How to design your Web site for availability
Follow these guideline to help make your Web site as reliable and secure as possible
July 1999
|
|
How to design your Web site for availabilityFollow these guideline to help make your Web site as reliable and secure as possible
|
July 1999 |
This month's IT Architect column is devoted to a key component of the IT architecture: your Web site. Can you ensure the reliability and availability of your site? Make sure you've covered all the bases: network access, server reliability, and security. (7,000 words)
|
Mail this article to a friend |
Foreword
This month we address a hot topic -- the reliability of Web sites, and how to architect them. Currently, our firm is working on several e-commerce projects, and an obvious requirement for all of these projects is to have a Web infrastructure that will scale to support large numbers of sessions and stay up continuously. This is not just about hardware configurations -- there are several aspects to the architecture that effect its reliability. I hope our experiences will help you better architect your Web sites.--Kara Kapczynski
![]() n the relatively short history of the Web, a number of Web sites
have fallen victim to their own popularity -- too many hits, too
much processing, and an overburdened staff. In each case, all these
things combined in one way or another to bring the site down.
No single aspect caused all the sites to fail; rather, the causes were
diverse in nature. But the end result was the same in each case -- availability
suffered. The sites were unable to maintain an available Web presence
because they were too stretched for time and/or resources to manage their
infrastructure effectively.
n the relatively short history of the Web, a number of Web sites
have fallen victim to their own popularity -- too many hits, too
much processing, and an overburdened staff. In each case, all these
things combined in one way or another to bring the site down.
No single aspect caused all the sites to fail; rather, the causes were
diverse in nature. But the end result was the same in each case -- availability
suffered. The sites were unable to maintain an available Web presence
because they were too stretched for time and/or resources to manage their
infrastructure effectively.
eBay is a good case in point. This site has suffered from a number of embarrassing outages, slowdowns, and losses of service. Some of the outages were beyond its internal control -- such as when the routers at its ISP went down. Others were internal. For example, in June 1999 when an upgrade to eBay's systems didn't work the same way in production as it did in test mode, the site crashed. (To read more about this, see the news story in Resources below.)
The most serious fallout of an availability problem is the business problems it causes: lost revenue, lost customers, and potential loss of business. eBay opened the door to competitors just when it had proven how successful the online auction concept could be. The premise of this article is that such failures are avoidable.
In this article, we'll advocate taking an integrated approach to availability. We believe an integrated view is critical because when it comes to availability, if you fail in a part, you fail in the whole. We'll break down the issue of availability into five topics for consideration:
We won't cover any issues related to performance, response speed, or bandwidth. We'll assume that the Web site has been designed with sufficient bandwidth and server hardware to perform at a level acceptable to its owner. We'll concentrate, instead, on the additional issues and steps needed to make a functioning Web site more reliable and available.
The general technique used to improve reliability (see "Reliability vs. availability") is to eliminate any single point of failure. As you will see throughout the sections below, this is applied over and over again to make network connections and Web sites as a whole more reliable. On the other hand, redundant systems cost more to build and maintain. Each business must therefore assess the cost of damage due to a Web site failing against the cost of building a more reliable site.
Before we begin an earnest discussion about how to achieve availability, let's remind ourselves of problems that occur in the real world -- problems that must be anticipated and accounted for in order to achieve a reliable Web site:
Reliable network access
The first requirement for having a running Web site is to have
network access from your customers to your Web site. Network access
means that the physical networks linking your customers to your Web
site are working. Requests from customers must be able get to your
site, and your site must be able to process and reply to those
customer requests. This seems simple enough.
As shown below in Figure 1, customers accessing your Web site over the Internet must first send their requests in through a corporate network or their own ISP, across the Internet backbone, and onwards to your Web site. The point at which an ISP or corporate data center links to the Internet backbone is the network access point (NAP). A variety of problems can occur on the customer's side or in the Internet backbone itself, but, because they're beyond your control, we'll ignore them in this article. Instead, we'll focus on problems that can occur in the links between your Web site and the Internet backbone and between the Web site and your corporate network.
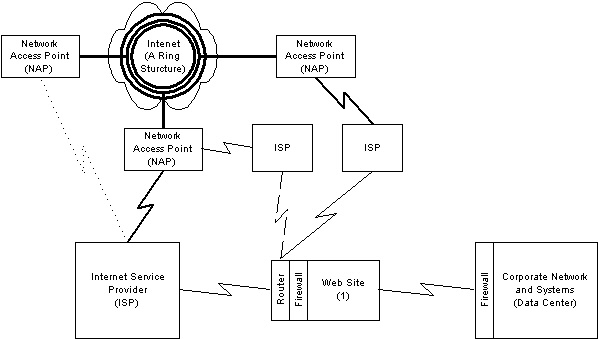
Figure 1. Network connections to a Web site |
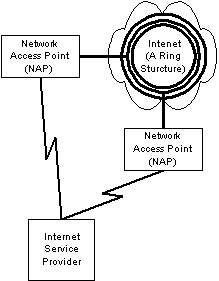
Figure 2. ISP with multiple NAPs |
There are several types of network access problems that can occur
Loss of connection to the Internet backbone
The obvious solution to the risk of losing your connection to the Internet backbone is to have dual access paths, so that losing
one doesn't make your site inaccessible.
The first way to get dual access paths is to have your ISP provide them. As shown below in Figure 2, an ISP can establish links to multiple backbone providers. If one link fails due to a major metropolitan outage as happened to MCI in Washington, DC, in May 1999, the alternate link will carry the traffic to and from the backbone. Check with your ISP to find out exactly how it connects to the backbone and the size of its connections -- in the event of a failure, the ISP's entire traffic load will have to run on the remaining link(s). Ask if it offers multiple NAPs and whether there is an extra charge for guaranteed access to them.
As always, the costs must be weighed against the possible risks due to a loss of service. For a small online store selling appliances, the cost might be prohibitive; for an e-trading site such as Charles Schwab, the costs are minor compared to the risk of lost revenue and reputation if the site goes down for an hour.
For Web sites located in a corporate data center, there is a second solution: links to separate ISPs, as shown in Figure 3. This should give your site redundant access to the backbone. But again, you need to find out exactly how these ISPs are themselves linked to the Internet backbone. It won't greatly improve availability if both ISPs are using the same backbone provider in the same region.
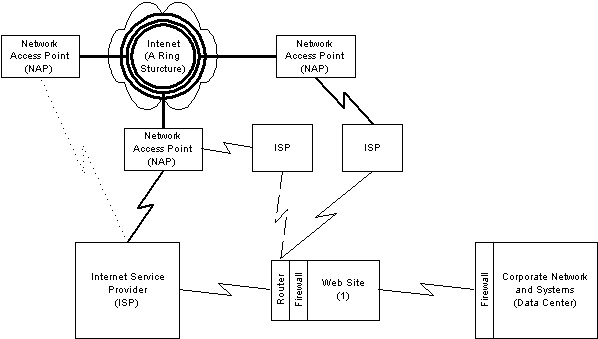
Figure 3. Multiple ISPs and multiple NAPs |
Loss of the entire site
As mentioned above, major disasters can knock out or destroy an ISP
or corporate data facility in any one region. Culprits vary from
natural disasters like hurricanes, tornadoes, and floods to man-made
problems such as cut fiber optic lines and accidental fires at
telephone-switching centers.
The only complete solution is to have two or more sites, as shown below in Figure 4. Each site should be located in a different region and must be capable of handling the entire traffic load of the Web site if the other site should fail.
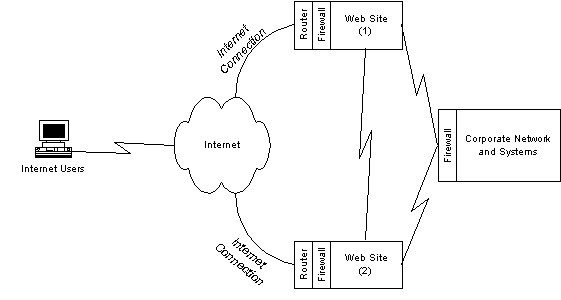
Figure 4. Second Web site for backup |
As is common for all backup service schemes, you can configure the backup site in one of several ways:
A cold site is the least expensive to maintain and might require some minutes or hours to start up. The new IP address has to be propagated through the Internet before customers can be linked to this backup site. The content for the site has to be loaded, and any auxiliary services such as ad servers and stock market quotes must be started and linked to their service providers. One problem with this approach is the difficulty of restarting a complex Web site and loading it with content. It might also be slow.
A hot site has the entire Web site up and running already. Obviously, this removes the delays and uncertainties of a cold site, but it comes at a higher cost.
Some companies will pay for a full backup to stand idle and ready to go, but most would prefer to have it doing some useful work. An active site does act as a backup in the case of failure, but it also processes requests and shares the workload as a fully functioning part of the overall Web site. Its operating costs might be higher than those of an idle system as it will be using network bandwidth and other resources on a regular basis. Also, it won't significantly reduce the cost of the primary site with respect to capacity, because both sites have to be configured to handle the full amount of Web traffic.
Nonetheless, it might be easier to justify the cost of an active site because it can improve response time. If two sites are located in separate regions of the US, or if one is in the US and the other in Europe or Japan, a load balancing mechanism can route requests to the site that is geographically closest, thereby reducing the distance the request travels and improving response time. This technique is known as using mirror sites if the two sites have identical content.
A major problem that remains is maintaining up-to-date content between the two sites and the backend corporate system. The design used depends on the frequency of updates and the amount of traffic that must travel between the separate locations. If the Web site is an order-taking system with a product catalog that is updated weekly, it's easy to use file transfer or database replication to move content from the corporate backend systems to the primary and backup site. However, for an auction site that updates its content with many bids and new items for sale, it will be harder and might be necessary to use a high volume transfer system with minimal delays, in order to have a viable backup site.
Access to the corporate network
Consideration must also be given to how the Web site is to be updated from the corporate network. There are multiple options for the connection between the corporate LAN and the Web site:
Small Web sites with static content are no problem. If the connection between the Web site and the corporate backend goes down, updates can be forwarded after the outage has been resolved. But for e-commerce sites, where there is true value-chain integration between an order-taking Web site and the inventory and order fulfillment systems on the corporate network, it's essential that the link between the two is maintained. In this case, the technique applied is the same as above -- there must be dual network connections between the Web site and the corporate network.
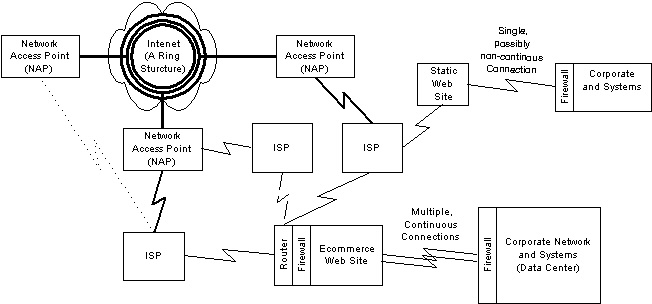
Figure 5. Access to the corporate networks |
Web site server availability
A major component of a Web site's reliability is the reliability of its
servers. Servers have to be up and running to
respond to incoming requests. No software or hardware is so perfect
that it doesn't have faults that can cause occasional crashes.
What are the design options in a world where servers can crash but
Web sites must run 24x7?
Without going into further detail, we can note that a Web site that consists of more than one server needs the redundant network connections between servers just as much as the site as a whole needs redundant access to the Internet backbone. Once we've assumed, as we did above, that any one server is expected to fail at some point due to hardware or software problems, the main design issue is making the Web site more available in the face of server failures.
Without being exhaustive, the main choices commonly in use are the following:
Single machines
At the lowest level of reliability is the single machine, which can
either be restarted or replaced by a different machine. That is
acceptable under certain situations for running a small Web site or
an auxiliary service (e.g., an ad server). If the machine
goes down, it's simply restarted. If a hardware component fails,
the single machine and Web site are down and out of operation until
it is repaired or replaced.
A more reliable approach for a single machine is to use a fault-tolerant machine. Designing systems for fault-tolerance allows them to handle errors and avoid failure when a fault occurs. Tactics to provide fault-tolerance include redundant hardware (power supplies, disk drives, processors), hot-swap capabilities (components that can be replaced without powering down a system), multiple network connections, and error recognition and handling methods (software). In this way, a system that is internally designed for high availability appears to the system in which it is embedded as a highly reliable component.
There are trade-offs when using fault-tolerant hardware:
Actually, the "nobody else does it" argument has some merit -- because there are few installed systems, finding trained staff to support those systems can be a problem. And if you train your own people you then have the challenge of retaining them in a competitive market where their skills are highly valued.
|
|
|
|
|
High availability clusters
An alternative to making one machine more reliable is to use two
machines or machines that can serve as backups for each other. The
high availability (HA) approach is a tightly coupled design, where
the machines are "aware" of each other, and are able to recognize a
failure mode in one of the other systems and adjust the shared
processing (see Figure 6). Refer to the IT Architect column called "Architecting high availability solutions" for a more in-depth discussion of this topic (see Resources).
The major benefit of designing HA systems is that they can achieve a high degree of reliability. However, they can be extremely complex and expensive to design, implement, and maintain. The use of an HA architecture has great payoffs, but is far from trivial to implement.
A high availability subsystem is viewed as a highly reliable component in the availability of the enclosing system, but might still need to be made redundant if the subsystem availability is inadequate. So, although an HA server cluster is extremely reliable, it's still subject to simultaneous fault -- for example, during a fire. This implies that the highly reliable HA server cluster might still need to be replicated to increase the availability of the Web service.
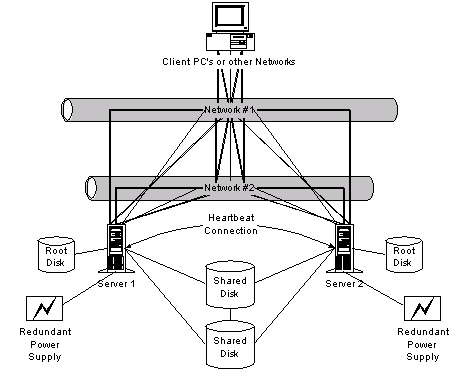
Figure 6. Example of a high availability solution |
Web server farms
An extension of the high reliability technique is to use a number of
machines that can be joined by a load balancing mechanism in a
"server farm" configuration, as shown in Figure 7. The load
balancing component routes incoming requests to different servers to
be processed. The servers are usually identical machines that only
have to be large enough to handle a fraction of the total traffic.
The number of servers to be used is variable. Some designers prefer
a few large servers; others like many smaller, cheaper machines.
The load balancing algorithm can be a simple round robin, or
may be more sophisticated, taking into account the current load on each
server.
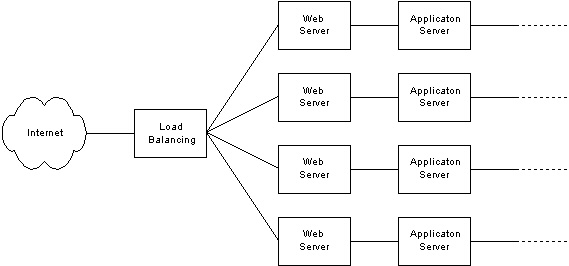
Figure 7. Web server farm |
A server farm configuration delivers availability because there are multiple machines that can take on additional processing in the event of the failure of any single server. It can be cheaper and easier to implement than the high availability cluster because Web farm servers don't need to be aware of each other. Only the load balancing component needs to be aware of each server, and then it only needs to know if it can receive requests. In the event of a failure, there is no complex failover process -- the load balancing component just stops sending requests to the failed server and continues routing traffic to the remaining servers. In this way, the architecture provides both availability and massive scalability.
| Reliability vs. Availability |
|---|
|
Reliability is measured by the amount of time between failures of a component. Availability of a component is based on the time to repair and the time to fail (availability = time to fail / ( time to fail + time to repair). The availability of a system can be greater than the availability of a component by introducing redundancy. However, the availability of the system is never greater than the availability of a nonredundant subsystem, so all must be made to be equally available.
Tactics for increasing reliability focus on increasing the time between failures. This also increases availability. However, availability can also be increased by decreasing the recovery time, or bringing recovery time for a single fault to zero. Contrary to what most software developers think, one does not get availability in a Web site by creating the perfect software application -- although the converse is true: An otherwise reliable system can be destabilized by software errors. As experienced operational staff knows, no brand of software or hardware can run forever without error. Reliability and availability must be planned for. |
One issue that limits the use of server farms is the need for the user session data to process a user request. To send users a static Web page via HTTP does not require knowing anything about these users or their activities during their current session. This is a stateless transaction, i.e., the state of the users and their session isn't required. On the other hand, if a user requests to add a new item to his shopping cart and show all the items currently in the cart, obviously the state of the user session is important and must be retrieved from some data source to send back to the user. This is a transaction with state.
Since simple HTTP requests for pages and images are stateless, a server farm with load balancing is a common architecture to use with the Web servers. However, application servers may or may not use a server farm architecture depending on whether or not they run mostly stateless transactions. It can also depend on the speed with which they can retrieve state data from a data store. The faster the data retrieval mechanism, the easier it is to use a server farm for application servers.
An alternative to retrieving the state of a user's transaction to each server as needed is to leave all the required data on one particular server and route the user's subsequent requests to the same server. This solution tends to reduce the overall performance of the server farm and can be complex to implement.
Combining techniques in a design
When building an actual Web site, there are a number of different types
of servers and services that have to be included. These might include
The architecture of a Web site may use a combination of reliability techniques, as shown in Figure 8. On the frontend you may have a server farm of Web and application servers. This approach gives a high degree of reliability as well as massive scalability. The loss of any one server will reduce the site's capacity by only a fraction.
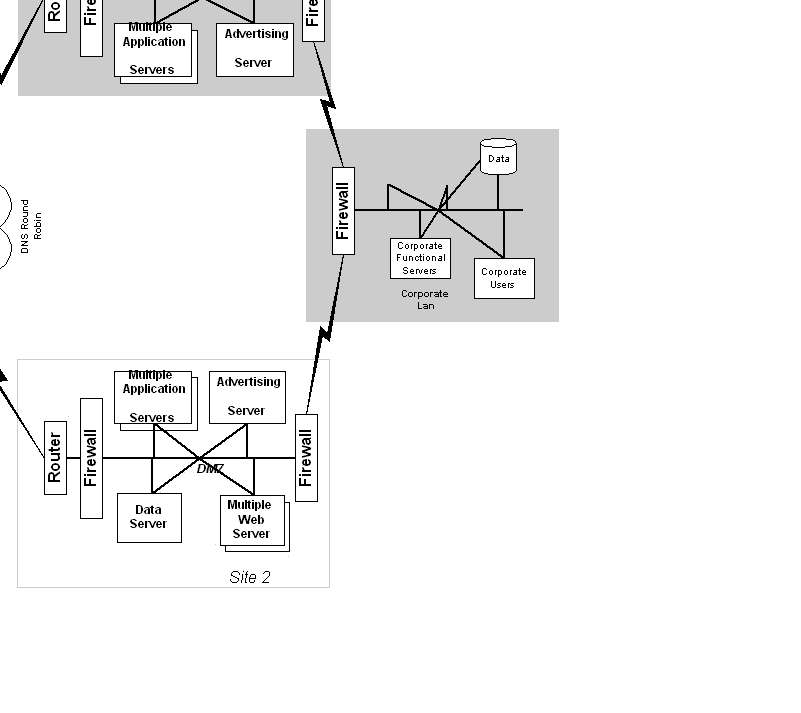
Figure 8. Sample Web site architecture Click Thumbnail to see full size image (12k) |
A backend server such as the database server might not need the massive scalability of the frontend Web servers, but might need to have higher availability. It can be a considerable design and maintenance challenge to coordinate data updates between multiple databases, particularly if the databases are distributed geographically.
The remaining server in the figure is an ad server that runs on a single machine. Since it is a noncritical service (i.e., the site can continue to run without it) there is no failover server for it. In the case of failure, it will be restarted on the same machine or moved to a different machine to run.
Content integrity
So far, we've discussed availability within the context of hardware
components and their arrangement to provide services to the Web
site. However, we should also mention that the content
being delivered by the Web site must be correct, and must be kept
safe from changes or theft. Numerous Web sites have had their content
altered by outsiders for personal or political reasons. In one case
credit card numbers were extracted from a site and the company was
publicly embarrassed when the thieves sent the customers copies of
their own credit card information. Finally, a Web site must not
be alterable to be used as a distribution point for bad
content. Viruses are of primary concern in this regard, but illegal
material such as stolen credit cards numbers is also a concern.
Changing the contents of a site or stealing information from it requires gaining access to resources and programs on the Web site. Naturally the first line of defense is to limit access to outsiders. This is done primarily through the following mechanisms:
The second line of defense is to recognize that no security system can continually keep hackers out of a Web site, and as a result, monitoring before and after a break-in is important.
Web site security is an extensive subject and well beyond the scope of this article. Nonetheless, it is important to review the main points of good Web security as a piece of the overall reliability architecture.
Firewalls
Firewalls manage port-level access to a network and a Web site. A
port is like a doorway into a server. Internet requests aren't
just sent to a server. There is always an explicit or implicit port
number on the server that is the complete destination of the HTTP
request.
For example, http://www.mycompany.com by default is using port 80 on server "www.mycompany.com" with the HTTP protocol. If a request arrives at the wrong server or the wrong port, the service handling requests on that port should ignore the request.
A firewall can also act as a filter to prevent suspicious requests from ever arriving at the server. Some firewalls can be configured to drop any request that tries to address a server or server port that has not been specifically enabled by the policy of the firewall. Firewalls can also verify that the request being delivered appears to match the kind of protocol (e.g., HTTP, FTP) that is expected on a particular port.
As shown below in Figure 9, firewalls can be used in several places. First, a firewall (#1) between the Internet and the Web server limits the number of ports and protocols open for use by outsiders. A second set of firewalls (#2 and #3) between the Web site and the corporate network protects the mission-critical backend corporate servers and data from external requests. In this way, public servers are placed in their own network space, isolated from the rest of the corporate systems. This demonstrates the DMZ architecture, where the Web servers are on their own subnetwork that is exposed to the Internet while the rest of the corporate resources are behind a secure wall with extremely controlled access. Finally, in a third use, a firewall (#4) can be used to isolate sensitive Web site data from other servers in the public area. This firewall is configured to allow access only from the Web site application servers. This approach is used to safeguard sensitive information such as credit card numbers.
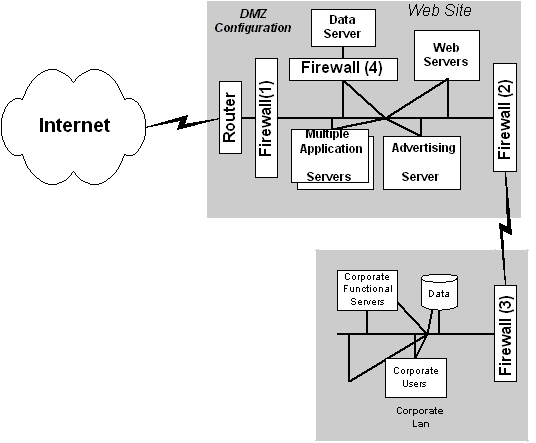
Figure 9. Using multiple firewalls |
Remember this, however: Firewalls are only part of an overall security solution, and you shouldn't depend on them alone. The greatest danger of using firewalls is that it might give you a false sense of security. Firewalls aren't a substitute for sound security on the corporate network, and most Web sites require additional layers of control beyond the use of firewalls.
To complement the filtering done by the firewall, all nonessential
ports and services on production servers should be shut down. See
Table 1 for a list of services. Some of these services, like FTP, are
inherently insecure because they send their password in the clear.
Many have secure versions that should be used instead such as scp in
the ssh suite of tools. Other services
(e.g., netstat, systat) give out information that can assist
other kinds of attacks.
| TCP/IP Service |
|---|
| =================== |
| DNS |
| Mail (SMTP) |
| Finger |
| Netstat, systat |
| Chargen, echo |
| FTP |
| Telnet |
| Berkeley <code>r</code> commands (<code>rlogin</code>, <code>rsh</code>, <code>rdist</code> etc.) |
| SNMP |
User account security
This topic is rich in variety that goes beyond the limits of this
article. In this area we want to emphasize the basic type of
attacks that are possible and the general approach to limiting their
success.
Outsiders such as hackers need to get access to a Web site by stealing access to another user's account or by extending the functionality of a request while using their own account. The first problem we cover here. We'll address the latter in the section below on software security.
Authentication is knowing who a user is, authorization is determining what resources he or she can access. User IDs and passwords are the most common means of providing authentication services, although there are other methods, including secure cards, biometric devices, and other means of identification. Authorization is the access to specific resources (e.g., file directories, read/write permission, database access) associated with a user account.
User IDs can be trivial to guess because they are often based on an individual's name. Passwords should be harder to guess, but this isn't always the case. There are a number of tools and techniques that can be used to decipher a password. Some of these include
lophtcrack, crack, or Netcracker, a hacker can process
a password file and try to guess a password by trial and error or by dictionary
comparison.
Two additional techniques allow the intruder to usurp a valid identity (and therefore attempt to circumvent the need for a password)
The general authentication security principles to follow are that (1) everyone should use some minimum level of caution in creating, displaying, and using account identification; and (2) the more powerful the functionality of a user account, the more secure the authentication process should be. In this regard, user accounts that merely store a user's preferences aren't as sensitive as an administrator's password, which could open a whole site to a hacker.
Here's a starter list of actions to take to improve password security:
password+)
Authorization is a vital part of user account security. The principle to follow here for production servers and services is to never grant more access to resources than is needed. This sounds like common sense, but it might be ignored in practice because it involves more work for the administrator. It might also be subtle to implement. For instance, if an application server running a product catalog needs to read its information from a database, it will need a database user account to do so. However, this account should not be authorized to read from other parts of the database, e.g., where credit cards are stored, nor be allowed write privileges. Limiting access to only the needed resources limits the amount of damage hackers can do, even if they do gain control of a user account.
Protecting sensitive data
One of the most difficult problems for Web security is how to protect
sensitive data like credit cards or proprietary information orders, inventory, etc. The first and most important concept in this area is to spend the time to identify the information that is sensitive and apply sensible restrictions to its access. Once identified, it is relatively easy to make the data harder to retrieve. Any or all of the following techniques can be used:
Software security
Every application system that processes requests from the user can
be seen as a separate component in the Web site architecture. Such
applications are directly on the firing line because they handle
incoming requests and must ensure that requests stay within the boundaries of what is permitted.
A first step is to not trust the correctness of user input. Whenever input is received from a user or another program, it should be validated, particularly if it is text input to be executed by a Unix/NT shell program or scripting engine. For example, it is possible to "piggyback" a second command on the input request to a Unix shell by separating the two commands by an ampersand (&) or semicolon (;). Each input request should be parsed for validity or at least filtered for suspect content.
A second step can be to use a separate security subsystem to control access to the application's resources. An application system should be able to configure which users to recognize and what functions and/or resources they are allowed to use. The best example of this is the use of a database for storage data. It has its own security system of user IDs and passwords and can usually encrypt data as needed. Its security system is separately controlled by a database administrator, not the system administrator. That way, no one person controls all the information about a Web site. Most complete e-commerce packages also come with security subsystems to control their own resources.
Nonetheless, this use of multiple security systems should be limited to a few large components. In general, security methods on a site should be centralized to the largest degree possible. In this manner, you can limit accessibility to security information to a very select few. Whenever there are several different systems controlling security the possibility for misconfiguration, malfeasance, and simple mistakes in configuration increases dramatically. By centralizing the system, the need to extend trust to several administrators is limited, and one need only to control a much smaller set of access points.
Finally, every application running on the Web site must define a clear security architecture and set out in detail its operational requirements. This must be applied consistently to third-party packages as well as in-house systems.
Monitoring your Web site
It isn't enough to just try to protect your site from break ins and misuse. You must monitor the usage on the site and actively search for security holes, both those that might have occurred in the past or those that could occur in the future. Activities that should be implemented to maintain a high level of security on the site are as follows:
Operational management
Many of the methods for having a reliable Web site rely on monitoring performance, security, and network usage. As a result, a major factor in achieving a high level of reliability is to have a competent operational staff running your site.
One of the major design alternatives in this regard is whether to locate your Web site at an ISP's facility or in your data center. The trade-offs to consider are discussed below:
| Pros: | Cons: |
|---|---|
| * Greater control over operational staff | * Dangerously close to corporate resources -- exposure to crackers, etc. |
| * Easier to update -- closer to your corporate data and resources | * Corporate staff may not have experience needed to run a 24x7 operation |
| * Local access and control of content | * May be more expensive |
| * Greater control over hardware |
| Pros: | Cons: |
|---|---|
| * Operational staff has much greater experiences | * Contractual responsibilities only; ISP staff doesn't report directly to your management |
| * Much greater access to bandwidth and other resources needed for expansion and emergencies | * You may only be one of many customers to support, especially in the case of a major disaster |
| * Access to disaster recovery support in the form of multiple sites in separate regions | |
| * May be cheaper |
Maintainability
One maintenance philosophy says, Don't change anything once it's stable. But this approach may run into problems. Things do change on Web sites, and sites that don't adjust will have problems.
What can change over time? Here's quick list:
There are three simple implications arising from the need to plan for these changes. First, since changes will come to the software and hardware, you need a test environment set up to validate the correct operation of the system. Next, you need a way to make changes without bringing down the whole Web site. If this isn't possible or is too expensive, the site should only be down for a minimal amount of time. Careful attention must be paid to processes for cleanly moving tested changes into the production environment, and there should always be the possibility of rolling back the change. Finally, you need to monitor usage and stay ahead of the peak capacity needed. This isn't a trivial exercise when starting up a popular new e-business. But as we mentioned in the example of eBay, outages and reduced service can severely damage your business.
Wrap-up
The quest for a reliable Web site starts with design, when the architect is planning the site and systems. It's implemented with an infrastructure that is robust and able to adapt to increases in demand and work around failed components. And, it's sustained by proper maintenance and good site management
practices.
We've advocated an integrated approach to reliability in this article. We've covered what we consider to be five of the most important subject areas that affect system reliability: network access, Web and application server hardware reliability, content integrity, operational management, and maintainability of your site. Certainly, these aren't the only topics you will need to address when designing a reliable Web site, but they do cover many of the most important issues.
The integration of all these areas is critical to building and running a reliable Web site. As in the old expression, "A chain is only as strong as its weakest link," a system is only as reliable as its weakest component. You can't afford to neglect any of them.
![]()
|
|
Resources
About the author
![]() Steve Casper is a national technology architect for Cambridge Technology Partners's North America Technology Organization, CTP's most senior technology team. As such, Steve brings more than nine years of IT industry experience in architecting solutions for a variety of companies. Steve specializes in network analysis and design, customer contact center architecture (call centers) and technical infrastructure assessments. He is passionate in the pursuit of excellence.
Steve Casper is a national technology architect for Cambridge Technology Partners's North America Technology Organization, CTP's most senior technology team. As such, Steve brings more than nine years of IT industry experience in architecting solutions for a variety of companies. Steve specializes in network analysis and design, customer contact center architecture (call centers) and technical infrastructure assessments. He is passionate in the pursuit of excellence.
![]() Cambridge Technology Partners, a consulting and systems
integration firm, offers management consulting, process
innovation, custom and package software deployment (including ERP
applications), networking, and training.
Cambridge Technology Partners, a consulting and systems
integration firm, offers management consulting, process
innovation, custom and package software deployment (including ERP
applications), networking, and training.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-07-1999/swol-07-itarchitect.html
Last modified: