Application integration without band-aids
How to bring communication to your applications
June 1998
|
|
Application integration without band-aidsHow to bring communication to your applications
|
June 1998 |
What's the best way to make your applications talk to each other? And how do you do this without creating an architectural nightmare? Sam Wong lays it all out this month -- covering the questions you should ask, the architectures to consider, and the pitfalls to avoid when designing an IT architecture for integrated applications. (2,500 words)
|
Mail this article to a friend |
Foreword
If there was one thing I could do to make the life of the technical architect easier, it would be to improve the level of integration between applications. You know the story -- there are lots of products, tools, frameworks, utilities, packages, and "band-aids" to make the technology work together, but which do you choose? As promised in our first column, here's an approach to application integration. This month, Sam Wong discusses the issues associated with integration, and provides strategies for working integration into your IT design.--Kara Kapczynski
![]() ompanies are spending more on IT applications these days. Everywhere you turn,
it seems every division and department is launching one of a
smorgasbord of business initiatives to align IT and
business objectives, get closer to the customer, or make the
corporate knowledge base available on an intranet.
ompanies are spending more on IT applications these days. Everywhere you turn,
it seems every division and department is launching one of a
smorgasbord of business initiatives to align IT and
business objectives, get closer to the customer, or make the
corporate knowledge base available on an intranet.
The finance department is implementing SAP. Human resources just bought PeopleSoft. The Sales organization is rolling out Siebel. The Marketing folks are building a mammoth data warehouse. Manufacturing is designing a custom forecasting application. Each organization needs data from every other organization to go on-line. What are you to do?
In a perfect world, all of this data would sit in a single database. None would be duplicated, no interfaces would be built and you have a screaming piece of iron on the back-end running a self-tuning, highly available multi-terabyte RDBMS that consistently kicks out sub-second response times. In reality, however, each application team implements its own database -- and each will have to build many little interfaces to grab data from every other source system.
Application integration is about gluing together many applications so that they work as if they were one. The key is to take a structured approach. Treat application integration as independent from any single development project. Create an application integration architecture that ties together applications with a structured mechanism. This will reduce risk, cost and complexity.
But how do you build this application integration architecture? What are the options, and what are the issues that you should consider?
Application integration considerations
In order to make the right decisions when it comes to application
integration, you need to understand your various applications' business
requirements, as well as where they fit into the overall organizational
context.
You should be asking questions like these:
The answers to these questions will drive the detailed technical designs of the application integration architecture. Applications can be integrated logically at the front-end, at the business function layer, or at the back-end. The most sensible approach depends on the requirements of the business processes, and the requirements of your organization.
Application integration options
You can divide applications into three logical layers: user interface,
business functionality, and data. Each layer may be split across one or
more computers. You can define different methods of application
integration by how they facilitate communication between these three
layers. I have defined seven such integration models below.
Front-end Integration
Front-end integration occurs when the layout and operation of the user
interfaces of independent applications simulate the user interface of a
single application. Three different techniques for front-end integration,
depicted in the diagram below, are data exchange, user interface
encapsulation, and user interface consolidation.
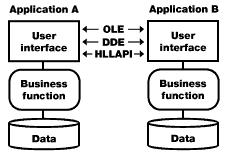 Option 1: Data exchange |
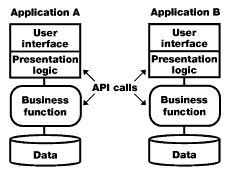 Option 2: UI encapsulation |
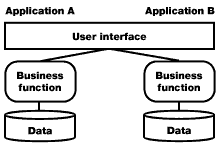 Option 3: UI consolidation |
In data exchange, presentation data is passed between the user interface layers of two applications. Data exchange is facilitated through inter-application communications methods such as Object Linking and Embedding (OLE) automation, Dynamic Data Exchange (DDE), and High Level Language Application Programming Interface (HLLAPI) or screen scraping. Your ability to integrate through data exchange depends on each application's support for the chosen data exchange mechanism. If the support exists, data exchange can be done, virtually without changes to one of the two applications. Unfortunately, there will be separate interfaces for each application -- a pain for your users.
User interface (UI) encapsulation involves the presentation logic of one system communicating with the business functions of another system. UI encapsulation is commonly done via embedding calls to exposed APIs of another application. To implement UI encapsulation, the exposed API libraries must be compatible with the calling program's language and architecture. You can achieve fairly tight levels of integration with this method. However, a drawback is that any interfaces built this way will create a hard connection between both applications: Changes in one application may affect the other. This reduces your applications' flexibility in the long term.
UI consolidation involves creating a single user interface that provides access to the business functionality of both applications. UI consolidation can be done when the presentation layers of both applications have been built using the same tool (such as PowerBuilder) or the same technology (such as a Web browser). An advantage of user interface consolidation is that the end-user executes all business processes within a single user interface module. Before the popularity of Web-based applications, UI consolidation of heterogeneous applications was typically not possible, because it was unlikely that the presentation layers of two different applications were built using the same tool.
|
|
|
|
|
Function Integration
Function integration occurs when the business logic within Application A
can call business logic within Application B as if that logic were part of
Application A. There are many technologies that facilitate function
integration, including transaction processing monitors (TP Monitors),
object request brokers (ORBs), remote procedure calls (RPCs),
publish/subscribe messaging middleware, and specialized data brokers. The
following diagram depicts several methods for implementing function
integration between two applications:
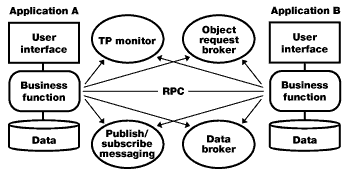
Option 4: Function integration |
For function integration to work, the applications being integrated must implement the exact conversational protocol, or wire protocol, of the tool you've chosen to facilitate communications. To exacerbate this situation, different implementations of the same middleware from different vendors typically don't use the same wire protocol. Or, if they do, they often have an implementation requirement that prohibits you from simply plugging them in. So, an application built on top of a TP Monitor from Vendor A can't be easily re-platformed to run on a TP Monitor from Vendor B without major changes to the application code.
Even so, function integration can typically provide solid, robust integration services that can scale to enterprise levels. The trade-off is that this kind of integration requires complex design and development work, and often locks your application to a single vendor -- making it more expensive and less flexible to develop.
Back-end integration
In back-end integration, the data access logic of independent
applications simulates the data access of a single application. So, the
number, location and ownership of back-end data stores is transparent to
the business functions that access this data. As you can see below, the
three techniques for back-end integration are database gateways, data
reconciliation, and database consolidation.
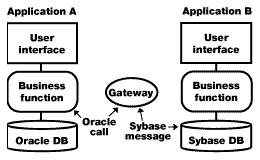 Option 5: Database gateway |
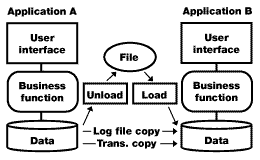 Option 6: Data reconciliation |
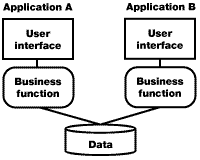 Option 7: Database consolidation |
Database gateways provide transparent data access across homogeneous and heterogeneous database platforms. A business function in Application A may be coded to access data from an Oracle database, but the actual location of the data may be a separate Sybase database that is part of Application B. Database gateways are offered by several third-party vendors, as well as the database vendors themselves. The good news is that they make data access transparent to the business functions, regardless of where the data resides. Database gateways only exist for some platforms, though, and you should make sure there's adequate support for all database-specific functionality and data types. These gateways should be limited to simple data access paths due to potential performance constraints.
Data reconciliation involves the delayed or near-real time movement of data between databases from different applications. You can use several mechanisms to facilitate data reconciliation. One utilizes simple batch data extracts and imports, and replication through copying log files. Another involves shadowing transactions to the target database. Performing batch data extracts and imports is probably the simplest and most common mechanism. However, implementing a data reconciliation solution often means building a hard link between applications, which reduces their flexibility. In addition, the solution becomes significantly more complicated when you need to do bi-directional data reconciliation.
Database consolidation involves creating a single database to house data from both of the applications being integrated. This is simpler when you have a homogeneous database platform across both applications. This kind of integration is attractive -- when you reduce the number of databases, you typically reduce costs. You need fewer software licenses and operational support staff. However, the process of consolidating databases and merging multiple data models to a single source is formidable. Even if you can consolidate databases, what you end up with may outstrip the capacity of any one database engine or server.
Recommendations
Which model represents the best approach towards application integration?
As you probably guessed, it depends on your environment. You must
analyze your requirements and use these basic
building blocks to develop your own application integration architecture.
But, to help, I have several principles that should guide you in this
effort.
Avoid the rat's nest
Unplanned application integration can often result in an organic growth of
interfaces between individual applications. When data stored in
application A is needed in application B, an interface is built. If a
new interface is built for every new need, the number of interfaces between
applications grows to
resemble a rat's nest or a total graph -- every application has hard-links
to nearly every other application. The end result is a maze of the
band-aid interfaces that Kara discussed in her March 1998 IT
Architect column. Anyone who tries to draw all of the band-aid
interfaces between applications ends up creating a rather busy spider
web, as depicted in the diagram to the left:
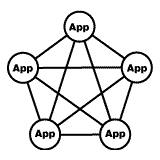
Individual interfaces: Up to 10 interfaces and 20 integration points |
In time, this gets to be untenable, especially as new applications continue to pop up -- or, in the worst case, are acquired en masse through a consolidation or merger. Each individual interface seems reasonable to each application team, but when you take a step back you have to question the dizzying maze of connections. The obvious solution to the total graph problem is to implement a centralized clearinghouse that brokers data between applications -- such as that depicted in the diagram to the right:
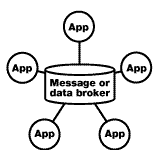
Central clearinghouse: Only 5 interfaces and 10 integration points |
When you're integrating a lot of applications, a structured hub-and-spoke model is valuable. A separate data or message broker facilitates the storage, mapping, and routing of common data between applications. This data or message broker represents yet another form of middleware that can be added to the middleware taxonomy from the April 1998 IT Architect column.
Implementing a data or message broker reduces the number of interfaces and connections that are required between applications, and increases your long-term flexibility. However, it also introduces a level of overhead that is typically not justified unless you have a lot of applications with heavy integration requirements.
Strive for the ideal, account for the real
It is very tempting to spend lots of time figuring out the ideal
architecture, without considering the characteristics of the applications
to be integrated. This ivory tower approach is most successful at creating
a specification that will never get implemented. The opposite end of the
spectrum has the architect limiting himself to readily available
options. This approach often spawns a weak architecture that lacks
longevity.
Take some time to assess the applications that you need to integrate today, as well as what you'll need to integrate tomorrow. It is best to limit your application integration architecture to one or two of the different models -- avoid supporting an inordinate number of tools and technologies.
Pick models first, then pick products
Don't rush into a product evaluation prematurely. Understand your
requirements, and choose the model, or models, that best fulfills those
requirements. Let your chosen integration model drive the criteria for
implementation tools.
Don't duplicate business logic
Because you can store data records in multiple application data stores, it
follows that you may have the same business logic in both the sending and
receiving applications. Maintaining separate code bases for redundant
business logic will drive up your support costs. Changes to business logic
must be duplicated and redundantly tested. Applications must become more
interdependent rather than independent. You should avoid designs that
duplicate business logic if at all possible.
Reconcile transactions, not data
There are two approaches to exchanging application data: data
reconciliation, and transaction reconciliation. Data reconciliation
sends the final results of changes in one systems' data
to the target system's data store. Therefore, if a certain data
element's value changed from A to B, then B to C, and finally C to D, only
D would be sent to the target application. The target application does not
see the events that led the data element to change -- it only sees the end
state. Business rules can be applied only to the
end-state of the data element to ensure its integrity. Any combination of
valid and invalid state transitions that lead to a valid end state is
acceptable.
In transaction reconciliation, the target application receives all three individual transactions that caused the data element to change -- A to B, then B to C, and C to D. The target application is able to apply business rules to each individual state transition, rather than just the end-state.
An architecture based on transaction reconciliation provides greater flexibility for the future. In addition to letting you apply business rules to each transaction, transaction reconciliation provides better support for synchronous, straight-through processing of cross-application transactions. Furthermore, transaction reconciliation lends itself well to a data or message broker solution. Reconciliation of data elements tends to lock you in to the data reconciliation model of application integration.
Conclusion
There really is no single solution that represents the best application
integration architecture in every circumstance. The best thing is to
develop a clear understanding of your requirements, and to know your
environment. Recognize the characteristics and limitations of each of
these integration models, and begin building your architecture from there.
![]()
|
|
Resources
About the author
![]() Sam Wong is a technology director and principal architect with Cambridge
Technology Partners.
Reach Sam at sam.wong@sunworld.com.
Sam Wong is a technology director and principal architect with Cambridge
Technology Partners.
Reach Sam at sam.wong@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-06-1998/swol-06-itarchitect.html
Last modified: