How to optimize caching file accesses
How can you tell if the caches are working well and how big they should be? How can you tune applications together with the caches? We show you
March 1997
|
|
How to optimize caching file accessesHow can you tell if the caches are working well and how big they should be? How can you tune applications together with the caches? We show you |
March 1997 |
Following on from last month's discussion of local disk accesses, this column looks at networked access. Accessing a file over a network is hundreds of times slower than reading a cached copy from memory. Many types of cache exist to speed up file accesses. Changing your workload to make it more "cache friendly" can result in very significant performance benefits. (2,500 words)
|
Mail this article to a friend |
Q:
I know that files are cached in memory, and there is also a cache
file system option. How can I tell if the caches are working well and
how big they should be? How can I tune applications together with the
caches? Are you finally going to tell me about cachefs this month?
--Tasha in Cashmere (for the third time)
A: So far we looked at general cache principles and the caches used by local file access. This month I'll cover NFS and cachefs.
Recap on caches
The principles of caching and the name service cache were covered in
detail in January's article. And we gave a brief recap of caching at
the beginning of February's Performance column.
(See Resources below for links to these past columns.)
So you've already learned that caches work on two basic principles: The first principle is called temporal locality, and depends on reusing the same things over time. The second principle is called spacial locality and depends on using things at the same time that are located near each other.
A cache works well if there are a lot more reads than writes, and the reads or writes of the same or nearby data occur close together in time. An efficient cache has a low reference rate (don't make unnecessary lookups), a very short cache hit time, a high hit ratio, the minimum possible cache miss time, and an efficient way of handling writes and purges.
A special kind of cache can be used to accelerate writes. Write caches use the same principles of temporal and spacial locality in a slightly different way. Temporal locality applies when writes to the same thing happen close together in time. The write cache waits a while after each write so that if another write to the same data comes along it can combine them together into a single coalesced write at a later stage. Writes that have spacial locality allow adjacent writes to be coalesced into a single larger write that is much more efficient to process.
|
|
|
|
|
Tasha: Here's how NFS access caching works
We'll start by looking at the simplest configuration, the open,
fstat, read, write, and mmap operations on an NFS
mounted filesystem. Compared with last month's diagram of Unix File
System (UFS) access caching, the diagram has been split in the middle,
pulled to each side and divided between the two systems. Both systems
contain an in-memory page cache, but the NFS filesystem uses an
rnode (remote node) to hold information about the file.
Like the UFS inode cache, the rnode keeps pointers to
pages from the file that are in the local page cache.
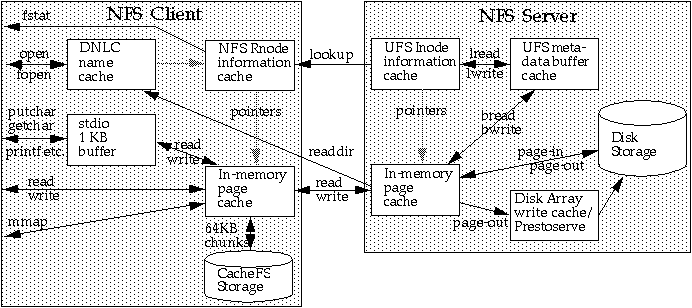
Unlike the UFS inode, it does not contain the disk block numbers; it
holds the NFS file handle instead. The handle has no meaning on the
client, but on the server it is used to locate the mount point and
inode number of the file so that NFS reads and writes can go directly
to the right file on the server. An NFS file open on the client causes
a Directory Name Lookup Cache (DNLC) lookup on the client. If the file
is not found, it causes a DNLC lookup on the server that sets up both
the DNLC entry and the rnode entry on the client.
There are a lot of interrelated caches. They are system-wide caches, shared by all users and all processes. The activity of one cache-busting process can mess up the caching of other well-behaved processes. Conversely, a group of cache-friendly processes working on similar data at similar times help each other by pre-filling the caches for each other. The diagram shows the main data flows and relationships.
Using the rnode cache
The lookup NFS call returns the rnode information about a
file. This includes its size and datestamps, as well as the NFS file
handle that encodes server mount point and inode numbers that uniquely
identify the file. Every concurrently open file corresponds to an
active entry in the rnode cache, so if a file is kept
open, its information is locked in the rnode cache and is
immediately available. A number (set by the tunable
nrnode) of rnode entries are kept.
nrnode is set to twice the value of ncsize.
It doesn't normally need tuning, but if the DNLC is increased,
nrnode increases as well. DNLC entries are filesystem
independent, they refer to entries in the UFS inode cache as well as
the NFS rnode cache.
There are several NFS mount options that affect the operation of NFS
data and attribute caching. If you mount mail spool directories from an
NFS server, you might have seen a warning message that advises you to
use the noac option. This turns off attribute and write
caching. Why would this be a good idea?
The access pattern for mail files is that sendmail on
the server appends messages to the file. The mailtool on an NFS client
checks the file attributes to see if new mail has been delivered. If
the attributes have been cached, mailtool will not see the
change until the attribute timeout expires. The access pattern of
sendmail and mailtool involves multiple
writers to the same file, so it is not a good idea to cache written
data on the client. This highlights two issues: One is that with
multiple clients there may be multiple copies of the same data cached
on the clients and the server, and NFS does not enforce cache coherency
amongst the clients. The second is that in situations where the cache
is of no benefit, it can be disabled. See the
mount_nfs(1M) manual page for full details on the
attribute cache timeout options.
How the in-memory page cache on an NFS client
works
When we talk about memory usage and demand on a system, it is actually the behavior of this cache that is the issue. It contains all data that is held in memory. That includes the files that make up executable code and normal data files, without making any distinction between them. A large proportion of the total memory in the system is used by this cache as it holds all the pages that make up the current working set of the system as a whole.
All page-in and page-out operations occur between this cache and the
underlying filesystems on disk and over NFS. Individual pages in the
cache may currently be unmapped (e.g. a data file), or can be mapped
into the address space of many processes (e.g. the pages that make up
the libc.so.1 shared library). Some pages do not
correspond to a named file (e.g. the stack space of a process); these
anonymous pages have swap space reserved for them so that they can be
written to disk if required. The vmstat and sar
-pg commands monitor the activity of this cache.
The cache is made up of four-kilobyte or eight-kilobyte page
frames. Each page of data can be located in a filesystem (local or
NFS) or swap space datablock, or in memory in a page frame. Some page
frames are ready for reuse or empty and are kept on the free list
(reported as free by vmstat). A cache miss occurs when the
page needs to be created from scratch (zero fill fault), duplicated
(copy on write), or read in from disk or over the network (page-in).
Apart from the page-in, these are all quite quick operations, and all
misses take a page frame from the free list and overwrite it.
Page-out operations occur whenever data is reclaimed for the free list due to a memory shortage. Page outs occur to all filesystems, including NFS, but are often concentrated on the swap space (which itself might be an NFS mounted file on diskless systems).
Using the disk array write cache or
Prestoserve
When the client system decides to do an NFS write, it wants to be
sure that the data is safely written before continuing. With NFS V2,
each eight-kilobyte NFS write is performed synchronously. On the
server, the NFS write can involve several disk writes to update the
inode and indirect blocks before the write is acknowledged to the
client. Files that are over a few megabytes in size will have several
indirect blocks randomly spread over the disk. When the next NFS write
arrives, it might make the server rewrite the same indirect blocks. The
effect of this is that writing a large sequential file over NFS V2
causes, perhaps, three times as many writes on the server, and they are
randomly distributed, not sequential.
The network is idle while the writes are happening. This explains why an NFS V2 write to a single disk will often show:
There are several possible fixes for this. Increasing the amount of data written per NFS write increases throughput, but eight kilobytes is the practical maximum for the UDP-based transport used by older NFS2 implementations. Providing nonvolatile memory on the server with a Prestoserve or a SPARC Storage Array greatly speeds up the responses and coalesces the rewrites of the indirect blocks. The amount of data written to disk is no longer three times that sent over NFS, and the written data can be coalesced together into large sequential writes that allow several megabytes per second to be sustained over a 100-megabit-per-second network.
NFS V3 and TCP/IP improvements
Two NFS features were introduced in Solaris 2.5. The NFS Version 3
protocol uses a two-phase commit to avoid the bottleneck of
synchronous writes at the server. Basically, the client has to buffer the
data
being sent in case the commit fails, but the amount of outstanding
write data at the server is increased to make the protocol more efficient.
As a
separate feature the transport used by NFS V2 and V3 can now be TCP as well
as UDP. TCP handles segment retransmissions for NFS, so there is no need to
resend the whole NFS operation if a single packet is lost.
This allows the write to be safely increased from eight kilobytes (six Ethernet packets) to 32 kilobytes (20 Ethernet packets) and makes operation over wide area networks practical. The larger NFS reads and writes reduce both protocol and disk seek overheads to give much higher throughput for sequential file accesses. The mount protocol defaults to both NFS V3 and TCP/IP with 32-kilobyte blocks where they are supported by both the client and the server although NFS V3 over UDP with 32-kilobyte blocks is a little faster on a "clean" local network where retransmissions are unlikely.
Finally: the cache file system
This was part of the original question, and I've finally gotten around to
discussing it! Cachefs was introduced in Solaris 2.3 and is normally
used to reduce network traffic by caching copies of NFS mounted data to
local disk. Once a cache directory has been setup with
cfsadmin(1M), file data is cached in chunks of 64
kilobytes for files of up to three megabytes total size (by default).
Bigger files are left uncached, although it may be worth checking the
sizes of commonly used commands in your environment to make sure that
large cache-mounted executables (e.g. Netscape Navigator) are not being
excluded.
When new data is read there is extra work to do. The read is rounded up to a 64-kilobyte chunk and issued to the NFS server. When it returns it is written to the cachefs store on disk. If the data is not subsequently reread several times this is a lot of extra work gone to waste.
Any data in the cache is invalidated by default when data is written. A subsequent read is needed to reload the cachefs entry on disk. This is not too bad, as there is a copy of the data being written in RAM in the page cache, so it is likely that subsequent reads will be satisfied from RAM in the short term.
Another issue is the relative speed and utilization of the local disk compared to the NFS server. A fast NFS server over a lightly loaded 100-megabit-per-second network with striped NVRAM-accelerated disks, could make cache misses faster than cache hits to a slow busy local disk! If the disk is also handling paging to and from a swap partition, the activity from paging and the cache may often be synchronized at the time a new application starts up. The best scenario for cachefs is when you have a busy low bandwidth network, as a reduction in network load can dramatically improve client performance for all the users on the network.
The best filesystems to cache are read only, or read mostly. You can
check the cache hit rate using the cachefsstat(1M) command
that was included in Solaris 2.5. For those of you running Solaris 2.3
or 2.4 -- you can't tell -- but I was getting between 97 and 99 percent
hit rate on a read-only application distribution NFS mount.
A development of cachefs is the Solstice AutoClient application. This lets you run systems with local disks as cache-only clients. They run the entire operating system installation from cache, avoiding the high network loads and low performance associated with diskless systems, but providing highly-automated, low-administration costs.
After three columns discussing caches, it's time for something
different next month. After all these years, users still have problems
understanding how free memory is used and can be tuned. I'll describe
the latest changes in the pager algorithm (introduced in Solaris 2.5.1
and back-ported in recent kernel patches) and describe how to decide if
it needs tuning.
![]()
|
|
Resources
About the author
Adrian Cockcroft joined Sun in 1988, and currently works as a performance specialist for the Server Division of SMCC. He wrote Sun Performance and Tuning: SPARC and Solaris, published by SunSoft Press PTR Prentice Hall.
Reach Adrian at adrian.cockcroft@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-03-1997/swol-03-perf.html
Last modified: