Swap space implementation, part twoLast month we set the stage with some background information. This month, we'll complete our coverage with a detailed look at the implementation of swap in Solaris |
January 1998 |
Limitations in the prior implementation of swap in SunOS lead to the development of swapfs (swap file system), a pseudo file system first introduced in Solaris 2.X (SunOS 5.X). Swapfs is at the heart of kernel implementation of swap space. We began with an introduction last month and will conclude our discussion of it this month. (2,900 words)
|
Mail this article to a friend |
The second issue with the old implementation of swap was a simple allocation algorithm for allocating disk blocks to store the memory page. It was generally considered that a smarter interface could make more intelligent decisions on disk block allocation, providing much more efficient I/O to swap disks. I'll note here that while fast and efficient I/O to the swap disks is a good thing, we should be careful about spending too much time tweaking swap disks for I/O speed. If systems performance is such that the speed of doing I/O to swap devices can contribute or detract from overall application performance, then the real problem should be addressed -- such a system needs more RAM, or the application should be tuned to reduce memory requirements (e.g., smaller memory allocation to database-shared memory segments).
|
|
|
|
|
Memory pages and backing store
The linkage between a memory page mapped to a process's address
space and the corresponding kernel support structures required to
manage the backing store for the page is a kernel segment
driver. Every process has an address space, described by an
address space structure linked to the process's process table entry
(proc structure). The address space is comprised of some number of
memory segments, which are simply some number of mapped
virtual pages; a memory segment being a subset of the total address
space. The management of the address space is handled by segment
drivers, which handle the mapping of a particular segment of the
address space. It is the segment driver that interfaces to the
low-level hardware address translation (HAT) layer, which has the
system-specific memory management code. There are several types of
segment drivers for Solaris systems; some are optimized to
support mappings for specific hardware device types (e.g., frame
buffers). The most commonly used segment driver, and the one that
applies to this month's discussion, is the vnode segment
driver, called seg_vn. The seg_vn driver
manages process memory segment mappings for mapped files (e.g.,
executables and shared libraries) as well as heap space (anonymous
pages and stack space). Figure 1 illustrates the address space,
segment, and device backing store relationships.
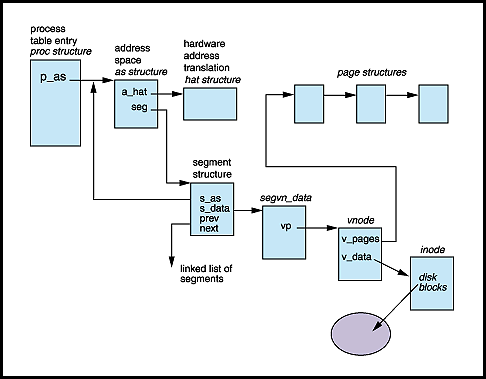
Process address space data structures, linkage for file system based mapped files (e.g. executables) |
As indicated in Figure 1, a segvn_data data structure
exists for the mapping, which links into a corresponding vnode (the
virtual file system abstraction -- a structure used to name objects
in a file system). Because every file in the file system has an
inode (an on-disk structure that describes a file), mappings through
the segment driver will ultimately link to the file's inode.
Obviously, a single file mapped into an address space may be
comprised of several memory pages. The linkage through the
segvn_data data structure will link those pages
together, and the page structure (one for every page) maintains
linkage back to the vnode.
Getting back to memory pages for a moment, the kernel names every
mapped page in RAM by its vnode and byte offset, represented as
<vnode, offset>, and it's stored in the page's page
structure. We already discussed vnode; the offset is
the byte offset into the file (number of bytes from the beginning of
the file).
Because anonymous memory pages have no home in the file system,
there is no corresponding inode structure to link back to. This is
where the anonymous memory support layers and swapfs enter the
picture. For anonymous memory pages, the segvn_data
data structure links to other kernel structures that make up the
anon layer, which sits between the mapping (segment) and swapfs.
Figure 2 provides the big picture.
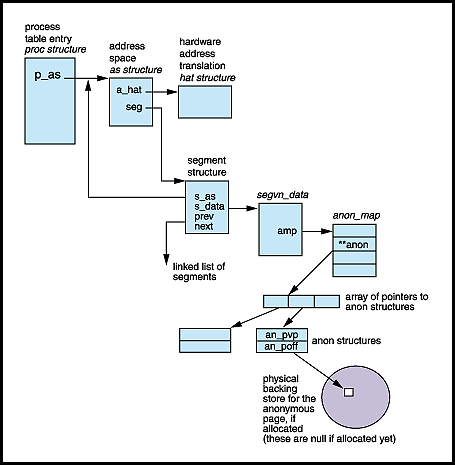
Process address space structure and linkage for anonymous memory pages |
Anonymous pages in memory are managed by the kernel anon layer, which calls upon routines in the swapfs code to manage the allocation of backing store and actual swapping in and out of anonymous pages from the swap device. This is all done through the allocation and maintenance of the data structures shown in Figure 2.
Every anonymous page, whether resident in physical memory or on backing store, has an anon structure associated with it. It is through the anon structure that we provide the linkage for the backing store for the page by maintaining a vnode pointer in the structure that links to the swapfs vnode. This is where the anon layer meets swapfs. By linking to the swapfs vnode, the system gives control of the page's backing store allocation to swapfs.
Swapfs provides the system with a virtual swap space, which is
comprised of some amount of available physical memory, plus the
configured disk swap devices and swapfiles. When the anon layer
makes a request to swapfs to provide a name for backing store for a
page, the swapfs layer grabs a resource from the virtual swap pool
and returns a name for the page using the swapfs vnode and offset
into the virtual swap file. This is the <vnode, offset>
name returned to the requesting anon layer. It does
not, as yet, correspond to any physical backing store, and it may
never actually require a backing store allocation if the page never
needs to be paged out. Thus, swapfs satisfies the requirement that
anon pages get named with "backing store" prior to use, which was a
requirement in the prior design and is still enforced in the new
swapfs-based system.
Imposing such a requirement provides a cleaner means of controlling
where things may fail as a result of not having enough system
resources. A simple example is a program called
malloc(3C) that is used to get some working memory.
Without enforcing that a name be provided before the
allocation can continue, it's possible for the
malloc(3C) to succeed, only to have the program fail in
some unpredictable way when one of the malloc'd pages needs to be
paged out, and there's no place for the kernel to put it! The
policy we use insures that if there is insufficient swap space, the
malloc(3C) will fail. This is easier for programmers to
handle. (All programs running on Solaris are written such that the
return value of every system call and library routine is checked for
success or failure before the code proceeds.)
Should it become necessary for swapfs to allocated actual physical
backing store for a page, (e.g., if the pageout daemon needs to push
the page out of RAM to create memory space), swapfs can dynamically
change the name of the page (the <vnode, offset>) such
that it reflects the actual backing store assigned to the page.
Swapfs will allocate against physical disk-backed swap first. It will only allocate from memory if there is no available swap disk. Allocations against memory cause swapfs to lock down the memory pages such that they will never be paged out.
Figure 3 illustrates anonymous memory pages in various states -- with and without backing store allocated.
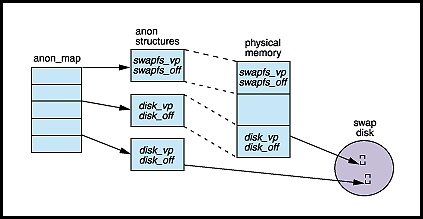
The top anon structure references a page that has been allocated and named by swapfs. It has no backing store. The second page has been renamed by swapfs to reflect physical backing store. The third page has also been renamed to reflect physical backing store, and the memory page itself has been freed. |
Running with swap
If we examine a Solaris system that has not had any swap disk configured,
using the swap(1M) command, you'll see something like this:
allaire> swap -l No swap devices configured allaire> swap -s total: 44664k bytes allocated + 31336k reserved = 76000k used, 784136k available
Our example system, allaire, is a four-processor E3000 with one
gigabyte of RAM. As you can see, we have not configured any swap
disk -- either with an entry in the /etc/vfstab file,
or by using swap(1M) with the "-a" flag, which allows
an administrator to add swap by specifying a raw disk partition
(e.g., /dev/rdsk/c0t0d0s1) or a swapfile created with the
mkfile(1M) command.
The swap -s command is used to summarize the current
state of swap space on your system, based on virtual swap (the sum
of available memory and physical swap devices). Our example shows
that we have a total of 860 megabytes of swap (I'm rounding the
numbers up for simplicity). The 860 megabytes is derived from 784 megabytes
available and 76 megabytes used. What this illustrates is that Solaris has
swap space available for anonymous page usage without any actual
swap disk configured. The space is, of course, physical memory, and as
physical memory gets utilized, the available amount of swap will go
down.
To illustrate the usefulness of this, I'll run a small test
program. When started, the program does nothing. When it receives a
USR1 signal, it will malloc 200 megabytes of
memory. When it receives a USR2 signal, it will touch
all the pages in the malloc'd 200 megabytes space.
Let's take a look at the current state of swap, since I just rebooted the system:
allaire> swap -s total: 27696k bytes allocated + 22872k reserved = 50568k used, 816000k available allaire> swap -l No swap devices configured
OK, we have 816 megabytes of swap available and no physical swap devices. Now, I'll run a sequence of commands. The left hand column consists of line numbers I use for the description below:
1 allaire> mal & 2 [1] 508 3 allaire> /usr/proc/bin/pmap 508 4 508: mal 5 00010000 8K read/exec dev:178,1 ino:1268004 6 00020000 8K read/write/exec dev:178,1 ino:1268004 7 EF6E0000 16K read/exec /usr/platform/sun4u/lib/libc_psr.so.1 8 EF700000 592K read/exec /usr/lib/libc.so.1 9 EF7A2000 24K read/write/exec /usr/lib/libc.so.1 10 EF7A8000 8K read/write/exec [ anon ] 11 EF7B0000 8K read/exec/shared /usr/lib/libdl.so.1 12 EF7C0000 112K read/exec /usr/lib/ld.so.1 13 EF7EA000 16K read/write/exec /usr/lib/ld.so.1 14 EFFFC000 16K read/write/exec [ stack ] 15 total 808K 16 allaire> swap -s 17 total: 28016k bytes allocated + 23008k reserved = 51024k used, 814552k available 18 allaire> kill -USR1 508 19 allaire> malloc'd 209715200 20 allaire> /usr/proc/bin/pmap 508 21 508: mal 22 00010000 8K read/exec dev:178,1 ino:1268004 23 00020000 8K read/write/exec dev:178,1 ino:1268004 24 00022000 204808K read/write/exec [ heap ] 25 EF6E0000 16K read/exec /usr/platform/sun4u/lib/libc_psr.so.1 26 EF700000 592K read/exec /usr/lib/libc.so.1 27 EF7A2000 24K read/write/exec /usr/lib/libc.so.1 28 EF7A8000 8K read/write/exec [ anon ] 29 EF7B0000 8K read/exec/shared /usr/lib/libdl.so.1 30 EF7C0000 112K read/exec /usr/lib/ld.so.1 31 EF7EA000 16K read/write/exec /usr/lib/ld.so.1 32 EFFFC000 16K read/write/exec [ stack ] 33 total 205616K 34 allaire> swap -s 35 total: 28240k bytes allocated + 227664k reserved = 255904k used, 609560k available 36 allaire> 37 allaire> kill -USR2 508 38 allaire> touched 209715200 39 allaire> swap -s 40 total: 232944k bytes allocated + 22960k reserved = 255904k used, 609544k available 41 allaire>
This shows that I started the program (called mal, line 1) and
dumped the address space map of the program (pmap command, line 3).
The output of pmap(1) is shown in lines 4 to 15. As
you can see, there is no large anonymous memory segment in the
address space, and the output of swap -s (line 17)
shows things didn't change much. There's less total memory available
because we started a new program that has a 808-kilobyte total
address space size. A few bytes where allocated for the process anon
and stack (lines 10 and 14).
I send the USR1 signal, and the program reports it
malloc'd 200 megabytes (lines 18 and 19). Dumping the address space again,
we now see a very large "heap" segment (line 24). The output of
swap -s (line 35) shows that the system reserved 200 megabytes
of swap (reserved went from 23008 k to 227664 k). 200 megabytes less is
available, and allocated swap didn't really change (remember we
haven't actually touched the memory yet). Finally, the
USR2 signal is sent (line 37); the program reports
touched all 200 megabytes (line 38); and, we dump the output of swap
-s on line 39. This time, we see allocated space grow by 200
megabytes (from 28240 k to 232944 k) and reserved drop by 200 megabytes (from
227664 k to 22960 k).
This serves to illustrate a couple of points quite well. First, we see
that we can have programs running using anonymous memory without any
physical swap space configured. Second, we see the difference
between reserved space and allocated space. When a program makes an
anonymous memory request, swapfs will reserve the space required,
but not actually allocate it. At this point, the anon
structures for those pages will contain the swapfs vnode in the page
<vnode, offset> names. Once we actually touched the
memory pages, swapfs needed to allocate space. Because there was no
physical disk space available, swapfs allocated the memory as swap
memory, which has the net effect of locking the pages down in
memory, such that they can not be paged out.
There are two variables initialized by the swapfs code at system
startup that help with the management of swap usage and memory. They
are swapfs_minfree and swapfs_desfree.
Swapfs_minfree gets set to either two megabytes, or
1/8th total physical memory, whichever value is larger. Our example
system, allaire, which has one gigabyte of RAM, has
swapfs_minfree equal to 125 megabytes (these are round
numbers, not precise). Swapfs_minfree is how much
memory we want to keep available for the rest of the system --
basically a buffer zone to keep some amount of memory available for, in
example, kernel growth. Swapfs will never get larger than
available real memory minus swapfs_minfree.
Swapfs_desfree gets set to 3 1/2 megabytes, and provides a
method that Solaris users can implement if they wish to decrease the
amount of memory that can be made available to swapfs. The default
value of 3 1/2 megabytes is used in one area of the system to bring up the
value of swap_minfree in situations where the system
has a relatively small amount of physical memory, resulting in
swapfs_minfree being set to two megabytes. This is
not considered a comfortably sized buffer zone, so when the
swapadd() kernel routine is called to add additional
swap space, the system will set swapfs_minfree to a
higher value to increase the size of the safety zone. This is
actually a holdover from the days when 16-megabyte or 24-megabyte systems were
fairly common. For a system with more than 28 megabytes of RAM,
swapfs_minfree will always be larger than 3 1/2 megabytes, so
the code that resets it will never execute.
So, how much swap should be configured? Well, the basic requirement
for swap is driven directly by the amount of anonymous memory the
system needs to run the application. As we said earlier, if there is
enough physical RAM to hold all the required process pages, then the
system can run literally with no physical swap configured.
How much anonymous memory a system needs is not an easy thing to
determine with currently available tools. Your best bet is to use the
pmap command to examine process address space maps and
measure the heap and anon sizes. This is time consuming, but
reasonably accurate.
As an additional data point, experience has shown that large applications (e.g., SAP/R3, BAAN, Oracle) tend to have processes with large virtual address spaces. This is typically the result of attaching to large shared memory segments used by relational databases and large copy-on-write (COW) segments that get mapped but sometimes never actually get touched. The net effect of this is that on large systems supporting these commercial applications, the virtual address space requirements grow to be quite large, typically exceeding the physical memory size. Consequently, such systems often require a fair amount of swap disk configured to support many processes with large VA space running concurrently. You need to configure 1 to 1.5 times the amount of RAM you have for swap so the systems can fully utilize all of the physical memory without running out of virtual swap space.
An alternative approach to measuring system memory utilization and
anonymous memory requirements is an unbundled tool that provides a
detailed breakdown of memory usage on a Solaris system. It's called
memtool, and was developed by a Sun engineer. It is
available with an accompanying paper called "The Solaris Memory
System, Sizing, Tools and Architecture." Internal Sun folks can access
the paper at http://www.corp/essg/ee/ (under "what's hot"), as
well as the tool. Otherwise, please contact your local Sun SE and
ask for a copy of memtool and the paper.
Finally, don't forget that the system needs a physical swap partition in order to create a dump file in the event of a system crash. This is critically important for any production system so the proper troubleshooting steps can be taken if things start going wrong.
Summary
Hopefully, you now have a good idea of what swapfs is all about and
how Solaris implements swap space. Unfortunately, there is no easy
way to determine the anonymous memory requirements of applications.
The evolution of tools like memtool, however, make the job
easier.
Next month, we're going to talk about open files in Solaris.
Until then, happy new year everyone!
![]()
Resources
About the author
Jim Mauro is currently an Area Technology Manager for Sun
Microsystems in the Northeast area, focusing on server systems,
clusters, and high availability. He has a total of 18 years industry
experience, working in service, educational services (he developed
and delivered courses on Unix internals and administration), and
software consulting.
Reach Jim at jim.mauro@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-01-1998/swol-01-insidesolaris.html
Last modified: