Tips for TCP/IP monitoring and tuning to make your network sing
How to increase performance by tuning your connections, data transfers and flow control -- plus download a new SE Toolkit not available in Sun's latest software release
December 1996
|
|
Tips for TCP/IP monitoring and tuning to make your network singHow to increase performance by tuning your connections, data transfers and flow control -- plus download a new SE Toolkit not available in Sun's latest software release |
December 1996 |
The TCP/IP protocol is complex and there are a large number of protocol counters available. This month we take a look at the interesting metrics and figure out which values to tune. A new SE script provides a GUI to make it easy. (3,000 words)
|
Mail this article to a friend |
Q:
Which of the TCP protocol counters are worth watching? How can I
tell if there is a problem, and what should I tune?
--Fin_wait Freda
A:
TCP/IP is simple in concept, but the reality of making it work reliably
in a wide range of conditions adds a lot more complexity. There are a
large number of protocol counters that can be viewed with netstat
-s, but only a small number of them are of general interest.
There is another set of values that can be obtained and set using the
ndd command.
The netstat -s command lists several protocols, but I just
show the TCP data that is reported by Solaris 2.5.1.
TCP tcpRtoAlgorithm = 4 tcpRtoMin = 200
tcpRtoMax = 60000 tcpMaxConn = -1
tcpActiveOpens = 3283 tcpPassiveOpens = 234
tcpAttemptFails = 0 tcpEstabResets = 100
tcpCurrEstab = 6 tcpOutSegs = 80370
tcpOutDataSegs = 57395 tcpOutDataBytes =9854298
tcpRetransSegs = 4826 tcpRetransBytes =644526
tcpOutAck = 23486 tcpOutAckDelayed = 5081
tcpOutUrg = 34 tcpOutWinUpdate = 3
tcpOutWinProbe = 5 tcpOutControl = 7066
tcpOutRsts = 132 tcpOutFastRetrans = 196
tcpInSegs = 96006
tcpInAckSegs = 52302 tcpInAckBytes =9856462
tcpInDupAck = 9887 tcpInAckUnsent = 0
tcpInInorderSegs = 63348 tcpInInorderBytes =20318851
tcpInUnorderSegs = 0 tcpInUnorderBytes = 0
tcpInDupSegs = 0 tcpInDupBytes = 0
tcpInPartDupSegs = 0 tcpInPartDupBytes = 0
tcpInPastWinSegs = 0 tcpInPastWinBytes = 0
tcpInWinProbe = 6 tcpInWinUpdate = 4
tcpInClosed = 15 tcpRttNoUpdate = 1286
tcpRttUpdate = 20744 tcpTimRetrans = 1514
tcpTimRetransDrop = 0 tcpTimKeepalive = 168
tcpTimKeepaliveProbe= 0 tcpTimKeepaliveDrop = 0
tcpListenDrop = 0
To make sense of this, and to pick out the data of interest, I'll
start with a simplified description of TCP, and relate this to the data
reported by netstat -s.
TCP is a reliable, connection-oriented protocol. You have to establish a connection between two machines, send data, make sure it gets there safely, then shut down the connection. At any point in time there will be some number of connections in each of these states. It's rather like making a telephone call -- dialing, talking, then hanging up. (The common alternative to TCP is UDP, which is much more like the postal service; you send a packet and hope that it gets there.)
|
|
|
|
|
Connections
Some connections are opened by your system as it calls out to another
machine. Conversely other connections are opened as a result of another
machine calling in. Again this is just like a phone call, where you
could be making the call or receiving the call. Once the call is
established it is symmetric; both sides can send and receive data as
they wish, and either side can terminate the connection.
The outgoing calls you make are called "Active Opens." You decide
who to call and why. An outgoing rlogin, or Web browser
request causes an active open. The incoming calls are called "Passive
Opens" as they occur without any activity on your part. You just have
to have a program running that is waiting to "pick up the phone." For
example a Web server listens on port 80 for any incoming requests.
There are two counters that keep track of how many of each type have
occurred.
tcpActiveOpens = 3283 tcpPassiveOpens = 234
You should keep track of the rate at which opens occur. The fundamental performance limit of most Web servers is the rate at which they can perform the passive open. Most systems can run at several hundred connections per second. If you need more, you must split the load over multiple systems. Over the next year OS tuning and faster CPUs should push this rate into the thousands of connections per second per system range.
Each connection can last a few milliseconds (for a Web server on a
local LAN running a benchmark) or many seconds or minutes (for a large
transfer on a slow Internet connection). Each established connection
will use up a process or a thread in your system. The number is
reported by netstat as:
tcpCurrEstab = 6
During connection setup there is a handshake sequence. This can take
a while as several round-trip delays between the two systems are
needed. There is a limit on the number of connections in this state
(known as the listen queue), and for connection intensive workloads on
high latency networks (you guessed it -- Internet Web servers) the limit
may be too low. The default before Solaris 2.5 was five, and the maximum
was 32. Since Solaris 2.5 the default is 32 and the maximum is 1024. In
Solaris 2.5.1 an extra counter was added to the netstat -s
TCP output called tcpListenDrop. It counts the number of
times that a connection was dropped due to a full listen queue. If you
ever see non-zero values of tcpListenDrop, you should
increase the size of the queue. Tuning is discussed later on in this
article.
Data transfer
For many systems, the first performance bottleneck is the amount of
network bandwidth available. With up to date software, almost any
system can saturate a 10-megabit Ethernet, even with Web traffic. We
can look at the access logs to see how much data is being sent, but
that does not include the protocol overhead or the incoming requests.
We can get a better idea of the traffic levels by looking at the TCP
throughput counters. The outgoing data is divided into segments, where
each segment corresponds to an Ethernet packet. Delivery of a segment
is acknowledged by the other end. If no acknowledgment is received the
segment is retransmitted. To decide whether the segment has been lost,
or is just taking a long time, a complex adaptive time-out scheme is
used. Both ends are working the same way, so they send data segments as
well as acknowledgment segments for the data they receive. Here are the
output counters reported by netstat.
tcpOutSegs = 80370
tcpOutDataSegs = 57395 tcpOutDataBytes =9854298
tcpRetransSegs = 4826 tcpRetransBytes =644526
tcpOutAck = 23486
The total number of segments (tcpOutSegs) is mostly made
up of tcpOutDataSegs and tcpOutAck, although the
numbers don't add up exactly. The protocol is more complex than I have
described here! There is the overhead of a TCP/IP header for every
segment. On Ethernet this overhead is increased by the Ethernet
encapsulation, the minimum size (64 bytes) of an Ethernet packet (which
is enough to hold the IP and TCP headers and six bytes of data), and
the 9.6 microsecond minimum inter-packet gap (equivalent to another 12
bytes at 10 megabits).
You could calculate from all this an approximation to the actual
bit-rate due to TCP on an Ethernet, but you can't figure out all the
other protocols, so it's probably not worth it. I generally just watch
the tcpOutDataBytes value and use
tcpRetransBytes to calculate a retransmission percentage.
Problems with the retransmission algorithm have been fixed in the
latest kernel patches for Solaris 2.4 through 2.5.1. If you see more
than 30 percent retransmissions make sure you have the patch. If you
still see high retransmissions with the latest patch you may have some
bad network hardware that is dropping packets.
The maximum TCP segment size is negotiated on a per-connection basis. For local LAN-based connections it is usually 1500 bytes. I have observed that most connections over the Internet to www.sun.com use 576 bytes, which is much less efficient. The protocol overhead for 1500 byte packets is approximately five percent, for 576 byte packets it is approximately 12 percent.
As many additional small packets are also sent, the actual protocol overhead is worse than this. The retransmission rate over a LAN is usually near zero, but the Internet seems to vary between 10 and 20 percent depending upon traffic conditions at the time. The overhead for sending bulk TCP data can therefore vary from approximately five percent to 30 percent or more. If you are close to saturating an Ethernet, there is even more inefficiency coming from high collision rates.
On the receiving side there are no retransmissions to worry about. The incoming data segments may arrive in the wrong order in some circumstances, so there are two counters, one for in-order and one for out-of-order. You might regard out of order data as a sign of routing problems, but I'm not sure what you could do about it. The total incoming data rate is given by these counters:
tcpInInorderSegs = 63348 tcpInInorderBytes =20318851
tcpInUnorderSegs = 0 tcpInUnorderBytes = 0
There are some other counters for duplicated data and other problems that may occur. Duplicated segments may happen when an acknowledgment is lost or delayed, and the other end retransmits a segment that actually arrived OK the first time.
TCP flow control
TCP has a way to control the flow of data between the two systems. The
receiving system tells the sender how much data it will accept (known
as the receive window). The sender is free to send as many segments as
will fit into the advertised window. When the receiver acknowledges
some data, a new window is sent as part of the acknowledgment. This
normally moves the window on by the size of the data being
acknowledged. If for some reason the program that is reading the data
stops, and the receiver runs out of buffer space, it will still
acknowledge segments, but will not advance the window. This pauses the
transfer.
The size of the window varies. I have observed windows of anything from 512 bytes to 64 kilobytes in transfers from www.sun.com to the many and varied systems running Web browsers out there. SunOS 4 defaults to four kilobytes. Solaris 2 defaults to eight kilobytes. Making the default larger will in general use up more RAM, especially if you have a lot of connections to handle. For most systems that run browsers, however, there are few connections, and a larger default may well help data flow more smoothly over the Internet.
The size of the window that you need depends on something called the
bandwidth-delay product. This is the speed that your connection can run
at multiplied by the time it takes to get a data segment out, and the
acknowledge back. You can get some idea of latencies using the
/usr/sbin/ping -s command, although some machines may turn
off the ICMP echo service that ping uses, or hide behind firewalls that
only allow Web traffic.
If you are on a 10-megabit Ethernet, you should find a latency of about one millisecond. The bandwidth is about one megabyte per second, so the product is one kilobyte. From this you can see that the default window of eight kilobytes is enough for LANs connected through routers as long as the latency stays below eight milliseconds. At 100 megabits-per-second Fast Ethernet or FDDI, the latency is less than one millisecond, and the bandwidth is about 10 megabytes per second. The product is thus less than 10 kilobytes.
This explains why there are only small gains (if anything) to be made by increasing the default window size on local connections over 100-megabit networks. Old, busy, or slow systems that take longer to turn round a reply may benefit more from a larger window.
If you are on a 28.8-kilobit modem, you need to take into account the size of the packet. At three kilobytes per second, a 512 byte packet takes 166 milliseconds to transfer, while an acknowledgment or a ping of 64 bytes will take about 20 milliseconds. If you are connecting over the Internet you may have to add several seconds to the total. If we assume three seconds and three kilobytes per second, the product is nine kilobytes. If you are lucky enough to have a high-speed connection to the Internet, your bandwidth is much higher, but the latency is not much better, you only save the local transfer delay of a few hundred milliseconds. In this case you may find that an eight-kilobyte window is too small, and you don't get much better throughput than you would get over a modem.
The TCP window needs to be increased on the receiving end. It is on the client systems with browsers that a change needs to be made, and there is not a lot that can be done on the Web server. In fact there is a default transmit buffer size on the server, and it may help a bit if it is also increased to match the expected receive window size.
Sometimes a high-speed connection also has high latency, for example over an international satellite link. This may require much larger windows than the normal maximum of 64 kilobytes. There is a TCP window scale option that allows the window size to be multiplied by a power of two up to a gigabyte. For now it is available as a consulting special, but it should appear in a future Solaris release.
Tuning TCP parameters
Network tuning is performed using the ndd(1) command.
Changes take place immediately, and this is a huge improvement on most
other operating systems where a kernel rebuild or reboot is necessary.
The complete list of tunable values can be obtained as shown. I only
show the ones that I'm going to discuss below. I'll tell you how to get
more information on ndd at the end of the article.
# ndd /dev/tcp name to get/set ? ? ... tcp_conn_req_max (read and write) tcp_xmit_hiwat (read and write) ... tcp_recv_hiwat (read and write) ....
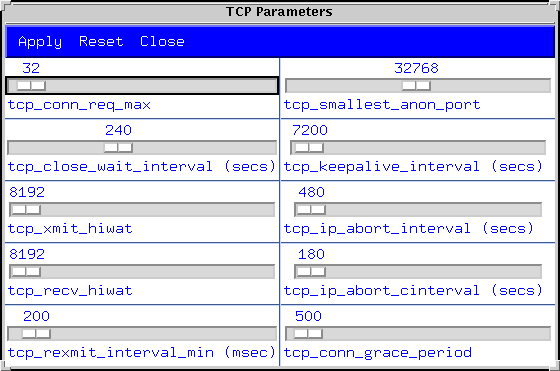
To adjust the listen queue, the parameter tcp_conn_req_max
needs to be adjusted. It can be done interactively, or as an
in-line command. To make it permanent, the command should be
placed in the file /etc/rc2.d/S69inet as shown.
ndd -set /dev/tcp tcp_conn_req_max 1024
The transmit buffer and receive window are controlled by
tcp_xmit_hiwat and tcp_recv_hiwat. If you aren't concerned about using
up extra memory they could both be set to 64 kilobytes using:
ndd -set /dev/tcp tcp_xmit_hiwat 65536 ndd -set /dev/tcp tcp_recv_hiwat 65536
What's in the new Solaris Internet Server Supplement?
This was announced recently so I have to mention it. They took
Solaris 2.5.1 and folded in some TCP features that are going to be part
of Solaris 2.6. This kernel is provided as part of the latest Netra 3.1
Internet server bundle, and is available separately as well. If you run
a dedicated, high traffic Internet server (100 connections per second
or more) this was built for you. If you run a general purpose system,
you should wait for Solaris 2.6. The 2.5.1/ISS release has been well
tested as an Internet server, but has not been tested for general
purpose applications. There are also some complex patch issues, as
normal Solaris 2.5.1 kernel patches will not apply to 2.5.1/ISS.
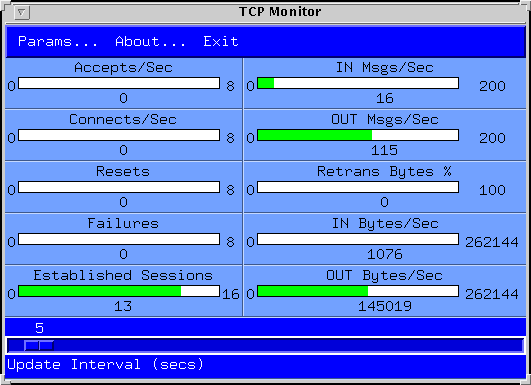
Using the SE Toolkit to monitor TCP
The SE toolkit is a
C-based interpreter that has built-in interfaces that can read and
write any kernel data. As well as the more conventional kvm
and kstat interfaces. It has a `mib' interface to
all the network data, so mib$tcp gets you the entire TCP
data structure that netstat -s shows. It also has an
`ndd' interface so for example reading or writing to
ndd$tcp_conn_req_max is the same as using the ndd
command.
Mike Bennett of Sun took advantage of this to write a GUI based tool that both monitors TCP data, and allows you to tune TCP parameters using sliders if you run it as root. The tool works with the current version of SE, but it is not included in the release, so it is provided here for you to download.
One thing we discovered when reading TCP data is that the mechanism
used to collect data locks TCP as far as new connections are concerned
so that all the parameters are a consistent snapshot. If you are
already saturating TCP on a system, you will find that running
netstat -s takes several seconds and hurts Web server
throughput. Some work has been done in Solaris 2.5.1/ISS to reduce this
effect. When running SE scripts as root, they can read the kernel
directly, and tcp_mon.se uses this to get at the TCP
status data structure directly. The problem with this is that some of
the values (like the current number of connections) are only updated by
the proper access method. You have to choose whether you want fast data
or accurate data.
This is what the main display and the control popup look like:
Wrap up
If you want to know how TCP really works (I tried to keep it
simple) I recommend W. Richard Stevens' book TCP/IP Illustrated
Volume I - The Protocols. Appendix E covers the meaning of the
ndd options for Solaris 2.2. An updated
Appendix E covering Solaris 2.5.1 is
available from Richard's home page.
As with any set of tuning parameters, you can easily wreck your
system if you get carried away. Please take care, don't mess around
with production systems unless you are certain you have a problem, and
make sure you have studied TCP/IP Illustrated really carefully.
![]()
|
|
Resources
About the author
Adrian Cockcroft joined Sun in 1988, and currently works as a performance specialist for the Server Division of SMCC. He wrote Sun Performance and Tuning: SPARC and Solaris, published by SunSoft Press PTR Prentice Hall.
Reach Adrian at adrian.cockcroft@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-12-1996/swol-12-perf.html
Last modified: