RAID basics, Part 2: Moving on to RAID 3 and RAID 5
How is parity used and what are the performance concerns involved?
July 1999
|
|
RAID basics, Part 2: Moving on to RAID 3 and RAID 5How is parity used and what are the performance concerns involved?
|
July 1999 |
In his previous article on RAID, Chuck covered the basics of RAID 0, 1, and 0+1. This month, he continues his series by defining RAID 3, and then discussing RAID 3 parity, performance, and RAID 3-to-RAID 5 extension. (2,700 words)
|
Mail this article to a friend |
![]() here is a classic trade-off in computing. When optimizing any
system, you can address speed, price, or quality; and of these three,
you can optimize for any two. Thus, cheap, fast systems will be of
exceedingly low quality; fast, good systems will never be cheap;
and inexpensive, good systems are never fast. We'll drive this
lesson home in this article as we continue our exploration of RAID
storage systems.
here is a classic trade-off in computing. When optimizing any
system, you can address speed, price, or quality; and of these three,
you can optimize for any two. Thus, cheap, fast systems will be of
exceedingly low quality; fast, good systems will never be cheap;
and inexpensive, good systems are never fast. We'll drive this
lesson home in this article as we continue our exploration of RAID
storage systems.
A small review
As you'll recall from last
month, RAID storage systems combine many smaller, inexpensive
disks to form larger, logical drives. Different RAID configurations
can provide more storage, faster performance, or improved redundancy,
depending on your needs. In general, almost all RAID
implementations focus on some sort of redundancy to offset the
increased failure rate of many drives working together.
RAID 0 simply combines drives to create a larger virtual drive. No redundancy is provided, so if any drive in the group fails, the whole virtual drive fails. This is no different from plain old disk drives, except that you can create larger volumes that better suit your system's needs.
RAID 1 uses pairs of drives to create a copy, or mirror, of every bit written to the pair. If a drive should fail, the system automatically uses the remaining member of the pair to recover the lost data. While RAID 1 halves the amount of usable space available within a RAID set, it provides the highest performance for both reads and writes.
RAID 0+1 combines volumes, like RAID 0, to create larger virtual volumes, and then attaches a mirror, like RAID 1, to ensure that no data in the virtual volume is ever lost. RAID 0+1 offers the best features of both configurations, providing speed, virtual drive management, and complete protection from drive failure.
In terms of our three-way analysis, RAID 0 is fast and cheap, but its lack of redundancy ensures that it will be of low quality due to its unreliability. RAID 1 is fast and highly reliable, but that comes at a cost: it will never be cheap. Logically, there should be a third combination, a RAID configuration that is cheap and highly reliable, but that suffers in the performance arena. Indeed, there are not one but two such flavors: RAID 3 and RAID 5.
Introducing parity
RAID 3 and RAID 5 use the concept of parity to provide redundancy in
the RAID volume. In simplest terms, parity can be thought of as a
binary checksum, a single bit of information that tells you if all
the other bits are correct.
If you had to configure a modem before 1995 or so, you've at least had to think about parity. In the world of data communications, parity, either odd or even, is used to determine if a single byte of data has made it across the line correctly. For each byte, you simply count the number of 1-bits in the byte, plus the extra parity bit associated with the byte. If the count is an odd number, and you are using odd parity, the byte is assumed correct. Similarly, an even count when using even parity is just as reassuring. However, if the count comes up even when using odd parity, or vice versa, something has gone wrong, and the byte is bad.
In the communications world, you transmit an extra bit for each byte to indicate the correct parity. In the RAID world, you do something similar, but on a larger scale. For disk systems, you create blocks of parity, where each bit in the block corresponds to the parity of the corresponding bits in other associated blocks. Thus, with 512-byte blocks, you have an extra 512-byte block, with each bit within each byte in the parity block set to the parity of the similar bits in the other blocks.
In data communications, the parity bit tells if you if a byte has gone bad, but it can't tell you which bit in the byte is the culprit. This means that you can detect, but not correct, a potential error. For RAID systems, this is not enough. Detection is critical, of course, but without correction of the errors, you have not improved your overall reliability.
For example, suppose you discover that the fifth bit of the tenth byte in the parity block is incorrect. If that parity block contains parity data for eight other data blocks, any one of those blocks could be the bad block. How can you know? You might compute an additional parity bit for each block, so that the bad block's parity would provide the missing clue, but this is hardly ever done. Instead, you rely on your disk hardware to report back some sort of read error, flagging the bad block. With this extra information, you can correct the errant bit, restoring data integrity.
In fact, almost all RAID systems rely on controller error reporting to detect potential errors, using the associated parity bits to repair the defective block. If the controllers don't complain when the data is read, the system assumes that the bits are good and proceeds to use the data.
Parity bits are the most popular of the many error detection and correction schemes for use in RAID systems. Used without additional error indicators, simple parity can detect single bit errors without any correction. With additional controller feedback, simple parity detects and corrects single bit errors. Other schemes use extra bits to detect two-bit errors and correct single-bit errors. Most ECC (error checking and correcting) memory is of this type, which is why it is more expensive than plain memory or simple parity-based memory.
Using parity for RAID 3
RAID 3 takes a simple approach to using parity in a RAID
configuration. Given a set of n drives, it uses one drive
to hold parity data, striping the data across the remaining
drives. In a four-drive RAID 3 set, three drives would hold data;
the fourth is dedicated to parity. Such a configuration is often
denoted as 3+1. Here is a schematic of a RAID 3 3+1
configuration:
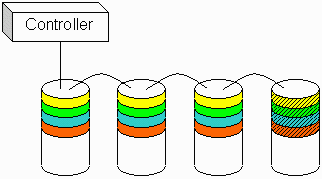
Figure 1. RAID 3 3+1 configuration |
Blocks with common parity blocks are shown in the same color; the parity block is shown with a hash pattern. A single group of corresponding blocks and their parity block is known as a single stripe within the RAID set.
Within that fourth drive, each block holds parity for the corresponding blocks in the other three drives. The beauty of RAID 3 is that a failure in any drive can be hidden from the system, just as with RAID 1, but the overhead is reduced from 50 percent (in RAID 1) to just 25 percent (in RAID 3 3+1). If you were to use more drives in the set, the overhead gets even smaller. If you use eight drives in a 7+1 configuration, your overhead drops to 12.5 percent, and so forth.
Reading and writing data to a RAID 3 volume can get complicated, depending on the state of the RAID set. The simplest scenario is a single read from a RAID 3 set running without any drive failures. In this case, the appropriate block is read from one of the data drives, with little or no additional overhead due to the RAID configuration.
When you write to a RAID 3 set, things get trickier. When you write a single block to a single drive, you must also compute parity for all the blocks in that block's stripe, and rewrite the parity block accordingly. For example, if we write one of the green blocks in the illustration, we must recompute parity for all three green blocks, and then rewrite the green parity block in the fourth drive. For this case, a single write operation actually involves a read (to pick up the associated blocks in the stripe), computation of the parity, a write (of the actual data block to be written), and another write (of the parity block). That's a lot of overhead for a simple write!
You can make life easier on your RAID system by carefully constructing your stripe size to match common I/O lengths used in your system. If a single write operation happens to be the size of a complete stripe (a so-called full-stripe write), you don't need to read the associated blocks in the stripe to compute parity. You can compute parity for the entire stripe and write the data and parity directly to the data and parity drives.
Getting full-stripe writes is the nirvana of RAID systems. In systems where many applications read and write data blocks of many different sizes, full-stripe writes are few and far between, causing miserable system performance. However, if you are only running a few applications, especially databases, you may only see writes of a single size. Oracle, for example, uses a single size block for all I/O, usually eight kilobytes. If you run Oracle atop RAID 3 or RAID 5, you should configure your RAID stripes to match the Oracle I/O block size.
|
|
|
|
|
When bad things happen to good drives
So far, we've looked at reading and writing when things are running
well. Now let's look at what happens when you lose a drive, causing the RAID set to run in degraded mode.
RAID 3 can tolerate complete loss of a single drive, but not without performance penalties. When the drive fails, all the blocks on that drive must be reconstructed using parity information. When you read a block from a good drive, nothing changes. When you read a block from the failed drive, all the other blocks in the stripe must be read. These blocks, along with the parity block, are used to reconstruct the missing block.
Writes are not changed in degraded mode. You must still compute parity for the entire stripe, requiring additional reads if you are not requesting a full-stripe write.
Eventually the failed drive is replaced, and the system must then reconstruct the failed drive, block by block. It does this in the background, reading each stripe, computing the missing block, and rewriting the new block to the new drive. Ideally, this rebuild activity occurs when the system is not using the RAID set; but if that's not possible, it can happen that rebuild traffic slows or delays real system I/O. This can be a serious concern for large RAID volumes because the RAID set stays in degraded mode until the new drive is fully rebuilt. Performance is affected until you are out of degraded mode, and a second drive failure while in degraded mode results in the loss of the entire RAID set. Therefore, be careful when building RAID 3 volumes: you may be able to hot swap a drive in 30 seconds, but that does you little good if it takes six hours to rebuild a degraded RAID set.
Performance concerns for RAID 3
Beyond the problems with normal writes and degraded reads and writes
with RAID 3, there are other performance problems to consider. The
biggest problem with RAID 3, and the reason you find it little used
in the real world, is that the parity drive becomes the bottleneck
in the system during write activity.
If you use a RAID 3 volume for general random read activity, your write operations for the data will be spread over a number of physical drives (three, in our example, though there can of course be more). However, any write to any data drive requires a write to the parity drive. For write-intensive applications, the parity drive cannot keep up, and the whole RAID set slows down as requests to write to the parity drive back up.
For this reason, RAID 3 is a good storage choice for low-write, high-read applications like data warehouses and archived static data. It may take longer than usual to write the data to the RAID 3 set, but once written, reads are quick. Because such archives tend to be large, the cost savings between RAID 3 and RAID 1 for similar storage can be significant.
Never use RAID 3 for general-purpose storage unless you have huge amounts of cache in the disk controller. In these controllers, all writes are staged to cache and the I/O is acknowledged as complete to the host system. The controller then writes the data to the drives while the system proceeds to the next operation. Even with these controllers, RAID 3 is still not your best choice. You'll simply wear the parity drive out faster than the others, due to its increased level of activity compared to the data drives.
Extending RAID 3 to RAID 5
The problems with the parity drive in RAID 3 has caused almost all
RAID systems to shift instead to RAID 5. RAID 5 is operationally
identical to RAID 3: several blocks in a stripe share a common
parity block. The parity block is written whenever any block in the
stripe is written, and the parity data is used to reconstruct blocks
read from a failed drive.
The big difference between RAID 3 and RAID 5 is that RAID 5 distributes the parity blocks throughout all the drives, using an algorithm to decide where a particular stripe's parity block resides within the drive array. Here is our same RAID volume, converted from RAID 3 to RAID 5:
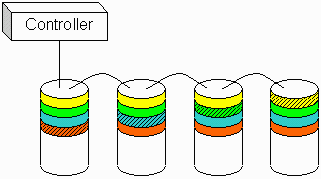
Figure 2. RAID 5 |
Notice how the parity blocks are staggered throughout the drives. This ensures that I/O needed to read or write parity blocks is distributed throughout the RAID set, eliminating the single-drive bottleneck found in RAID 3.
Except for eliminating the parity drive problem, RAID 5 suffers from all the same problems as RAID 3: slow writes, sensitivity to I/O block sizes, and potentially lengthy rebuilds of degraded RAID sets. In spite of this, RAID 5 is very popular as an economical redundant storage solution, especially when the individual drives are coupled by a caching controller that can mitigate some of the write latency inherent with RAID 5.
Controller issues
RAID 3 and RAID 5 configurations are particularly sensitive to disk
controller loading. Our example sets shown in the illustrations are
actually a performance disaster waiting to happen, since all the drives in the
set are driven by a single disk controller. While the number of
I/Os initiated to the RAID set would not be enough to swamp a single
drive, they can often overwhelm the controller, which must manage
all the I/O requests to all of the drives.
For this reason, it is critical that drives combined to form a RAID set be managed by separate controllers. That way, multiple I/Os initiated by the system are sprayed across multiple controllers, and then on to the individual drives, preventing any one controller from becoming saturated. When you are deciding which RAID 5 system to buy, pay very close attention to the internal controller architecture behind the RAID controller. If all the drives in a single RAID set are on the same device chain on a single controller, you are headed for dangerous waters.
We'll go much further with this subject next month, as we examine
controllers and hardware-based RAID solutions in detail. Getting
the RAID configuration right is only half of the battle; attaching
all those drives to each other and your system is just as
important.
![]()
|
|
Resources
About the author
Chuck Musciano started out as a compiler writer on a mainframe system before shifting to an R&D job in a Unix environment. He combined both environments when he helped build Harris Corporation's Corporate Unix Data Center, a mainframe-class computing environment running all-Unix systems. Along the way, he spent a lot of time tinkering on the Internet and authored the
best-selling HTML: The Definitive Guide. He is now the chief information officer for the American Kennel Club in Raleigh, NC, actively engaged in moving the AKC from its existing mainframe systems to an all-Unix computing environment.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-07-1999/swol-07-raid2.html
Last modified: