The logical data architecture
Building a blueprint of your company's most valuable asset
July 1998
|
|
The logical data architectureBuilding a blueprint of your company's most valuable asset
|
July 1998 |
There are essentially two ways of talking about the way data is managed in your company. You can talk about the physical architecture -- the applications, tools, and middleware -- but there is also an important logical data architecture -- the blueprint of the data within your company -- that must be considered.This month, Nirmal Baid introduces the concept of a logical data architecture and explains how to develop and maintain it. (2,900 words)
|
Mail this article to a friend |
ForewordData architecture is one of the fundamental components of the enterprise technology architecture. Most developers are familiar with the application architecture's data design -- determining what data is needed for a particular application. At an enterprise level, we need to look at how data is managed, accessed, and stored in databases across multiple applications in an organization. The data infrastructure is an area that needs to be architected. Organizations that have users screaming for data, or claim it's impossible to create a complete customer list from their combined databases, do not have a well-designed data infrastructure. This month, Nirmal Baid covers logical data architectures. In subsequent columns we'll take a look at the physical aspects of databases.
--Kara Kapczynski
![]() henever people talk about data architecture, they tend to focus on physical things, like database servers, data replication tools, or middleware: the physical data architecture. Now these are all important issues, but they tend to overshadow an important area -- something I call the logical data architecture.
henever people talk about data architecture, they tend to focus on physical things, like database servers, data replication tools, or middleware: the physical data architecture. Now these are all important issues, but they tend to overshadow an important area -- something I call the logical data architecture.
The distinction between the physical and logical architectures isn't artificial. Putting together these different architectures means considering different issues, and it requires two completely different sets of tools and skills.
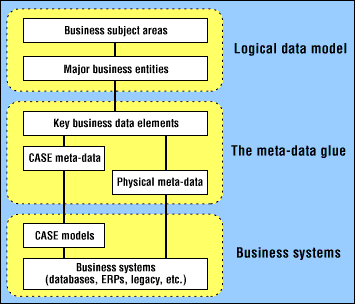
I'm going to focus on what you need in order to put together the logical data architecture. This includes things like enterprisewide data models, the meta-data catalog, and notions of data ownership.
So what am I talking about?
What is the logical data architecture? It's really a blueprint of the data in your entire organization, irrespective of platform, operating system, file structure, or database technology. It defines your entire data landscape.
And what does this architecture buy you? Most data architects must answer this question at some point, because the work they do often sounds so fuzzy and intangible. In the enterprise, a well-defined data architecture provides you with a roadmap of all the data in your company, for both IT and business users. Developing the data architecture helps you better understand your data, which ensures that your company is more efficient at meeting current business needs and better able to exploit new opportunities.
This improved understanding will help your company grow. With it, you can more effectively design new business systems and better share data across the company.
Say you're initiating a new data warehousing solution. The business analysts need information about data elements (a single property of an entity) across the operational systems so that they can know what kind of reporting will be possible from the current applications. On the other hand, the developers want to know where all these data elements physically reside, and in what form, so that they can realistically estimate how easy (or difficult) it will be to extract and report on the data elements. The logical data architecture is the glue that ties the business data entities to their physical manifestation, over time and across heterogeneous applications.
Putting the logical data architecture together
Logical data architecture for an enterprise is comprised of five major components:
The logical data architecture needs to be approached from both the top down and the bottom up. The bottom layer -- the existing systems in your organization -- has to be considered as the foundation. At the same time, you don't want to be restricted by your current systems' data and let that alone drive your modeling effort.
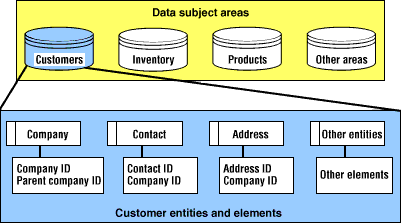
Begin the top-down approach by identifying each of your major business subject areas and the main data entities within each subject area. Subject areas are high-level groupings of the business data entities. For example, customers, products, finance, pricing, inventory, and such. Be careful not to go too low level -- for example, a customer address is not a subject area -- and stay consistent across various business functions.
So, what's an appropriate number of subject areas for a logical data model? It depends. As a rule of thumb, look for 20 to 40. If you have too many subject areas, you lose the purpose of rolling up the data elements in meaningful buckets of information. If you have too few, too much information is being grouped under one heading.
The logical data architecture |
The next step is to identify major data entities in each of these subject areas. This is where you examine the existing systems to come up with the major data entities and their key attributes. Try answering this question for each subject area: What information do we want to maintain in this business function? You do not want more than 30 to 40 entities in one subject area. If you have less than 10 entities in a subject area, look for opportunities to merge it with another. If you come up with more than 40, think about splitting it in two.
Remember, we're talking about high-level business data entities that can collectively describe the business function, not every single table we've implemented or plan to implement. It's very important that the identified business entities are evaluated to ensure that they represent a business entity (e.g., customer) as the business perceives it and are not completely driven by the systems. We stop in our top-down journey here.
|
|
|
|
|
The catalog
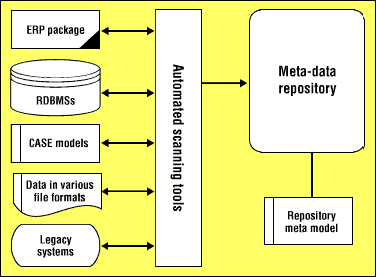
The next stage is to analyze the existing business systems in a bottom-up approach, by examining all the heterogeneous databases and file formats that store your data. The issue here is how do you collectively document all the data in a coherent manner? This is where data repositories come to the rescue. A data repository helps us take the system inventory in an integrated fashion across the myriad of platforms, databases, and file structures. By system inventory, I mean all the meta-data, or the data about the data, that is stored in each of the business systems. There are commercial off-the-shelf products available that can automate the process of meta-data collection by periodically scanning the data dictionaries of the DBMSes, ERP packages, various data files, CASE tools, and such. The meta-data collected in a data repository is the second building block for the logical data architecture.
The Catalog |
In order to effectively utilize the data repository as part of the overall data architecture, you will be faced with a number of questions, including:
The answer to these questions depends on the nature of your enterprise system environment and development methodology.
Data element rationalization
Now that you've built a high-level business data model and collected all of the system meta-data, where do the two meet? The system meta-data forms the bottom layer of the logical data architecture, and the business-data model forms the top layer. Next, you need to go through an exercise called data element rationalization to actually build the middle layer. This will glue the data model and the meta-data together.
In data rationalization, similar data elements from various systems are mapped to the key business data attributes. For example, you would need to make sure all different customer IDs are mapped to the same data element, defined in the logical data model. The CUST_ID in the Oracle tables of the sales systems, CUSID in the COBOL files of a legacy system, and Customer_ID in the ERP system would all be represented by the same key business element, called Company ID, for example. This is not an easy exercise, but it offers many benefits:
|
Benefits of data element rationalization
Data record rationalization
Even after you've done data element rationalization, you still haven't solved all the integration issues. The next major issue will be to map the specific data values from various systems. This is what I call data record rationalization. In data element rationalization, the data was mapped at the meta-data level, but now you need to go one step further and identify that Cust_ID 1234 in the sales system is the same as the name "Acme Corporation," which is the same as Customer_ID 5476 in the ERP system, which is the same as the name "ACME Inc."
This is a painful but inevitable exercise if you want to share and integrate data across business systems. There are many vendors who can help with this kind of data standardization for specific data elements (addresses, for example). Using standard industry codes like Dun and Bradstreet's will help you here. I've seen companies build separate database applications just to map the IDs from various business systems and develop a data-cleaning module on top. This process could cost as much as one of the original systems.
The key here is to do this sooner rather than later and to build new systems that align with your logical data architecture. An ounce of prevention is worth much more than a pound of cure.
Enterprise data sources
When new applications are designed they invariably have system interfaces to other business systems for both in- and out-bound data feeds. One of the important phases during application design is identifying which business systems are going to feed the new application its data. In the real world, most common data -- customer information or product details -- is carried by more than one business system. The question you must answer is: How do you determine which system is the right data source for your application? Do you choose the most convenient source? If you're also sourcing some other data, is it possible to consolidate the extraction process?
Often, it may seem appealing to source data from a replicated copy for the sake of short-term convenience, especially if you have small databases that consolidate and report information from various sources. The problem with this is that the horizontal partitioning (the "where" clause) of the replicated system may not be what you need. In other words, even if the replicated system has all the data elements you need, it may not have all the right data records. And even if it does meets your requirements today, you can't be assured that this won't change tomorrow. In fact, I promise you it will! So try to use only one data source.
To define your data sources, first determine how you want to divide up your major business entities and then note which business system will supply this data. For example, take a customer revenue business entity: The horizontal partitioning of that entity would be the POS (point of sale) customer revenue and distributor customer revenue. More than likely the two will reside in different applications. Let's say one is called POS and the other is called Channels. In the future, all new applications must source revenue numbers for POS customers from the POS application, even though these numbers may also be available from other applications.
Many IT departments have implemented operational data stores (ODS) to facilitate data extraction and sourcing process. An ODS takes a snapshot of the data from the operational systems at predefined intervals. Even if an operational data store (ODS) is implemented, the data sources must still be defined in terms of the actual business systems. The reason for this is that the original system will change its data design over time. You need to be aware of this so that you can reflect the changes in your system as necessary. Also, the data store may or may not have the all the data your application needs. So you need to examine the original source first and then send your requirements for extracting the data to the ODS.
Be careful in identifying the data sources for only selected business entities because of maintainability issues. You might have 500 business entities in your model, but you don't want to identify data sources for all of them. What you really want to do is identify the sources for highly shared objects. If you have too many data sources, it becomes unmanageable. And besides, having 500 data sources may not be very useful.
The data architect must keep the list of data sources current with the changing business system scene. Otherwise, people will lose confidence in the system's accuracy, and they won't use it.
There are many advantages to this architecture component. For one thing, it helps alleviate the pain of integrating complex data designs for new applications because it provides a starting point for systems interface design. Second, it promotes sharing and reuse of the key business data from your enterprise sources. This gives you a bigger bang for your buck.
Enterprise data stewards
A major benefit of defining your enterprise data model and data sources is that doing this becomes the first step toward identifying the data stewards for the key business data. The data steward makes sure that the data is shared and integrated across business systems appropriately. The data steward is also responsible for approving any major changes to the data definitions. The data stewards need to work very closely with the data architect group and provide significant input in the development of the logical data architecture. Ideally, there's one data steward for each data subject area, who ensures responsible use of that data across the enterprise.
There are two major issues with the data steward role: One is that the data stewards are usually business managers who have this role as only a part-time job. They already have their regular, high-priority responsibilities to perform, which hinders their capability to act as data stewards in an effective manner.
In order to mitigate this issue, it's important that these managers keep the data steward job high on their list of priorities. They should be getting a high level of support from their peers and superiors, as well, to make the job easier.
The second issue is that the role of data steward is not often integrated into the application development life cycle. As a result, you get data stewards who are not constantly aware of the issues around the data that they are stewarding. One of the most common ways of circumventing this problem is to make the data steward the most important sign-off for any system interface design that involves data from her subject area. Many corporations go as far as to document the data mapping between systems on a template and get actual signatures from the source's data steward as well as that of the business owner of the target system.
Planning for the future
Here are some steps that your IT department should take toward building the logical data architecture. They will also help you plan ahead and align your new applications with the logical data architecture:
If senior management doesn't buy in right away, ask them this: "We have data. Our competitors have data. So who has the advantage?" The obvious answer is: The one who can exploit his data the best. And the logical data architecture can give your company an enormous advantage in making this happen.
![]()
|
|
Resources
About the author
![]() Nirmal Baid is a technical specialist focusing on data architectures at Cambridge Technology Partners.
Reach Nirmal at nirmal.baid@sunworld.com.
Nirmal Baid is a technical specialist focusing on data architectures at Cambridge Technology Partners.
Reach Nirmal at nirmal.baid@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-07-1998/swol-07-itarchitect.html
Last modified: