How to program with threads
An introduction to multithreaded programming
February 1996
|
|
How to program with threadsAn introduction to multithreaded programming
|
February 1996 |
Need some clarification on multithreaded programming? This article defines threads -- what they are, why they are useful, and how they work -- and offers some pointers and examples for helping you along. (5,600 words)
|
Mail this article to a friend |
A thread is an abstract concept that comprises everything a computer does in executing a traditional program. It is the program state that gets scheduled on a CPU, it is the "thing" that does the work. If a process comprises data, code, kernel state, and a set of CPU registers, then a thread is embodied in the contents of those registers -- the program counter, the general registers, the stack pointer, etc., and the stack. A thread, viewed at an instant of time, is the state of the computation.
"Gee," you say, "That sounds like a process!" It should. They are conceptually related. But a process is a kernel-level entity and includes such things as a virtual memory map, file descriptors, user ID, etc., and each process has its own collection of these. The only way for your program to access data in the process structure, to query or change its state, is via a system call.
|
|
|
|
|
All parts of the process structure are in kernel space (Figure 1). A user program cannot touch any of that data directly. By contrast, all of the user code (functions, procedures, etc.) along with the data is in user space, and can be accessed directly.
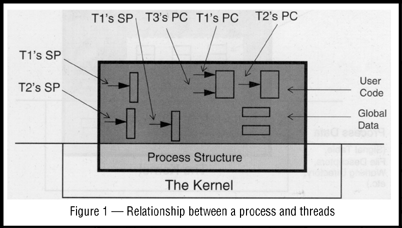
A thread is a user-level entity. The thread structure is in user space and can be accessed directly with the thread library calls, which are just normal user-level functions. Note that the registers (stack pointer, program counter, etc.) are all part of a thread, and each thread has its own stack, but the code it is executing is not part of the thread. The actual code (functions, routines, signal handlers, etc.) is global and can be executed on any thread. In Figure 1, we show three threads (T1, T2, T3), along with their stacks, stack pointers (SP), and programs counters (PC). T1 and T3 are executing the same function. This is a normal situation, just as two different people can read the same road sign at the same time.
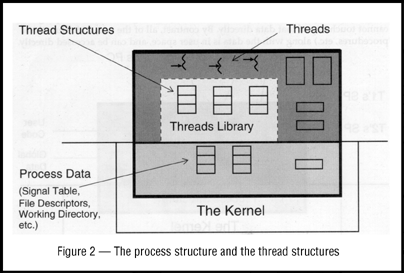
All threads in a process share the state of that process (see Figure 2). They reside in the exact same memory space, see the same functions, see the same data. When one thread alters a process variable (say, the working directory), all the others will see the change when they next access it. If one thread opens a file to read it, all the other threads can also read from it.
Let's consider a human analogy: a bank. A bank with one person working in it (traditional process) has lots of "bank stuff" such as desks and chairs, a vault, and teller stations (process tables and variables). There are lots of services that a bank provides: checking accounts, loans, savings accounts, etc. (the functions). With one person to do all the work, that person would have to know how to do everything, and could do so, but it might take a bit of extra time to switch among the various tasks. With two or more people (threads), they would share all the same "bank stuff," but they could specialize on their different functions. And if they all came in and worked on the same day, lots of customers could get serviced quickly.
To change the number of banks in town would be a big effort (creating new processes), but to hire one new employee (creating a new thread) would be very simple. Everything that happened inside the bank, including interactions among the employees there, would be fairly simple (user space operations among threads), whereas anything that involved the bank down the road would be much more involved (kernel space operations between processes).
When you write a multithreaded program, 99% of your programming is identical to what it was before -- you spend you efforts in getting the program to do its real work. The other 1% is spent in creating threads, arranging for different threads to coordinate their activities, dealing with thread-specific data, and signal masks. Perhaps 0.1% of your code consists of calls to thread functions.
So here's the essential point about threads: They are user-level entities. Virtually everything you do to a thread happens at user level with no system calls involved. Because no system calls are involved, it's fast. There are no kernel structures affected by the existence of threads in a program, so no kernel resources are consumed -- threads are cheap. The kernel doesn't even know that threads exist. (This is important. We're going to repeat it about ten times.)
The value of using threads
There is really only one reason for writing MT programs -- you get
better programs, more quickly. If you're an ISV, you sell more
software. If you're developing software for your own in-house use, you
simply have better programs to use. The reason that you can write
better programs is because MT gives your programs and your programmers
a number of significant advantages over nonthreaded programs and
programming paradigms.
A point to keep in mind here is that you are not replacing simple, nonthreaded programs with fancy, complex, threaded ones. You are using threads only when you need them to replace complex or slow nonthreaded programs. Threads are really just one more way you have to make your programming tasks easier.
The main benefits of writing multithreaded programs are:
The following sections elaborate further on these benefits.
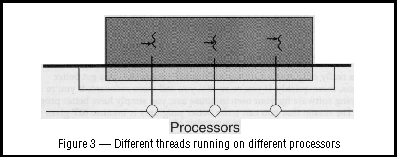
Parallelism
Computers with more than one processor provide multiple simultaneous
points of execution (Figure 3). Multiple threads are an efficient way
for application developers to exploit the parallelism of the hardware.
Different threads can run on different processors simultaneously with
no special input from the user and no effort on the part of the
programmer.
A good example of this is a process that does matrix multiplication. A thread can be created for each available processor, allowing the program to use the entire machine. The threads can then compute distinct elements of the result matrix by doing the appropriate vector multiplication.
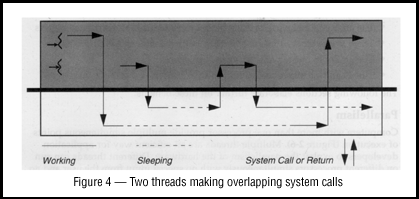
Throughput
When a traditional, single-threaded program requests a service from
the operating system, it must wait for that service to complete, often
leaving the CPU idle. Even on a uniprocessor, multithreading allows a
process to overlap computation with one or more blocking system calls
(Figure 4). Threads provide this overlap even though each request is
coded in the usual synchronous style. The thread making the request
must wait, but another thread in the process can continue. Thus, a
process can have numerous blocking requests outstanding, giving you
the beneficial effects of doing asynchronous I/O, while still writing
code in the simpler synchronous fashion.
Responsiveness
Blocking one part of a process need not block the whole process.
Single-threaded applications that do something lengthy when a button
is pressed typically display a "please wait" cursor and freeze while
the operation is in progress. If such applications were multithreaded,
long operations could be done by independent threads, allowing the
application to remain active and making the application more
responsive to the user.
Communications
An application that uses multiple processes to accomplish its tasks
can be replaced by an application that uses multiple threads to
accomplish those same tasks. Where the old program communicated among
its processes through traditional IPC (interprocess communications)
facilities (e.g., pipes or sockets), the threaded application can use
the inherently shared memory of the process. The threads in the MT
process can maintain separate IPC connections while sharing data in
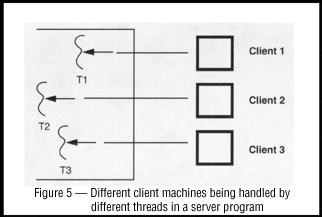
the same address space. A classic example is a server program, which
can maintain one thread for each client connection (Figure 5). This
provides excellent performance, simpler programming, and effortless
scalability.
System resources
Programs that use two or more processes to access common data through
shared memory are effectively applying more than one thread of
control. However, each such process must maintain a complete process
structure, including a full virtual memory space and kernel state. The
cost of creating and maintaining this large amount of state makes each
process much more expensive, in both time and space, than a thread. In
addition, the inherent separation between processes may require a
major effort by the programmer to communicate among the different
processes or to synchronize their actions. By using threads for this
communication instead of processes, the program will be easier to
debug and can run much faster.
An application can create hundreds or even thousands of threads, one for each synchronous task, with only minor impact on system resources. Threads use a fraction of the system resources used by processes.
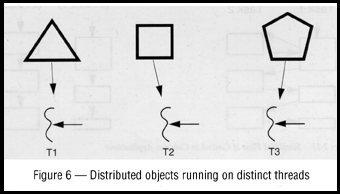
Distributed objects
With the first releases of standardized distributed objects and object
request brokers (coming in 1995), your ability to make use of these
will become increasingly important. Distributed objects are inherently
multithreaded. Each time you request an object to perform some action,
it executes that action in a separate thread (Figure 6). Object
servers are an absolutely fundamental element in distributed object
paradigm, and those servers (as discussed above) are inherently
multithreaded.
Although you can make a great deal of use of distributed objects without doing any MT programming, knowing what they are doing and being able to create objects that are threaded will increase the usefulness of the objects you do write.
Same binary for uniprocessors and multiprocessors
In most older parallel processing schemes, it was necessary to tailor
a program for the individual hardware configuration. With threads,
this customization isn't required because the MT paradigm works well
irrespective of the number of CPUs. A program can be compiled once,
and it will run acceptably on a uniprocessor, whereas on a
multiprocessor it will just run faster.
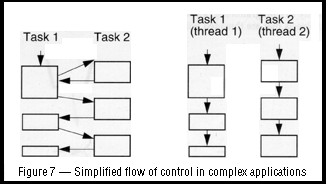
Program structure
Many programs are more efficiently structured with threads because
they are inherently concurrent. A traditional program that tries to do
many different tasks is crowded with lots of complicated code to
coordinate these tasks. A threaded program can do the same tasks with
much less, far simpler code. Multithreaded programs can be more
adaptive to variations in user demands than single- threaded programs
(see Figure 7).
Single source for multiple platforms
Many programs must run on numerous platforms. With the POSIX threads
standard, it will be possible to write a single source and recompile
it for the different platforms. Most of the Unix vendors have signed
up to do POSIX threads.
This is quite some set of claims, and a bit of healthy skepticism is called for when reading things like this. Sure, it sounds good when we say it, but what about when you try to use it? We cannot guarantee that you will experience the same wonderful results, but we can point out a number of cases where other folks have found MT programming to be of great advantage.
What about shared memory?
Right about now you may be asking yourself this question: "What can
threads do that can't be done by processes sharing memory?"
The first answer is "nothing." Anything that you can do with threads, you can also do with processes sharing memory. Indeed, a number of vendors implement a significant portion of their threads library in roughly this fashion. If you are thinking about using shared memory in this fashion, you should make sure you have (a) plenty of time to kill programming, (b) plenty more time to kill processing, and (c) lots of money to burn buying RAM.
You see: (a) Debugging cross-process programs is tough, and the tools that exist for this are not as good as those for MT. (b) Things take longer. In Solaris, creating a process is about 30 times slower than creating a thread, synchronization variables are about 10 times slower, and context switching about 5 times slower. (c) Processes eat up lots of kernel memory. Building a few thousand threads is no big deal. Building a few thousand processes is.
You can do everything with shared memory. It just won't be as easy nor run as fast.
Threads standards
As of the writing of this book (June, 1995), the POSIX committee on
multithreading standards 1003.1c (formerly 1003.4a) and the IEEE
standards board have just ratified the draft standard 10. There is now
an official POSIX threads standard.
This standard defines the API and behavior that all the pthreads libraries must meet. It is part of the extended portion of POSIX, so it is not a requirement for meeting XPG4, but all major Unix vendors have committed to meeting this standard. Presumably, a compliant library will be available from every vendor by the end of 1996, although individual plans and release dates may differ.
The futures for OS/2 threads and Windows NT threads are probably different. Both implementations contain some fairly radical departures from the POSIX standard -- to the degree that even porting from one or the other to POSIX will prove moderately challenging. Neither one plans to adopt the standard.
Follow some basic guidelines:
-D_REENTRANT when compiling or be sure that
_REENTRANT is defined before any header file is included.
Do not change global operations (or actions with global side effects) to behave in a threaded manner. For example, if file I/O is controlled at a global level, then threads in the process should not try to manipulate file I/O because the order of the file operations is not guaranteed.
For thread-specific behavior or thread-aware behavior, use thread
facilities. For example, when the termination of main()
should terminate only the thread that is exiting main(),
the end of main() should be:
thr_exit(); /*NOTREACHED*/
Creating threads
The Solaris threads package caches the threads data structure, stacks,
and LWPs so that the repetitive creation of unbound threads can be
inexpensive. Unbound thread creation is very inexpensive when compared
to process creation or even to bound thread creation. In fact, the
cost is similar to unbound thread synchronization when you include the
context switches to stop one thread and start another.
So, creating and destroying threads as they are required is usually better than attempting to manage a pool of threads that wait for independent work. A good example is an RPC server that creates a thread for each request and destroys it when the reply is delivered, instead of trying to maintain a pool of threads to service requests.
While thread creation is relatively inexpensive when compared to process creation, it is not inexpensive when compared to the cost of a few instructions. Create threads for processing that lasts long enough to minimize the overhead of the thread creation.
Thread concurrency
By default, Solaris threads attempts to adjust the system execution
resources (LWPs) used to run unbound threads to match the real number
of active threads. While the Solaris threads package cannot make
perfect decisions, it at least ensures that the process continues to
make progress.
When you have some idea of the number of unbound threads that
should be simultaneously active (executing code or system calls), tell
the library through thr_setconcurrency(3T).
For example:
Alternatively, the concurrency level can be incremented by 1
through the THR_NEW_LWP flag as each thread is created.
Include unbound threads blocked on interprocess
(USYNC_PROCESS) synchronization variables as active when
you compute thread concurrency. Exclude bound threads -- they do not
require concurrency support from Solaris threads because they are
equivalent to LWPs.
Bound threads
Bound threads are more expensive to create and schedule than unbound
threads. Because bound threads are attached to their own LWP, the
operating system provides a new LWP when a bound thread is created and
destroys it when the bound thread exits.
Use bound threads only when a thread needs resources that are available only through the underlying LWP, such as when the thread must be visible to the kernel to be scheduled with respect to all other active threads in the system, as in real-time scheduling.
Examples
This example will show how condition variables can be used to control
access of reads and writes to a buffer. This example can also be
thought as a producer/consumer problem, where the producer adds items
to the buffer and the consumer removes items from the buffer.
Two condition variables control access to the buffer. One condition
variable is used to tell if the buffer is full, and the other is used
to tell if the buffer is empty. When the producer wants to add an item
to the buffer, it checks to see if the buffer is full; if it is full,
then the producer blocks on the cond_wait() call, waiting
for an item to be removed from the buffer. When the consumer removes
an item from the buffer, the buffer is no longer full, so the producer
is awakened from the cond_wait() call. The producer is
then allowed to add another item to the buffer.
The consumer works, in many ways, the same as the producer. The
consumer uses the other condition variable to determine if the buffer
is empty. When the consumer wants to remove an item from the buffer,
it checks to see if it is empty. If the buffer is empty, the consumer
then blocks on the cond_wait() call, waiting for an item
to be added to the buffer. When the producer adds an item to the
buffer, the consumer's condition is satisfied, so it can then remove
an item from the buffer.
The example copies a file by reading data into a shared buffer (producer) and then writing data out to the new file (consumer). The Buf data structure is used to hold both the buffered data and the condition variables that control the flow of the data.
The main thread opens both files, initializes the Buf data
structure, creates the consumer thread, and then assumes the role of
the producer. The producer reads data from the input file, then places
the data into an open buffer position. If no buffer positions are
available, then the producer waits via the cond_wait()
call. After the producer has read all the data from the input file, it
closes the file and waits for (joins) the consumer thread.
The consumer thread reads from a shared buffer and then writes the data to the output file. If no buffers positions are available, then the consumer waits for the producer to fill a buffer position. After the consumer has read all the data, it closes the output file and exits.
If the input file and the output file were residing on different physical disks, then this example could execute the reads and writes in parallel. This parallelism would significantly increase the throughput of the example through the use of threads. (Source code is attached in the sidebar below.)
Socket server
The socket server example uses threads to implement a "standard"
socket port server. The example shows how easy it is to use
thr_create() calls in the place of fork()
calls in existing programs.
A standard socket server should listen on a socket port and, when a
message arrives, fork a process to service the request. Since a
fork() system call would be used in a nonthreaded
program, any communication between the parent and child would have to
be done through some sort of interprocess communication.
We can replace the
The server program first sets up all the needed socket information.
This is the basic setup for most socket servers. The server then
enters an endless loop, waiting to service a socket port. When a
message is sent to the socket port, the server wakes up and creates a
new thread to handle the request. Notice that the server creates the
new thread as a detached thread and also passes the socket descriptor
as an argument to the new thread.
The newly created thread can then read or write, in any fashion it
wants, to the socket descriptor that was passed to it. At this point,
the server could be creating a new thread or waiting for the next
message to arrive. The key is that the server thread does not care
what happens to the new thread after it creates it.
In our example, the created thread reads from the socket descriptor
and then increments a global variable. This global variable keeps
track of the number of requests that were made to the server. Notice
that a mutex lock is used to protect access to the shared global
variable. The lock is needed because many threads might try to
increment the same variable at the same time. The mutex lock provides
serial access to the shared variable. See how easy it is to share
information among the new threads! If each thread were a process, then
a significant effort would have to be made to share this information
among the processes.
The client piece of the example sends a given number of messages to
the server. This client code could also be run from different machines
by multiple users, thus increasing the need for concurrency in the
server process.
(Source code is attached in
the sidebar below.)
Using many threads
We have said before that anything you can do with threads, you can
do without them. This may be a case where it would be very hard to do
without threads. If you have some spare time (and lots of memory), try
implementing this program by using processes, instead of threads. If
you try this, you will see why threads can have an advantage over
processes.
This program takes as an argument the number of threads to create.
Notice that all the threads are created with a user-defined stack
size, which limits the amount of memory that the threads will need for
execution. The stack size for a given thread can be hard to calculate,
so some testing usually needs to be done to see if the chosen stack
size will work. You may want to change the stack size in this program
and see how much you can lower it before things stop working. The
Solaris threads library provides the
After each thread is created, it blocks, waiting on a mutex
variable. This mutex variable was locked before any of the threads
were created, which prevents the threads from proceeding in their
execution. When all of the threads have been created and the user
presses Return, the mutex variable is unlocked, allowing all the
threads to proceed.
After the main thread has created all the threads, it waits for
user input and then tries to join all the threads. Notice that the
This example is rather trivial and does not serve any real purpose
except to show that it is possible to create a lot of threads in one
process. However, there are situations when many threads are needed in
an application. An example might be a network port server, where a
thread is created each time an incoming or outgoing request is made.
(Source code is attached in
the sidebar below.)
About the author
If you have technical problems with this magazine, contact
webmaster@sunworld.com
URL: http://www.sunworld.com/swol-02-1996/swol-02-threads.html
About the authorfork() call with a
thr_create() call. Doing so offers a few advantages:
fork() could create a new process, and any communication
between the "server" and the new thread can be done with common
variables. This technique makes the implementation of the socket
server much easier to understand and should also make it respond much
faster to incoming requests.
Here is an example that shows how easy it is to create many threads of
execution in Solaris. Because of the lightweight nature of threads, it
is possible to create literally thousands of threads. Most
applications may not need a very large number of threads, but this
example shows just how lightweight the threads can be.
thr_min_stack()
call, which returns the minimum allowed stack size. Take care when
adjusting the size of a threads stack -- a stack overflow can happen
quite easily to a thread with a small stack.
thr_join() call does not care what thread it joins; it is
just counting the number of joins it makes.
Bil Lewis is an engineer in SunSoft's Evangelism group, focusing on
multithreading and other technologies.
Daniel J. Berg is a Systems Engineer for Sun Microsystems, Inc. where
his work has focused on the Unix system.
Check out the Web site for
Threads Primer: A Guide to Multithreaded Programming.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Last modified:
![]()
![]()
Producer/Consumer Example
#define _REEENTRANT
#include <stdio.h>
#include <thread.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/uio.h>
#define BUFSIZE 512
#define BUFCNT 4
/* this is the data structure that is used between the producer
and consumer threads */
struct {
char buffer[BUFCNT][BUFSIZE];
int byteinbuf[BUFCNT];
mutex_t buflock;
mutex_t donelock;
cond_t adddata;
cond_t remdata;
int nextadd, nextrem, occ, done;
} Buf;
/* function prototype */
void *consumer(void *);
main(int argc, char **argv)
{
int ifd, ofd;
thread_t cons_thr;
/* check the command line arguments */
if (argc != 3)
printf("Usage: %s <infile> <outfile>\n", argv[0]), exit(0);
/* open the input file for the producer to use */
if ((ifd = open(argv[1], O_RDONLY)) == -1)
{
fprintf(stderr, "Can't open file %s\n", argv[1]);
exit(1);
}
/* open the output file for the consumer to use */
if ((ofd = open(argv[2], O_WRONLY|O_CREAT, 0666)) == -1)
{
fprintf(stderr, "Can't open file %s\n", argv[2]);
exit(1);
}
/* zero the counters */
Buf.nextadd = Buf.nextrem = Buf.occ = Buf.done = 0;
/* set the thread concurrency to 2 so the producer and consumer can
run concurrently */
thr_setconcurrency(2);
/* create the consumer thread */
thr_create(NULL, 0, consumer, (void *)ofd, NULL, &cons_thr);
/* the producer ! */
while (1) {
/* lock the mutex */
mutex_lock(&Buf.buflock);
/* check to see if any buffers are empty */
/* If not then wait for that condition to become true */
while (Buf.occ == BUFCNT)
cond_wait(&Buf.remdata, &Buf.buflock);
/* read from the file and put data into a buffer */
Buf.byteinbuf[Buf.nextadd] = read(ifd,Buf.buffer[Buf.nextadd],BUFSIZE);
/* check to see if done reading */
if (Buf.byteinbuf[Buf.nextadd] == 0) {
/* lock the done lock */
mutex_lock(&Buf.donelock);
/* set the done flag and release the mutex lock */
Buf.done = 1;
mutex_unlock(&Buf.donelock);
/* signal the consumer to start consuming */
cond_signal(&Buf.adddata);
/* release the buffer mutex */
mutex_unlock(&Buf.buflock);
/* leave the while loop */
break;
}
/* set the next buffer to fill */
Buf.nextadd = ++Buf.nextadd % BUFCNT;
/* increment the number of buffers that are filled */
Buf.occ++;
/* signal the consumer to start consuming */
cond_signal(&Buf.adddata);
/* release the mutex */
mutex_unlock(&Buf.buflock);
}
close(ifd);
/* wait for the consumer to finish */
thr_join(cons_thr, 0, NULL);
/* exit the program */
return(0);
}
/* The consumer thread */
void *consumer(void *arg)
{
int fd = (int) arg;
/* check to see if any buffers are filled or if the done flag is set */
while (1) {
/* lock the mutex */
mutex_lock(&Buf.buflock);
if (!Buf.occ && Buf.done) {
mutex_unlock(&Buf.buflock);
break;
}
/* check to see if any buffers are filled */
/* if not then wait for the condition to become true */
while (Buf.occ == 0 && !Buf.done)
cond_wait(&Buf.adddata, &Buf.buflock);
/* write the data from the buffer to the file */
write(fd, Buf.buffer[Buf.nextrem], Buf.byteinbuf[Buf.nextrem]);
/* set the next buffer to write from */
Buf.nextrem = ++Buf.nextrem % BUFCNT;
/* decrement the number of buffers that are full */
Buf.occ--;
/* signal the producer that a buffer is empty */
cond_signal(&Buf.remdata);
/* release the mutex */
mutex_unlock(&Buf.buflock);
}
/* exit the thread */
thr_exit((void *)0);
}
![]()
![]()
![]()
![]()
Threaded Socket Example
#define _REENTRANT
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <string.h>
#include <sys/uio.h>
#include <unistd.h>
#include <thread.h>
/* the TCP port that is used for this example */
#define TCP_PORT 6500
/* function prototypes and global variables */
void *do_chld(void *);
mutex_t lock;
int service_count;
main()
{
int sockfd, newsockfd, clilen;
struct sockaddr_in cli_addr, serv_addr;
thread_t chld_thr;
if((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0)
fprintf(stderr,"server: can't open stream socket\n"),
exit(0);
memset((char *) &serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(TCP_PORT);
if(bind(sockfd, (struct sockaddr *) &serv_addr,
sizeof(serv_addr)) < 0)
fprintf(stderr,"server: can't bind local address\n"),
exit(0);
/* set the level of thread concurrency we desire */
thr_setconcurrency(5);
listen(sockfd, 5);
for(;;){
clilen = sizeof(cli_addr);
newsockfd = accept(sockfd, (struct sockaddr *) &cli_addr,
&clilen);
if(newsockfd < 0)
fprintf(stderr,"server: accept error\n"), exit(0);
/* create a new thread to process the incoming request */
thr_create(NULL, 0, do_chld, (void *) newsockfd,
THR_DETACHED, &chld_thr);
/* the server is now free to accept another socket request */
}
return(0);
}
/* This is the routine that is executed from a new thread */
void *do_chld(void *arg)
{
int mysocfd = (int) arg;
char data[100];
int i;
printf("Child thread [%d]: Socket number = %d\n", thr_self(), mysocfd);
/* read from the given socket */
read(mysocfd, data, 40);
printf("Child thread [%d]: My data = %s\n", thr_self(), data);
/* simulate some processing */
for (i=0;i<1000000*thr_self();i++);
printf("Child [%d]: Done Processing...\n", thr_self());
/* use a mutex to update the global service counter */
mutex_lock(&lock);
service_count++;
mutex_unlock(&lock);
printf("Child thread [%d]: The total sockets served = %d\n", thr_self(), service_count);
/* close the socket and exit this thread */
close(mysocfd);
thr_exit((void *)0);
}
Socket Client Example
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
/* you many want to change the following information for your network */
#define TCP_PORT 6500
#define SERV_HOST_ADDR "11.22.33.44"
main(int argc, char **argv)
{
int i, sockfd, ntimes = 1;
struct sockaddr_in serv_addr;
char buf[40];
memset((char *) &serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr(SERV_HOST_ADDR);
serv_addr.sin_port = htons(TCP_PORT);
if (argc == 2) ntimes = atoi(argv[2]);
for (i=0; i < ntimes; i++) {
if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0)
perror("clientsoc: can't open stream socket"), exit(0);
if (connect(sockfd, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) < 0)
perror("clientsoc: can't connect to server"), exit(0);
printf("sending segment %d\n", i);
sprintf(buf, "DATA SEGMENT %d", i);
write(sockfd, buf, strlen(buf));
close(sockfd);
}
return(0);
}
![]()
![]()
![]()
![]()
Using Many Threads Example
#define _REENTRANT
#include <stdio.h>
#include <stdlib.h>
#include <thread.h>
/* function prototypes and global variables */
void *thr_sub(void *);
mutex_t lock;
main(int argc, char **argv)
{
int i, thr_count = 100;
char buf;
/* check to see if user passed an argument
-- if so, set the number of threads to the value
passed to the program */
if (argc == 2) thr_count = atoi(argv[1]);
printf("Creating %d threads...\n", thr_count);
/* lock the mutex variable -- this mutex is being used to
keep all the other threads created from proceeding */
mutex_lock(&lock);
/* create all the threads -- Note that a specific stack size is
given. Since the created threads will not use all of the
default stack size, we can save memory by reducing the threads'
stack size */
for (i=0;i<thr_count;i++) {
thr_create(NULL,2048,thr_sub,0,0,NULL);
}
printf("%d threads have been created and are running!\n", i);
printf("Press <return> to join all the threads...\n", i);
/* wait till user presses return, then join all the threads */
gets(&buf);
printf("Joining %d threads...\n", thr_count);
/* now unlock the mutex variable, to let all the threads proceed */
mutex_unlock(&lock);
/* join the threads */
for (i=0;i<thr_count;i++)
thr_join(0,0,0);
printf("All %d threads have been joined, exiting...\n", thr_count);
return(0);
}
/* The routine that is executed by the created threads */
void *thr_sub(void *arg)
{
/* try to lock the mutex variable -- since the main thread has
locked the mutex before the threads were created, this thread
will block until the main thread unlock the mutex */
mutex_lock(&lock);
printf("Thread %d is exiting...\n", thr_self());
/* unlock the mutex to allow another thread to proceed */
mutex_unlock(&lock);
/* exit the thread */
return((void *)0);
}
![]()
![]()
Bil Lewis is an engineer in SunSoft's Evangelism group, focusing on multithreading and other technologies. Daniel J. Berg is a Systems Engineer for Sun Microsystems, Inc. where his work has focused on the Unix system. Check out the Web site for Threads Primer: A Guide to Multithreaded Programming. ![]()