Increase system performance by maximizing your cache
You can't get the best results if you use the wrong cache. We explain how each works and when to do it
February 1997
|
|
Increase system performance by maximizing your cacheYou can't get the best results if you use the wrong cache. We explain how each works and when to do it |
February 1997 |
Accessing a file on disk or over a network is hundreds of times slower than reading a cached copy from memory. Many types of cache exist to speed up file accesses. Changing your workload to make it more "cache friendly" can result in very significant performance benefits. (3,100 words)
|
Mail this article to a friend |
Q:
I know that files are cached in memory and there is also a cache filesystem option. How can I tell if the caches are working well and how big they should be? Also, how can I tune applications together with the caches?
--Tasha in Cashmere (again)
A: Computer system hardware and software are built by using many types of cache. The system designers optimize these caches to work well with typical workload mixes and tune them using in-house and industry standard benchmarks. If you are writing an application or deciding how to deploy an existing suite of applications on a network of systems, you need to know what caches exist and how to work with them to get good performance.
Cache principles revisited
Here's a recap to the principles of caching we covered in last month's
article. Caches work on two basic principles that should be quite
familiar to you from everyday life experiences. The first is that if
you spend a long time getting something that you think you may
need again soon, you keep it nearby. The contents of your cache make
up your working set. The second principle is that when you get
something, you can save time by also getting the extra items you suspect you'll need in the near future.
The first principle is called "temporal locality" and involves reusing the same things over time. The second principle is called "spacial locality" and depends on the simultaneous use of things that are located near each other. Caches only work well if there is good locality in what you are doing. Some sequences of behavior work very efficiently with a cache, and others make little or no use of the cache. In some cases, cache-busting behavior can be fixed by changing the system to provide support for special operations. In most cases, avoiding cache-busting behavior in the workload's access pattern will lead to a dramatic improvement in performance.
A cache works well if there are a lot more reads than writes, and if the reads or writes of the same or nearby data occur close together in time. An efficient cache has a low reference rate (it doesn't make unnecessary lookups), a very short cache hit time, a high hit ratio, the minimum possible cache miss time, and an efficient way of handling writes and purges.
|
|
|
|
|
File access caching with local disks
We'll start by looking at the simplest configuration, the open,
fstat, read, write, and mmap operations on a
local disk with the default Unix File System (UFS).
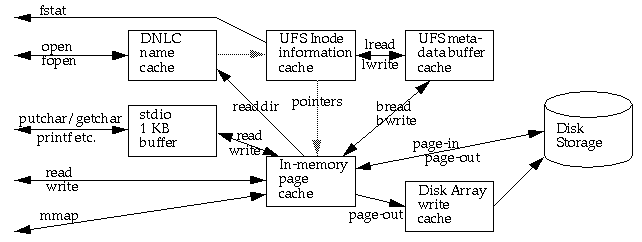
There are a lot of interrelated caches. They are system-wide caches shared by all users and all processes. The activity of one cache-busting process can mess up the caching of other well-behaved processes. Conversely, a group of cache-friendly processes working on similar data at similar times help each other by pre-filling the caches for each other. The diagram shows the main data flows and relationships.
If the name is in the cache, there is a fast hashed lookup; if it isn't, directories must be scanned. The UFS directory file structure is a sequence of variable-length entries requiring a linear search. Each DNLC entry is a fixed size, so there is only space for a pathname component of up to 30 characters. Longer ones are not cached. Many older systems, like SunOS 4, only cache up to 14 characters.
Directories that have thousands of entries can take a long time to search, so a good DNLC hit rate is important if files are being opened frequently and there are very large directories in use. In practice, file opening is not usually frequent enough for this to be a serious problem.
NFS clients hold a file handle that includes the inode number for
each open file, enabling each NFS operation to avoid the DNLC and go
directly to the inode. The maximum tested size of the DNLC is 34,906,
which corresponds to the maximum allowed maxusers setting of 2,048. The
biggest it will reach with no tuning is 17,498 on systems with more than
1 gigabyte of RAM. It defaults to (maxusers * 17) + 90, and maxusers is
set to just under the number of megabytes of RAM in the system, with a
default limit of 1,024. I find that people are overeager in tuning
ncsize; it really only needs to be increased manually on
small-memory (256 megabytes or less) NFS servers. Even then, any
performance increase is unlikely to be measurable.
The fstat call returns the inode information about a file,
including its size and datestamps, as well as the device and inode
numbers that uniquely identify the file. Every concurrently open file
corresponds to an active entry in the inode cache, so if a file is kept
open, its information is locked in the inode cache and is immediately
available.
A number (set by the tunable ufs_ninode) of inactive
inode entries are also kept. ufs_ninode is set using the
same calculation as ncsize above, but the total size of
the inode cache will be bigger, as ufs_ninode only limits
the inactive entries. It doesn't normally need tuning, but if the DNLC
is increased, make ncsize and ufs_ninode the
same.
Inactive files are files that were opened already and might be opened again. If the number of inactive entries grows too large, entries that have not been used recently are discarded. Stateless NFS clients do not keep the inode active, so the pool of inactive inodes caches the inode data for files that are opened by NFS clients. The inode cache entry also provides the location of every data block on disk and the location of every page of file data that is in memory.
If an inactive inode is discarded, all of its file data in memory are
also discarded, and the memory is freed for reuse. This is reported by
sar -g as %ufs_ipf, the percentage of inode
cache entries that had pages when they were freed (cached file data
discarded). My virtual_adrian.se rule warns if nonzero values are seen.
The inode cache hit rate is often 90 percent or more, meaning that
most files are accessed several times in a short period of time. If you
run a cache-busting command that looks at many files once only, like
find or ls -R, you will see a much lower DNLC
and inode cache hit rate. An inode cache hit is quick, as a hashed
lookup finds the entry efficiently. An inode cache miss varies, as the
inode may be found in the UFS metadata buffer cache, or a disk read may
be needed to get the right block of inodes into the UFS metadata buffer
cache.
This cache is often referred to as just "the buffer cache," but there has been so much confusion about its use that I like to be specific. Historically, Unix systems used a buffer cache to cache all disk data, assigning approximately 10 percent of total memory to this job. This changed around 1988, when SunOS 4.0 came out with a combined virtual memory and I/O setup. This setup was later included in System V Release 4, and variants of it are used in most recent Unix releases.
The buffer cache itself was left intact, but it was bypassed for all
data transfers, changing it from having a key role to being mostly
inconsequential. The sar -b command still reports on its
activity, but I can't remember the buffer cache itself being a
performance bottleneck in many years. As the title says, this cache
holds only UFS metadata. This includes disk blocks full of inodes (a
disk block is 8 kilobytes; an inode is about 300 bytes), indirect
blocks (used as inode extensions to keep track of large files), and
cylinder group information (which records the way the disk space is
divided up between inodes and data). The buffer cache sizes itself
dynamically, hits are quick, and misses involve a disk access.
All page-in and page-out operations occur between this cache and the
underlying filesystems on disk (or over NFS). Individual pages in the
cache might currently be unmapped (e.g. a data file), or can be mapped
into the address space of many processes (e.g. the pages that make up
the libc.so.1 shared library). Some pages do not
correspond to a named file (e.g. the stack space of a process); these
anonymous pages have swap space reserved for them so that they can be
written to disk if required. The vmstat and sar -pg
commands monitor the activity of this cache.
The cache is made up of 4-kilobyte or 8-kilobyte page frames. Each
page of data can be located on disk as a filesystem or swap space
datablock, or in memory in a page frame. Some page frames are ready for
reuse, or empty and are kept on the free list (reported as free by
vmstat).
A cache hit occurs when a needed page is already in memory. This can be recorded as an attach to an existing page or as a reclaim if the page was on the free list. A cache miss occurs when the page needs to be created from scratch (zero fill fault), duplicated (copy on write), or read in from disk (page in). Apart from the page in, these are all quite quick operations, and all misses take a page frame from the free list and overwrite it.
Consider a naive file reading benchmark that opens a small file, then reads it to "see how fast the disk goes." If the file was recently created, then all of the file may be in memory. Otherwise, the first read through will load it into memory. Subsequent runs may be fully cached with a 100 percent hit rate and no page ins from disk at all. The benchmark ends up measuring memory speed, not disk speed. The best way to make the benchmark measure disk speed is to invalidate the cache entries by unmounting and remounting the filesystem between each run of the test.
The complexities of the entire virtual memory system and paging algorithm are beyond the scope of this article. The key thing to understand is that data is only evicted from the cache if the free memory list gets too small. The data that is evicted is any page that has not been referenced recently -- where recently can mean a few seconds to a few minutes. Page-out operations occur whenever data is reclaimed for the free list due to a memory shortage. Page outs occur to all filesystems but are often concentrated on the swap space.
A common setup is to make reads bypass the disk array cache and to save all the space to speed up writes. If there is a lot of idle time and memory in the array, then the array controller might also look for sequential read patterns and prefetch some read data. In a busy array, however, this can get in the way. The OS does its own prefetching in any case.
There are three main situations that are helped by the write cache. When a lot of data is being written to a single file, it is often sent to the disk array in small blocks, perhaps 2 kilobytes to 8 kilobytes in size. The array can use its cache to coalesce adjacent blocks, which means that the disk gets fewer larger writes to handle. The reduction in the number of seeks greatly increases performance and cuts service times dramatically. This operation is only safe if the cache has battery backup for its cache (nonvolatile RAM), as the operating system assumes that when a write completes, the data is safely on the disk. As an example, 2-kilobyte raw writes during a database load can go two to three times faster.
The simple Unix write operation is buffered by the in-memory page
cache until the file is closed or data gets flushed out after 30
seconds. Some applications use synchronous writes to ensure that their
data is safely on disk. Directory changes are also made synchronously.
These synchronous writes are intercepted by the disk array write cache
and safely stored in nonvolatile RAM. Since the application is waiting
for the write to complete, this has a dramatic effect, often reducing
the wait from as much as 20 milliseconds to as little as 2
milliseconds. For the SPARCstorage Array, use the ssaadm
command to check that fast writes have been enabled on each controller,
and to see if they have been enabled for all writes or just synchronous
writes. It defaults to off, so if someone has forgotten to enable fast
writes you could get a good speedup! Use ssaadm to check
the SSA firmware revision and upgrade it first. There is a copy in
/usr/lib/firmware/ssa on Solaris 2.5.1.
The final use for a disk array write cache is to accelerate the RAID 5 write operations in hardware RAID systems. This does not apply to the SPARCstorage Array, which uses a slower, software-based RAID 5 calculation in the host system. RAID 5 combines disks using parity for protection, but during writes the calculation of parity means that all the blocks in a stripe are needed. With a 128-kilobyte interlace and a six-way RAID 5 subsystem, each full stripe cache entry would use 768 kilobytes. Each individual small write is then combined into the full stripe before the full stripe is written back later on.
This needs a much larger cache than performing RAID 5 calculations at the per-write level but is faster as the disks see fewer larger reads and writes. The SPARCstorage Array is very competitive for use in striped, mirrored, and read-mostly RAID 5 configurations, but its RAID 5 write performance is slow because each element of the RAID 5 data is read into main memory for the parity calculation and then written back. With only 4 megabytes or 16 megabytes of cache, the SPARCstorage Array doesn't have space to do hardware RAID 5, although this is plenty of cache for normal use. Hardware RAID 5 units have 64 megabytes or more -- sometimes much more.
putchar and getchar macros,
printf, and the related stdio.h routines. To
avoid a system call for every read or write of one character,
stdio uses a buffer to cache the data for each file. The
buffer size is 1 kilobyte, so for every 1024 calls of
getchar, a read system call of 1 kilobyte will occur; for
every eight system calls, a filesystem block will be paged in from
disk. If your application is reading and writing data in blocks of 1
kilobyte or more, there is no point using the stdio
library, you can save time by using the open/read/write
calls instead of fopen/fread/fwrite. Conversely, if you
are using open/read/write for a few bytes at a time you are generating
a lot of unnecessary system calls and stdio would be
faster.
mmap to map the page directly into
your address space. Data accesses then occur directly to the page in
the in-memory page cache, with no copying and no wasted space.
The drawback is that mmap changes the address space of
the process, which is a complex data structure. With a lot of files
using mmap, it gets even more complex. The
mmap call itself is more complex than a read or write, and
a complex address space also slows down the fork operation. My
recommendation is to use read and write for short-lived or small files.
Use mmap for random access to large long-lived files where
the avoidance of copying and reduction in read/write/lseek
system calls offsets the initial mmap overhead.
That's all for this month. I've gone on too long, and I've only
covered the basic operations involved in caching UFS to local disk.
I'll continue this topic next month and show how NFS and CacheFS fit
into the overall scheme of things from a caching point of view.
![]()
|
|
Resources
About the author
Adrian Cockcroft joined Sun in 1988, and currently works as a performance specialist for the Server Division of SMCC. He wrote Sun Performance and Tuning: SPARC and Solaris, published by SunSoft Press PTR Prentice Hall.
Reach Adrian at adrian.cockcroft@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-02-1997/swol-02-perf.html
Last modified: