The physical data architecture
Taking data architecture to its final form
March 1999
|
|
The physical data architectureTaking data architecture to its final form
|
March 1999 |
Once your company has categorized, modeled, and evaluated its data, it has to provide the physical components necessary to store, transport, view, and analyze it. With this need comes the challenge of management, both of systems and of data, and the integration of sometimes disparate systems to gain value from each of the data domains within your organization. When it comes to data management, the physical data architecture is the aspect that most impacts CIOs and data managers, daily, as they try to meet these challenges.This month, IT architect Glenn Kimball discusses the movement from a logical view of data to its physical form and examines the issues that arise when tools and technologies are introduced to gain value from data. (3,200 words)
|
Mail this article to a friend |
Foreword
Much of the work of an architect focuses on creating application architectures, working on interfaces and integration architectures, constructing the infrastructure, or assisting with the addition of a packaged solution into the enterprise architecture. Regardless of the software and hardware, at some point we need to determine how data will be stored or transferred at a physical level. Our July 1998 column discussed the logical data architecture. This month, we focus on the physical data architecture. The topic is really too big to cover in one column, so we'll limit our focus to the issues associated with taking a logical model to a physical model.--Kara Kapczynski
![]() he database schema, whether in its purest form or in an abstracted form,
is probably the most recognized form of the physical data
architecture. In most cases, individuals from different parts of an
organization, whether they're technical developers or business users,
are familiar with databases and their function.
he database schema, whether in its purest form or in an abstracted form,
is probably the most recognized form of the physical data
architecture. In most cases, individuals from different parts of an
organization, whether they're technical developers or business users,
are familiar with databases and their function.
But the familiarity tends to be superficial. Most of these users lack an understanding of the deeper architectural components of such technologies, and the effects of their business needs on the use of such data. Specific items such as database servers, data replication tools, data transformation tools, and middleware all contribute to both the solution and the complexity of such systems. The needs of an organization often contribute to data management, quality, and availability difficulties as does the number of technologies employed, especially with the rapid speed of change in many markets.
Once you begin to meet the competitive needs of a company with enabling technologies and tools, you'll often encounter a quagmire of those difficulties that accompany a physical data architecture. The key to success in this situation is flexibility and planning, two concepts that often don't mix well, or easily.
The conversion from logical to physical
As the data architect for your organization, you must look at the
problem from both the top-down and the bottom-up. A solid
understanding of your individual database schemas won't provide you
the information you need to run the business, nor will a complete
knowledge of the business immediately translate into an
understanding of the data. It's easy for data architects to miss
this fine point, because we tend to be oriented toward a single
domain of tasks and often don't have the enterprise in mind.
For the sake of simplicity, we'll assume a green field approach in our discussion of the movement from a logical view of data to its physical form. I'll begin by describing the steps associated with the conversion from the logical data perspective to the physical data perspective, then I'll move into a discussion of the daily realities we face in our jobs.
First, let's revisit my colleague Nirmal Baid's July 1998 IT Architect column, which discusses the logical data architecture. The logical data architecture results in five major components:
In layman's terms, we start with three things: what data we have or want, where the data comes from, and who owns the data. In contrast, the physical data architecture has the following major components:
As you can see, physical data architecture has a number of individual technologies and techniques you must keep in mind when making the transition. The key to physical data architecture isn't only technology, but also how well you understand your data and its usage.
Conversion to the physical data architecture is a nonlinear process and, therefore, requires a significant amount of planning and coordination, as illustrated by Figure 1.
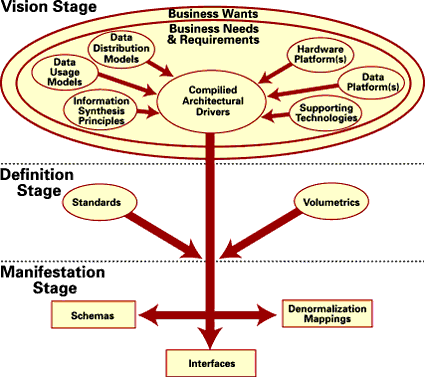
Figure 1. The physical data architecture process |
First, a pair of concurrent but related efforts must begin. The first half of our effort is centered in identifying the models and principles that define the use and positioning of data. We must also evaluate and identify the technologies that will support the data environment.
We begin by concentrating our efforts on the first three components: information synthesis; a data usage model; and a data distribution model.
Information synthesis examines how data is combined, aggregated, derived, and disseminated to provide useful information. The data usage model is a set of descriptions that surround each of the individual uses of data within the organization. The data usage mode is itself divided into two sections: the "nature" of the data (analysis oriented, decision support, management, reporting, transaction processing, etc.) and the orientation of the systems that support such usage, including transactional systems, operational data stores, data marts, or data warehouses. Finally, the data distribution model focuses on the positioning of data within the enterprise and the relative proximity of such data to its sources and its uses.
Next we try to align technologies with the needs of the organization. Given the nature of the data, its uses and distribution, different technologies need to be combined to provide real value to the end user. Remember, technology is useful only if it supports the performance, access, and functional needs of the end user. At this stage, we must evaluate the relational database management systems (RDBMS), multidimensional database systems, data access tools, data transformation technology, transaction monitors, online analytical processing tools (OLAP), and each of their related hardware platforms for need and fit. Simplicity is the rule here. The more technology we add to the mix, the more difficult it will be to support and, more importantly, effectively use the technology.
Once we've completed this step, the organization must develop and compile standards. These standards, however, cover all aspects of data, not just the code used to access it. Standards related to the physical architecture will often cover the hardware platform, database management system(s), access methods, abstraction methods, programming model, coding principles, interface agreements, data management processes, and technology choices. These standards are intended to achieve two major things: they provide a consistent approach to systems development, which helps organizations maintain a single orientation over systems, and they form the basis for technology selection.
In conjunction with these standards, we must develop an understanding of the volumes and activity around our data. Volumetrics aren't limited to the number of rows and their disposition within a specific schema; they include the following information:
These items allow you to size your hardware appropriately, and, more importantly, to understand the activity of the data, which in turn allows you to apply the proper technologies for the proper purposes. The use of volumetrics early on in the process is often an exercise in estimation, based on the data architect's experience, the enterprise's knowledge of its data at the current point of time, and even a little market analysis. Later on, your assessment will become more and more the result of access patterns and enterprise experience. It is extremely important that you spend the time to watch what is happening to your data. I can't stress this enough.
Now that we have the standards and volumetrics in place, we must apply the technologies such that they solve real business problems and not just a set of aggregated technologies. On this foundation, the next (and most recognized) components of the data architecture are built: the schemas and interfaces. Schemas are created from three major components:
An important, but often overlooked result of the denormalization stage is the denormalization mapping. The denormalization mapping will outline each of the denormalization steps taken to improve performance and provide useful data to the end user. An accomplished denormalization mapping will not only discuss the individual schema mappings, but will also cover such features across schemas. The denormalization mapping helps the enterprise prevent the loss of knowledge about how its systems derive information over time due to the loss of resources.
Finally, interfaces arise from the need to get or provide data to or from other systems -- not all data is sourced in those systems. The interface represents the conduit through which data can be transferred and combined to glean valuable information for the operation of the business.
|
|
|
|
|
Getting rooted in reality
As I mentioned earlier, our discussion thus far has been from a green field
approach. Let's inject a little reality at this point. The
reality is that green field approaches to data architecture are the
exception and not the rule. Most organizations come to us with
existing systems and practices. To make things even more difficult,
these organizations have adopted standards and technologies over time
that have been or must be combined to solve the needs of the
business. Further complications arise if the organization hasn't
maintained an architecturally focused approach.
Many large and medium-sized organizations have some combination of mainframe computer-, minicomputer-, or microcomputer-based systems, each with different types of data sources and applications, and different ways to view, manipulate, and get value from data. Some companies are embedded in worksheets and paper systems, while others have every brand and version of technology. To further complicate matters, the markets in which many of these organizations operate are constantly changing, so their individual data needs are changing right along with them. These changing data needs are often solved by combining disparate data in order to analyze and compare the operations of the business.
Figure 2 is representative of many existing systems today. I want to stress the problems that can accompany such environments when multiples of the topography are found, especially if each manifestation employs different vendors and technological choices.
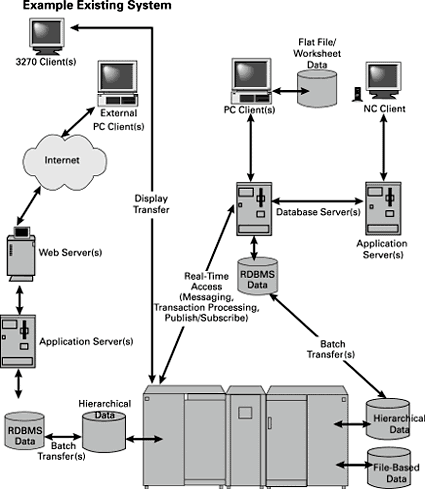
Figure 2. An example existing system |
One of the most tedious but important factors in your job as a data architect is to approach the situation in an organization with limited or no architectural purview or influence, and shift the enterprise from a state of disarray into a state of stability. You must keep your finger on the pulse of both the business and the technology ends of the organization in order to orient and drive the use of technology and data to solve the business needs at hand. All this while trying to stave off the various technology choices the different sections of the organization are choosing to meet their specific needs. For this reason, I strongly suggest that you be as cognizant of the business needs and risks of the organization as you are of the technology needs and risks.
Caveat Emptor: Remember to regularly revisit and adjust your logical data architecture. Data architects are notorious for focusing on the physical and forgetting what truly drives their jobs. You threaten the value of all of the logical work you've done to date if you don't care for the "roots" that got you where you are today.
The path to simplicity
So, you ask, how do we solve the difficulties of complexity and
disarray? The answer isn't as simple as I would like it to be. The
key to success in this arena is understanding how to balance the
technological exposure generated by each business need against its
corresponding business benefit. Here are some rules of thumb to consider:
In what I call the physical data practice:
In what I call the technology practice:
The move to a stable, simplified, integrated, and valuable data architecture takes time. Wholesale change to correct this type of environment won't come quickly and is unlikely to be acceptable to the organization from a cost and change-management perspective. The most successful efforts generally focus on long-term implementation. Here are the key factors that will move your organization and architecture forward:
Practical design and performance
Often the biggest factor behind a successful design is the architect's
understanding of the business and the business issues driving the design. Even
the most seasoned individuals in an organization won't always see
changes in the outside business model and how those changes will affect their
business. The key on the business side of design is to solve the
current business needs and provide a flexible process for the
incorporation of new needs.
From a technology perspective, the biggest roadblock to success is produced by two key factors: technological complexity and skill sets. Balancing the introduction of supportable technologies that fit the business need without increasing the technological risk of the system requires constant verification effort, both during and after design. The following items represent specific risk areas and my strategy for handling them effectively.
Interfaces: Concentrate on your interfaces. I talk about interfaces in a holistic fashion here and include data transport, transformation, validation, error handling, protocols, and middleware technology. Interfaces tend to be the "root of all evil" in system design. Solid technology platform and code will help to eliminate many recurring quality, access, and processing issues. The integration of a series of systems and the transfer of data between them is the most significant issue impacting operations.
Abstraction layers: The recent move to abstraction layers has afforded data managers the ability to minimize integration efforts. This goal, although well placed, is at the expense of performance in most cases. Avoid overusing abstraction layers as a silver-bullet solution to data access; a better approach is to concentrate on solid standards and practice in design and development.
Data transformation: Avoid transforming data if at all possible. Once again, simplicity of structure and data will lead to benefits later on. If data transformation is completely unavoidable, I recommend you solve this and other related problems with a single solution and then make a point to eliminate the need for such efforts (to the degree possible) over time.
Data access: The single most preventable issue with RDBMS applications is how you write your SQL or other data access query sets. Make sure that whatever data access mechanism you use is used in the appropriate manner. Given a path of performance improvement, I always address the data access mechanism first, the platform second, and the product architecture (kernel) last.
By applying the above approaches with the guiding principle of simplicity you can gain marked improvements in your system's ability to meet the needs of your end user, support organization, and information technology resources.
The new millennium
This may come as a shock, but there are still a fair number of
organizations that don't see how the Internet will affect their
businesses in the future. It's up to you, the data architect, to be
able predict and understand how changing technology
and business practices will affect the data architecture. Most
recently many businesses have seen a fundamental shift in how they
interact with their customers and business partners. A major trend in
many industries today (be they banking, insurance, high-tech, or
others) is dissemination of information to customers and
partners via the Web.
This trend represents the next major hurdle for the enterprise data architect. The use of outsourcing models, customer information services, and so on will eventually force most organizations to deal with pushing information into public space. This trend will have a significant effect as the audience for the information increases and the organization's data is exposed to a relatively new distribution mechanism.
The two major exposure points that immediately come to mind are the issues of security and scalability. No longer do we have the luxury of using simple security features to protect our organizations. We now have the potential of huge populations of individuals and organizations that want access to data, and that data must be disseminated only to the appropriate parties. Another risk that comes with this trend is the ability to accept and service the requests from this burgeoning population. The reality for the data architect is as follows: Don't underestimate the impact of the Internet on your business even if you don't think it fits into this area, it probably does and you just haven't seen it yet.
Conclusion
I've spent much of my time this month focusing on the physical data
architecture effort without spending significant energy on specific
issues that arise with such situations as very large databases
(VLDBs) and the Internet (and extranets), and specific modeling,
interface, and RDBMS issues. In a future article, I'll delve into
these issues which affect the lowest levels of the data world.
Beware, the discipline of data architecture isn't for the weak of
heart. The efforts that surround successful data architecture are
numerous and often interrelated. The efforts you encounter will go
beyond a pure modeling orientation and force you to deal with some
subjects that may seem mundane or uninteresting. It is your dedication
as a data architect that will make or break the end result.
![]()
|
|
Resources
About the author
![]() Glenn Kimball is a chief technology architect with Cambridge Technology Partner's
North America Technology Organization (NATO). NATO is the premier team of
technologists for the firm.
Glenn Kimball is a chief technology architect with Cambridge Technology Partner's
North America Technology Organization (NATO). NATO is the premier team of
technologists for the firm.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-03-1999/swol-03-itarchitect.html
Last modified: