0, 1, 0+1 ... RAID basics, Part 1
Get a quick tutorial on how these different RAID configurations work
June 1999
|
|
0, 1, 0+1 ... RAID basics, Part 1Get a quick tutorial on how these different RAID configurations work
|
June 1999 |
Confused about the various RAID configurations? Which one is best for your environment? In his first article in a series on RAID, Chuck starts with the basics and explains how RAID 0, 1, and 0+1 function so you can compare characteristics and decide whether or not they fit your network architecture needs. (2,500 words)
|
Mail this article to a friend |
![]() t wasn't so long ago that the world revolved around processors.
Speed was the metric of a data center: How many machines? How fast?
How well did they benchmark? Great debates revolved around
appropriate measures of performance: SPECmarks versus LINPACK versus
MIPS versus VUPS.
t wasn't so long ago that the world revolved around processors.
Speed was the metric of a data center: How many machines? How fast?
How well did they benchmark? Great debates revolved around
appropriate measures of performance: SPECmarks versus LINPACK versus
MIPS versus VUPS.
Processor performance is certainly important these days, but it's no longer the measure of a big system. I can remember when Sun shifted from 33- to 36- to 40-MHz SPARC chips in the SPARC 10; those extra cycles made a huge difference in total throughput. Now we barely raise an eyebrow at 333- and 400-MHz chips -- and gigahertz chips are just around the corner.
The real metric of a data center has shifted from "how fast" to "how much." How much storage? How many channels? How many spindles? The explosion of online data and the dramatic drop in disk storage is making multiterabyte data centers commonplace. If you plan to run an effective data center these days, you need to know less about processor and network architecture and a whole lot more about large-scale redundant storage systems.
For this reason, we're going to embark on a multipart series covering everything you need to know about large-scale storage. In the next few months we'll look at various disk architectures, connection schemes, configuration options, and performance metrics. If you're experienced in such matters, stick around to keep me honest and ask good questions; if you're new to the game, I hope you'll learn a thing or two.
The basics of RAID
In the beginning, storage was thought of in terms of physical devices. You
attached disks or drums to your system and carved those devices up
into data sets (for mainframes) or filesystems (for Unix boxes).
Most small systems had only a single drive attached, which might
have multiple platters. Large systems would have multiple drives
attached through one or more controllers. A DASD chain was just
that: a chain of direct access storage devices attached to a system
through a controller. Data sets existed in predefined areas on one
or more drives. Regardless of the number of devices, all systems
had two things in common: space was limited, and prices were
astronomical.
As storage needs grew faster than prices fell, the demand for larger datasets and bigger filesystems forced people to get creative. The concept of RAID storage was born. RAID is a simple concept -- a redundant array of inexpensive disks lashed together to appear as a single large device to the host system. There are several flavors of RAID, denoted by number, covering a spectrum of speed, reliability, and price points.
RAID is predicated on the idea that a group of smaller drives is cheaper than a single big device, although that concept is becoming less and less true. Beyond the potential cost savings, RAID also allows aggregate disk performance to far exceed the speed and throughput of a single device. Properly configured, RAID also tolerates individual device failure, allowing continuous uptime in spite of the occasional drive failure.
Using RAID technology to build a big disk subsystem is not a simple matter. You must understand your users' needs, application characteristics, and overall system loading. You must also establish uptime and recovery standards, and be willing to spend money in order to improve speed, reliability, and recovery. While vendors may lead you to believe that using RAID technology is as easy as signing a check and plugging in a few cables, the more you know about RAID systems, the better off you and your users will be in the long run.
RAID 0
As previously noted, RAID comes in various flavors known as
levels. RAID level 0, or RAID 0, is the simplest kind of RAID.
It uses several smaller devices combined to create a single, larger
device. In its simplest form, RAID 0 only offers increased
capacity, but it can be configured to also provide increased
performance and throughput. RAID 0 offers no redundancy or recovery
features, as we'll see, but is the most cost-efficient form of RAID
storage.
In its simplest form, you create a RAID 0 volume by concatenating several devices together. This concatenation may be done in hardware by a smart disk controller, or it may be implemented in software via the operating system disk device drivers. It is rare to find a hardware RAID 0 disk controller, so most RAID 0 implementations are software based.
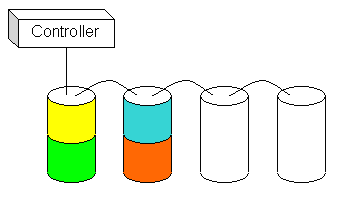
Figure 1. A simple RAID 0 configuration |
In this configuration, four drives are being combined to form a single logical drive. A single controller manages all four devices, and the operating system sees a single logical disk drive containing four times the space of any one of the constituent drives. Data is written to the devices in a sequential fashion, as denoted by the colored regions in the diagram. As one drive fills up, the data is spanned to the next device.
This setup has one advantage: increased space. The speed of the device is the same as any one drive in the RAID set, since I/O only occurs to one drive at a time as data is written. If any device in the set fails, the whole volume is ruined, so the actual reliability of the set is four times worse than any one drive.
There is nothing you can do to fix the reliability issues of RAID 0, but you can change the implementation to improve performance. Instead of writing data sequentially to the drives in the set, you can stripe the data across the all the drives, as illustrated in Figure 2.
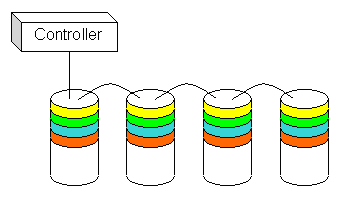
Figure 2. RAID 0 -- data across all drives |
In this setup, a single I/O to the logical volume is broken into four operations, one for each drive in the set. Figure 2 shows how striping distributes the sequential data from the first example across all four drives. All four drives operate in parallel, delivering four times the data back to the system in the same amount of time.
Tuning the stripe size is very important. If the stripe size is too large, many I/O operations will fit in a single stripe and be restricted to a single drive. If the stripe is too small, you may initiate too many physical operations for each logical operation, saturating the bus controller. This is where application knowledge comes in handy. You may find it useful to match your stripe size to a multiple of your system's page size, or a common application I/O parameter. Oracle, for example, blocks all I/O into 8-KB operations; a four-drive RAID 0 set with a 2-KB stripe size would balance each Oracle read or write across all four drives in the RAID set.
Striping distributes I/O evenly across the drives but can be a disaster when all the drives are attached to a single controller. When you initiate many physical I/O operations for each logical I/O operation, you can easily saturate the controller or bus to which the drives are attached. You can avoid this problem by distributing the drives across multiple controllers, as illustrated in Figure 3.
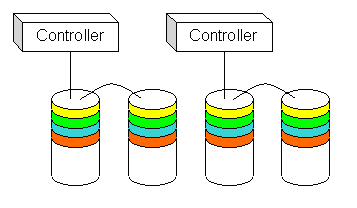
Figure 3. Drives across multiple controllers |
In this case, we've cut our I/O traffic on the bus in half; an even better solution would be to put each drive on a private controller. In general, an SCSI controller can handle five drives, but none of the drives on a single SCSI bus should be part of the same RAID set. As we'll see in later discussions, adding more controllers and managing I/O distribution across those controllers is critical when you want to wring every last bit of performance out of a RAID configuration.
|
|
|
|
|
RAID 1
RAID 0 offers additional space and some performance improvements but
is dramatically unreliable and has no capability for recovery after
drive failure. Most people do not use RAID 0 for
anything but temporary or scratch space, holding data they can afford
to lose or can easily recreate.
RAID 1 is a different story. RAID 1 focuses entirely on reliability and recovery without sacrificing performance. RAID 1 is the most expensive RAID option, but an increasing number of systems managers are turning to RAID 1 as the configuration of choice for critical, high-availability data.
RAID 1 is better known as mirroring. In a RAID 1 configuration, every device is mirrored onto a second device. Every write to one device is replicated on the other; reads can occur from either device as they are available. Cost obviously goes up: your usable space in a RAID 0 configuration is half the amount of raw disk installed. Figure 4 shows four drives arranged as mirrors, with the total available space equal to two drives combined. (The mirrored portions of the data are denoted with crosshatching.)
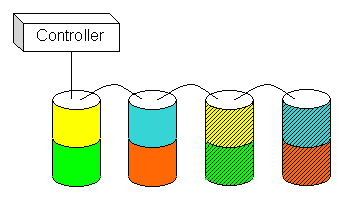
Figure 4. RAID 1 mirrored configuration |
RAID 1 configurations are immune to the failure of one drive in all cases and can tolerate failure of half the drives in the set, provided that no pairs of devices fail simultaneously. When a drive fails, the system simply ignores it, reading and writing data to its remaining partner in the mirror.
A RAID set running with one or more failed or missing drives is said to be running in degraded mode. Data availability is not interrupted, but the RAID set is now open to failure if one of the remaining partner drives should fail. Usually, the support staff is hustling to replace the failed drive and avoid further problems.
When the drive is replaced, the data in the good drive must be copied to the new drive. This operation is known as synching the mirror, and can take some time, especially if the affected drives are large. Again, data access is uninterrupted, but the I/O operations needed to copy the data to the new drive steal bandwidth from user data access, possibly decreasing overall performance.
By its nature, RAID 1 can double the amount of physical I/O in your system, especially in a write-intensive environment. For this reason, the use of multiple controllers is an absolute necessity for effective RAID 1 configurations. Figure 5 illustrates our sample configuration with a second controller added to handle the additional I/O load.
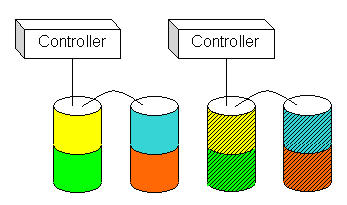
Figure 5. RAID 1 with two controllers |
The addition of a second controller improves performance, of course, but also has positive side effects on the data's reliability and availability. Since a RAID 1 set can survive the loss of half the drives if the partners aren't affected, that second controller could likewise fail without affecting data availability. This configuration also minimizes the potential damage from more common problems, like someone knocking a cable out of a connector or inadvertently cutting power to a controller or set of drives.
If you're committing to RAID 1 storage, don't focus solely on the drives as a source of failure. If you're already sinking all that money into twice as much raw disk space, throw in a few extra dollars for dual controllers, extra cabling, and even split power supplies for each half of the mirror. (This is easy if you have multiple power distribution units in your shop: power half your drives from one PDU and the others from another PDU. If one PDU fails, you're still safe.) Redundancy must exist at every level of the system, from drives to cables and controllers, before you truly have a fully mirrored disk environment.
RAID 0+1
Pure RAID 1 suffers from the same problems as pure RAID 0: data is
written sequentially across the volumes, potentially making one
drive busy while the others on that side of the mirror are idle. You
can avoid this problem by striping within your mirrored volumes,
just like you striped within the volumes of your RAID 0 set.
Theoretically, RAID 1 mirrors physical devices on a one-for-one basis. In reality, you'll want to build big logical devices using RAID 0 sets and then mirror them for redundancy. This configuration is known as RAID 0+1, since it combines the concatenation features of RAID 0 with the mirroring features of RAID 1.
Unlike RAID 0, RAID 1 and RAID 0+1 are often implemented in hardware using smart mirroring controllers. The controller manages multiple physical devices and presents a single logical device to the host system. The host system sends a single I/O request to the controller, which in turn creates appropriate requests to multiple devices in order to satisfy the operation. Usually, these smart controllers handle both mirroring and concatenation and may have multiple internal SCSI buses to which the physical drives are actually attached.
Higher end mirrored disk subsystems also offer hot-swap drives and some level of drive management tools. Hot-swap is an important feature, allowing you to remove and replace a failed drive without having to shut down the bus to which the drive is attached. Early mirroring systems lacked this feature, which meant that a drive failure while not causing data loss, did force a short system outage while you unmounted the affected filesystems, quiesced the SCSI buses, removed the failed drive, and installed the new one. Now, drives can be removed with the flip of a switch or a twist of a handle, safely detaching the drive from the bus without interrupting the system at all.
RAID 0 and RAID 1 exist at different ends of the RAID spectrum. RAID 0 offers large volumes with no redundancy or failure immunity at the lowest possible cost. RAID 1 provides complete data redundancy and robust failure immunity at a high cost. Both configurations can be tuned for performance by adding controllers and using striping to distribute the I/O load across as many drives as possible.
RAID 0+1 takes the best of both configurations, providing large
volumes, high reliability, and failure immunity. It does not,
however, solve the price problem. As we'll see next month, there
are two more RAID levels that address the price problem by trading
off some performance. Are they right for your shop? Come back next
month to find out.
![]()
|
|
Resources
About the author
Chuck Musciano started out as a compiler writer on a mainframe system before shifting to an R&D job in a Unix environment. He combined both environments when he helped build Harris Corporation's Corporate Unix Data Center, a mainframe-class computing environment running all-Unix systems. Along the way, he spent a lot of time tinkering on the Internet and authored the
best-selling HTML: The Definitive Guide. He is now the chief information officer for the American Kennel Club in Raleigh, NC, actively engaged in moving the AKC from its existing mainframe systems to an all-Unix computing environment.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-06-1999/swol-06-raid1.html
Last modified: