be able to locate the recovered version of the application. Of course, any TCP connections that were open with the old instance of the service will be terminated by the failover, and new TCP connections will need to be established. The good news is that if your cluster is providing an Internet-based service, the client will probably assume a network problem occurred at its end!
True database clustering is most commonly found in the form of Oracle Parallel Server (OPS). Sun Cluster and OPS form a package available from Sun. In an OPS environment, two systems concurrently run Oracle Parallel Server. The systems share storage, and concurrently access the storage. There is no single host ownership of the storage. To keep the database server's data access consistent, OPS includes a distributed lock manager (DLM). The DLM coordinates access to database objects, maintaining locks between the machines and allowing for lock recovery should one node of an OPS cluster fail. Parallel queries can be launched against the database, and both nodes can partake in the query.
Of course careful planning of database layout needs to be done, to ensure that the systems don't spend all of their time negotiating locks and asking each other for query information. Rather, data partitioning is the key to efficient OPS systems. By partitioning the data, each machine spends the majority of its time dealing with a proper subset of the data. This minimizes DLM operations and optimizes query parallelization. As a simple example, a database of customers could be partitioned alphabetically, with the data for customers with last names starting with A to M being managed by one server and N to Z on the other. A query for all customers who purchased a specific product could be sent to both servers, and the result would be returned faster than if the query were sent to one server managing all the data.
Database management on OPS systems is more complex than on others. Designing the partitioning, as well as day-to-day management of the database, requires extra knowledge and experience if it's to be done well. Also, the requirements for an OPS cluster are even more stringent than for a standard HA cluster. For example, the database must reside on raw disk rather than on filesystems (more on that below). Also, the interconnect between the systems must be scalable coherent interface (SCI) rather than Ethernet. This faster (1 Gbps), more complex interconnect is of course more difficult to manage and more prone to failure than Ethernet.
OPS can provide performance gains on queries that can be parallelized, and the overall database performance can increase simply with the ability to run Oracle on two systems concurrently. Along with speed, OPS has two features that, for some sites, make up for its complexity. The first is its resilience in the face of failure. In terms of resilience, if one node of an OPS cluster fails, the other acquires its locks and continues with its operations. That leads to the second feature: recovery time from failure. There is no "database is down" phase, merely a pause in processing while the locks are recovered. Full recovery from a crashed node can take seconds, rather than minutes for an HA failover. For sites than can't afford any downtime, OPS is an option worth considering.
|
|
|
|
|
Those darn details
Once a supported set of system hardware and software is selected,
there are details. Watch out because the devil's in there.
For instance, if a primary crashes, and then reboots successfully, should the application instance move to the secondary, or should it stay on the primary? The failover function can be set to occur only after a set amount of time has passed since the failure. This way, a failover can be set to trigger only if the primary server for the service fails to become available in a reasonable amount of time.
Deciding between system hardware and software and cluster packages requires time and attention. There are certain combinations of Sun servers and storage that are not supported in a cluster configuration, for example. Sun maintains an (internal) system/storage matrix that shows which storage products can connect to which systems, as well as which combinations are supported with each Sun Cluster release. (The current Sun Cluster release is SC 2.2.)
Another detail is storage management. Applications, of course, reside on filesystems. But database data can reside on filesystems or on raw disk. Sun Cluster requires that all failover applications (applications that will be managed by the cluster) reside on shared storage. The application, therefore, moves with the service's disk group to the appropriate system where it will be run.
Sun Cluster also requires that, for OPS, the database use raw partitions. The concurrent access by the databases to the disk forbids any filesystem from getting in the way.
Sun Cluster HA comes with a version of Veritas Volume Manager. OPS comes with a "different" version, called the Cluster Volume Manager (CVM). The CVM allows two nodes to access the same disk group at the same time.
There are specific version requirements for all of these components. For instance, before a site can move to a new release of Volume Manager, it must be supported within the cluster. Even patches are specifically cluster tested. The kernel jumbo patch must be cluster tested before it can be installed.
Finally, one limit on OPS clusters is that each server has its own IP address, and the address does not move during a failover. Any client that tries to attach to a specific IP address will fail to recover until the failed server recovers from its failure. Oracle provides an API that will let client applications recover from a failed connection by finding the cluster's other server.
Interesting publications
One final note. Sun is starting to publish a series of "blueprints"
that document best datacenter practices. The publication takes the
form of a bimonthly online magazine and a series of books. Current
topics include high availability, load sharing, and Windows NT
integration. Read all about it at http://www.sun.com/blueprints/.
Next Month
That about covers it for the theory of clustering. As I write this, I'm three hours away from switching on a dual Sun Enterprise 10000 Sun Cluster facility. Next month, we'll make theory meet reality and examine what went into the implementation, testing, and rollout of this facility. Or, if you find my resume in this space, you'll know the rollout wasn't quite as successful as I'd hoped.
![]()
|
|
Resources
About the author
![]() Peter Baer Galvin is the chief technologist for
Corporate Technologies, a systems
integrator and VAR. Before that, Peter was the systems manager for
Brown University's Computer Science Department. He has written articles
for Byte and other magazines, and previously wrote Pete's Wicked World, the security column for SunWorld. Peter is coauthor of the Operating Systems Concepts textbook. As a consultant and trainer, Peter has taught tutorials on security and system administration and given talks at many conferences and institutions.
Peter Baer Galvin is the chief technologist for
Corporate Technologies, a systems
integrator and VAR. Before that, Peter was the systems manager for
Brown University's Computer Science Department. He has written articles
for Byte and other magazines, and previously wrote Pete's Wicked World, the security column for SunWorld. Peter is coauthor of the Operating Systems Concepts textbook. As a consultant and trainer, Peter has taught tutorials on security and system administration and given talks at many conferences and institutions.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-07-1999/swol-07-supersys.html
Last modified: