How do you manage systems growth?
Capacity planning involves predicting your future disk space, computing power, memory, and network bandwidth needs. Where do you start?
June 1998
|
|
How do you manage systems growth?Capacity planning involves predicting your future disk space, computing power, memory, and network bandwidth needs. Where do you start?
|
June 1998 |
System resources are always running low. With good capacity planning, you'll be able to look into the future and solve problems before they occur. Chuck covers the four key areas of capacity concern and offers advice for appeasing your users while staying in your CFO's good graces. (2,800 words)
|
Mail this article to a friend |
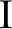 t's an old truism in the production computing business: The more
you give your users, the more they'll want. Roll in a new machine that
far exceeds your current computing power, and users will rise to the
challenge -- by consuming everything you have and demanding even more.
Adding disk space often seems futile, as users come up with more and
more ways to absorb everything you've got. Even network expansion
is hopeless: Replace those creaky 56-kilobit leased lines with a
new T3, and users who previously sent two e-mails per week suddenly want
broadcast-quality video feeds.
t's an old truism in the production computing business: The more
you give your users, the more they'll want. Roll in a new machine that
far exceeds your current computing power, and users will rise to the
challenge -- by consuming everything you have and demanding even more.
Adding disk space often seems futile, as users come up with more and
more ways to absorb everything you've got. Even network expansion
is hopeless: Replace those creaky 56-kilobit leased lines with a
new T3, and users who previously sent two e-mails per week suddenly want
broadcast-quality video feeds.
The worst part of this business is that it's your job, like it or not, to anticipate these demands and have capacity available just before the users demand it. Bring it online too soon, and you're wasting precious capital, much to the displeasure of your CFO. Deliver too late, and the users will have your head for getting in the way of their business needs. Hitting the mark is a trying task, requiring good planning, the right architecture, and a direct line to the Psychic Friends Network.
Breaking down capacity
Capacity is capacity, regardless of the system you're running. All
the rules that help mainframe shops plan for the growth of their
systems apply when managing the growth of your Unix machines. Every
system, regardless of architecture (and even pretend computers
running NT) deals with the same four areas of capacity concern.
Disk space
When planning capacity, disk space is usually the first
resource that comes to mind. Of all the components of a computing
environment, disk space (and the lack thereof) is most visible and
painful to your end users. That's because disk space has very
little flexibility. When the system runs low on memory, computing
power, or network bandwidth, most jobs continue to run, albeit more
slowly. When the disk space runs out, the system grinds to a halt,
waiting for more space to be brought online.
At first blush, providing enough disk space is just a matter of installing enough disk drives. Effective disk storage involves far more. The aggregate bandwidth of your disk subsystems, the redundancy of your storage devices, and the ease with which you can add additional space are critical factors when designing your systems.
For example, you could satisfy a user's request for 50 gigabytes (GB) of storage with three 18-GB drives. Unfortunately, that user might be running a database with an aggregate throughput that requires many heads moving in parallel. You'd be better off with six 9-GB drives (or even thirteen 4-GB drives). Did you design enough disk controller bandwidth to handle that many drives?
Computing power
We're dealing with raw computing testosterone here: MIPS, and plenty
of 'em. You can never have enough, and every new software package,
custom application, and operating system release is stealing more
cycles away from you.
Unlike disk space, which is rarely shared, CPU capacity is constantly shifting between users. You can often mitigate demand for CPU power by shifting certain job streams to different times of the day, or incentivating users to move their load to non-peak hours. Even when things get tight and overall performance suffers, many users can tolerate the slowdown for a reasonable amount of time, giving you some breathing room to fix the problem.
CPU upgrades are usually well thought out events, occurring with much fanfare and expense. When designing a system for CPU capacity upgrades, it helps to really understand your vendor's growth path for your product line. While most systems offer some growth, at some point you will hit the limit of the current architecture. Expansion beyond this point is much more painful, so you want to avoid hitting that limit.
Memory
System memory is a close adjunct of processor capacity, directly
impacting performance by controlling the amount of swapping that
goes on in a system. Often, you can resolve a CPU performance issue
by throwing more memory at it. However, without the right metrics, it can be
difficult to know if a system problem is due to a slow processor or
insufficient system memory. This is especially true in database
environments, where shared memory segments can grow into the
hundreds of megabytes (MB).
Like CPU expansion, memory expansion is directly tied to the system architecture. If you bought a system chock-full of memory, you have nowhere to expand. Even if you left slots open for extra memory, you might have the wrong memory devices installed. Many systems have SIMM dependencies that couple new expansion to the size of existing memory devices. It's difficult to explain a memory upgrade that involves throwing away those old 32-MB SIMMs so you can fit in enough 128-MB SIMMs to accomplish your upgrade.
Network bandwidth
Network issues are somewhat unique to the Unix and client/server
world, if only because the advent of client/server computing has
placed unprecedented demand on your network architecture. Network
capacity directly affects response time and is a major contributor
to end user satisfaction. Very few applications crash and burn
because the network slows down, but many users will do a slow burn
when they hit Enter and nothing happens.
The most important part of network capacity management is to create expandable infrastructure. Woe to the systems planner, who saved a bit of money by installing Category 4 wiring, when it comes time to start delivering 100 megabits per second to the desktop. Similarly, buying your main routers and hubs with no additional expansion slots makes it impossible to break up collision domains and distribute traffic across multiple subnets.
The good news is, there's nothing special about any of these resources. With appropriate planning and system design, you can stay ahead of your users, if you can guess where they are going.
|
|
|
|
|
Planning for capacity
Capacity planning starts the day you decide to buy a computer.
While many people focus on how big a system is needed to handle the
current computing load, your real focus should be on the system
you'll need two or three years from now. Keep in mind that you
don't want to buy all that capacity now; you just want to be able to
add it easily as it's needed.
For disk capacity, you need to make sure that you're buying enough bandwidth between your system, the disk controllers, and the drives themselves. Except for the smallest applications, you'll probably be using some form of RAID technology to create huge disk farms. Don't try to go the cheap route, using generic SCSI drives chained together to provide lots of storage. This JBOD (just a bunch of disks) solution may deliver capacity, but it rarely provides performance.
Instead, look for high-bandwidth solutions using intelligent disk controllers, Fibre Channel connectivity, and redundant disk architectures. Products like Data General's Clariion units, EMC's Symmetrix product, and Sun's StorEdge product line all offer high-bandwidth connection technology, smart disk controllers, and ample room for growth. With any of these units, buy a system that lets you satisfy your current space needs while leaving the chassis at least half empty. Otherwise, you'll be caught short when the need arises.
CPU and memory needs can only be met by buying a system that has plenty of room for growth. It may be that you can handle all your current processing with a two-processor desktop server, but without additional slots for extra processors, you'll have nowhere to turn when you run out of steam. It makes sense to buy a system with a faster backplane and more expansion capacity, and only use a fraction of that capacity when you first get it.
Network needs can be met in a similar fashion, by installing the latest infrastructure whenever you get the opportunity. Wire is very expensive to pull and is rarely recovered, so make sure you lay in the very best whenever you get the chance. Similarly, buy routers, switches, and hubs with appropriate scalability. This will allow you to add more network ports or increase your aggregate throughput with simple board swaps.
The bottom line, regardless of the system component, is to avoid a "forklift upgrade" for as long as possible. Forklift upgrades originated in the mainframe world, where the only way to upgrade was to remove the old machine and bring a new one in, all with the aid of a forklift. With the many capacity expansion options available in today's systems, you need not own a forklift to keep your systems ahead of user demand. By buying open slots, drive bays, and network bandwidth now, you can ease through several incremental capacity expansions before having to replace your existing systems. Best of all, by deferring that major upgrade for several years, you ensure that the overall price of the replacement system will have dropped significantly.
This begs the real issue. All of this costs money, and the battle for capacity planning is often won or lost in the accounting department. If you cannot adequately justify the need for capacity as opposed to capability, you will never have a chance of meeting your users' needs. When the system runs short of disk space, complaining about your shortsighted financial department rarely helps.
The best way to win the budget battle is to get involved with your users from the very beginning. Most users can barely keep up with today's problems, let alone predict tomorrow's, but you'll need to help them through the process. Even wild guesses as to their future needs will go a long way toward justifying your need for that extra large backplane or additional disk cabinet. Working through these issues now will also give you an idea where your users will be in a few years, which will help you anticipate your next capacity add. In more than a few cases, your users will predict greater usage than even you thought possible, and you'll have saved yourself some future heartburn by surfacing that need early in the system design process.
Acquiring metrics
Assuming you've built a system with some expandability, how will you
know when to expand? The key is data, data, and more data.
Mainframe systems have long had robust job-accounting and systems-monitoring tools that both provide a snapshot of the current system state and save an audit trail of past activity. Using this audit trail, you can see where your past peak usage periods are and try to predict when you'll need to add capacity.
In general, systems-monitoring tools for the Unix environment offer most of the features you'll find in mainframe systems. These include the ability to snapshot system metrics, and in some cases will allow you to draw pretty pictures that even your boss can understand. Products like Platinum's CIMS, Compuware's EcoSCOPE, and others offer a wide range of system agents and analysis tools that can help predict future system needs. While the features may vary from tool to tool, they all have one thing in common: they're expensive.
In reality, all of these tools examine the same system resource metrics that you can get at with traditional Unix commands like sar and df. You may not get fancy reporting, but you'll still be able to spot the same trends, and with a little spreadsheet effort, generate graphs to explain those trends to others.
A simple way to gather long-term metrics involves starting a new sar command every night at midnight, telling it to capture data every 10 minutes or so for a full 24-hour cycle. Write the results to a file unique to the current date, so you'll wind up with a file for each day of metrics you capture. While you'll be capturing a lot of data, the disk expense is minimal: sampling every 10 minutes for 24 hours creates 144 samples that might occupy 6 or 7 kilobytes of disk space. That 10-minute window is also unobtrusive to the system -- you don't want to alter system performance by sampling too frequently.
There are dozens of options to sar; select the metrics you wish to capture. If you are trying to see many different things (CPU, disk, and network activity, for example), you might want to consider running several commands, each focused on a specific set of system parameters. Each line of output from sar is timestamped, so it's easy to pull the resulting data files into a spreadsheet and create graphs quickly. A useful side effect is that you'll be missing files when your system crashes, which will help you quickly pinpoint when your outages occurred.
Once you have this data, whether from a fancy tool or from trusty old sar, what do you do with it? In the case of CPU or network data, you'll be looking for trends and patterns in usage, seeing when your system is loaded to 100 percent capacity and when you have a lot of idle time. For disk data, you'll be looking for general growth in disk usage, driven by growth in specific file systems. Often, a sudden jump in usage can be traced to just one or two users, perhaps creating a new database, or starting a new development effort.
When to grow and when to say No
Once you start collecting data, it's easy to jump the gun and add
additional capacity at the first sign of additional usage. This may
not be cost effective. You should always understand what is driving
usage to increase and try to mitigate the increase by working with
your users.
For CPU usage, you might try shifting the workload around. While you can see the entire system load, most users have no idea what other processing is occurring when they start a job. Many users are happy to discover that they can switch a job from noon to 3 p.m. and get things done in half the time. If the promise of faster turnaround isn't enough, structure your chargeback pricing (if you have it) to encourage people to run non-critical applications during non-peak hours. Geographically diverse users might benefit from shifting time zones, with East Coast users getting jobs run before West Coast folks even arrive at work.
Disk usage can often be traced to just one or two out of control file systems. Perhaps an application is suddenly writing huge log files, or a user has decided to start unloading tapes on your system. A brief chat with the user might help him or her see the light. General file system growth can often be stemmed by some general housekeeping, especially in development environments. At the very least, scrap those dated core files and backup copies.
After working with your users and helping them to help you, it's time to consider expanding your system. You may also find it useful to establish fixed thresholds that trigger upgrades. For example, you might buy additional disk space when you hit 80 percent capacity, or consider upgrading your CPU when the system runs at 100 percent for more than an hour in primetime. These thresholds make it easier to plan upgrades and justify new purchases to the accounting department ("We wanted to hold off on buying more disk space, but gee, we hit the 80 percent mark, and The Book says we have to buy more when that happens...").
If you worked things right with Accounting when you bought the system, you'll have budgeted the funds needed to buy the expansion you need. If not, you'll find yourself, hat in hand, at the CFO's doorstep, pleading for funds. With any luck, prices will have fallen since your last purchase, enabling you to buy more with the money you planned to spend.
Just as you did the first time around, make sure you buy enough expansion capability to see you through a reasonable period of time with the upgraded system. You won't get far if you're constantly nickel-and-diming your way through system upgrades. Again, it helps to have thresholds: Buy enough disk to get you back down to 50 percent capacity, or add CPU until the system is below 90 percent at any given time.
Growth happens
No matter what your approach to capacity planning, never forget that
the need for more is universal. A smart Unix system manager uses
the same rules, tools, and tricks that his or her mainframe counterpart has
been using for years to avoid growth when possible, to grow smart
when it can't be avoided, and to keep both the users and the accounting
department in the loop with regard to capacity management. If not, the only
capacity you'll need will be the cycles and storage to create and
print your resume.
![]()
|
|
Resources
About the author
Chuck Musciano has been running various Web sites, including the
HTML Guru Home Page,
since early 1994, serving up HTML tips and tricks to hundreds of
thousands of visitors each month. He's been a beta tester and
contributor to the
NCSA httpd project
and speaks regularly on the Internet, World Wide Web, and related topics. Chuck is
currently CIO at the American Kennel Club.
Reach Chuck at chuck.musciano@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-06-1998/swol-06-capacity.html
Last modified: