The Solaris process model, Part 2We peel back the next layer in our examination of Solaris processes and threads |
September 1998 |
Last month we discussed the Solaris process model at a high level, covering the kernel process table and its associated boundary parameters. We also introduced user threads, lightweight processes, and kernel threads. This month, we'll dig deeper, with a closer look at the kernel data structures and linkages that tie processes, threads, and kernel threads together. We'll also delve into the process creation flow. (2,100 words)
|
Mail this article to a friend |
![]() ll processes are created using the traditional fork/exec Unix
process-creation model. This model was part of the original Unix design, and
is still implemented in virtually every version of Unix in existence
today. Fork and exec are system calls, used extensively in the
various software components that come bundled with Solaris (although
more and more Solaris daemons are getting threaded with each
release). They are also used in thousands of applications that run on Solaris.
ll processes are created using the traditional fork/exec Unix
process-creation model. This model was part of the original Unix design, and
is still implemented in virtually every version of Unix in existence
today. Fork and exec are system calls, used extensively in the
various software components that come bundled with Solaris (although
more and more Solaris daemons are getting threaded with each
release). They are also used in thousands of applications that run on Solaris.
The fork(2) system call creates a new process. The newly created process gets a unique process identification (PID) and is a child of the process that has called fork. The calling process is the parent. The exec(2) system call overlays the process with an executable specified as a path name in the first argument to the exec(2) call. The model, simply put, looks like this:
main(argc, char *argv[], char *envp[])
{
pid=fork();
if (pid == 0)
exec(new_program,...);
else if (pid > 0)
wait();
else
error(fork failed)
}
In the above pseudo code, a fork(2) call is made, and the return value from fork(2) -- pid -- is checked. Remember, once fork(2) executes successfully, there are two processes. Fork returns a value of zero to the child process, and the PID of the child to the parent process. In the example, we called exec(2) to execute new_program once in the child. Back in the parent, we simply wait for the child to complete. (We'll get back to this notion of waiting later.) Here's a simple example to drive the point home.
sunsys> cat p1.c
#include <sys/types.h>
#include <sys/proc.h>
#include <unistd.h>
#include <stdio.h>
main()
{
pid_t pid;
pid=getpid();
printf("Parent PID: %d\n",pid);
fork();
pid=getpid();
printf("PID: %d\n",pid);
exit(0);
}
sunsys> gcc -o p1 p1.c
sunsys> p1
Parent PID: 807
PID: 807
PID: 808
sunsys>
The program "p1" above illustrates the fork(2) model pretty well. After getting the PID of the parent process and printing it out, fork(2) is called, another getpid(2) is executed, and the PID is printed again. Note that when we run the program, the second getpid(2) call following the fork(2) outputs two PIDs. That's because once the fork(2) executes, we are running two processes. Everything below the fork(2) is part of both -- so they both execute the same code. And, of course, they each have a unique PID number.
The next example adds the exec(2) call:
sunsys> cat p2.c
#include <sys/types.h>
#include <sys/proc.h>
#include <unistd.h>
#include <stdio.h>
main(int argc, char *argv[], char *envp[])
{
pid_t pid;
pid=getpid();
printf("Parent PID: %d\n",pid);
pid=fork();
if (pid ==0)
execvp("/space/jim/swol/sep98/c1", argv);
else if (pid > 0)
wait(NULL);
else
perror("fork failed");
exit(0);
}
sunsys> cat c1.c
#include <unistd.h>
main()
{
pid_t pid=getpid();
printf("Child PID: %d\n",pid);
}
sunsys> p2
Parent PID: 871
Child PID: 872
sunsys>
Here, we first show the two source programs: p2.c, which is the parent, and c1.c, which is the child. When the p2 program executes, we get expected output. This time, the parent does a getpid(2) call and displays its PID. We also get a PID from the c1 child program that we execute after the fork, inside the newly created child process. The exec(2) is called where the return value from fork(2) is a zero, which means we are in the child. In the parent after the fork, we call wait(2), which waits for the child to complete.
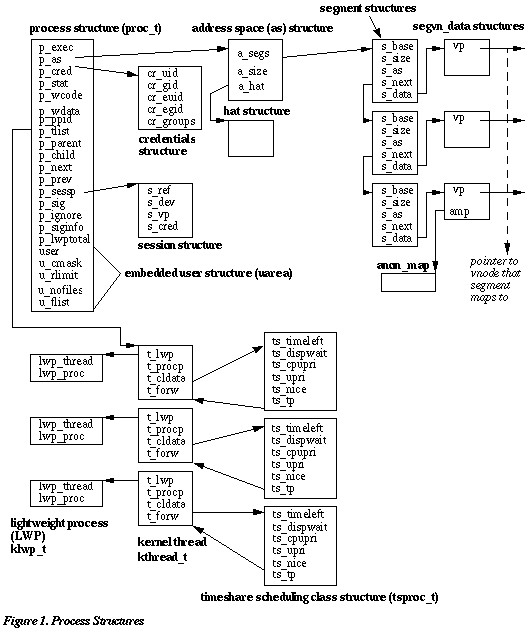
Examining the data structures
Let's take a closer look at the data structures related to
processes. Then, we'll get into the flow of process creation in
more detail. Reference Figure 1 below.
|
sunsys> ps PID TTY TIME CMD 437 pts/6 0:01 ksh sunsys> pmap -x 437 437: /bin/ksh Address Kbytes Resident Shared Private Permissions Mapped File 00010000 180 180 180 - read/exec ksh 0004C000 8 8 4 4 read/write/exec ksh 0004E000 36 32 - 32 read/write/exec [ heap ] EF620000 12 12 12 - read/exec libmp.so.2 EF632000 4 4 4 - read/write/exec libmp.so.2 EF640000 588 524 496 28 read/exec libc.so.1 EF6E2000 24 24 4 20 read/write/exec libc.so.1 EF6E8000 8 8 - 8 read/write/exec [ anon ] EF700000 444 304 304 - read/exec libnsl.so.1 EF77E000 32 32 4 28 read/write/exec libnsl.so.1 EF786000 24 - - - read/write/exec [ anon ] EF7A0000 32 32 32 - read/exec libsocket.so.1 EF7B7000 4 4 4 - read/write/exec libsocket.so.1 EF7B8000 4 - - - read/write/exec [ anon ] EF7C0000 4 4 4 - read/exec/shared libdl.so.1 EF7D0000 112 112 112 - read/exec ld.so.1 EF7FB000 8 8 4 4 read/write/exec ld.so.1 EF7FD000 4 4 - 4 read/write/exec [ anon ] EFFFD000 12 12 - 12 read/write/exec [ stack ] -------- ------ ------ ------ ------ total Kb 1540 1304 1164 140 sunsys>
In this example, I did a ps(1) with no arguments to get the PID of my Korn shell process (ksh), and displayed the extended address-space mapping information (the -x flag to pmap(1)). Obviously, pmap(1) does not traverse and display all the data structure information shown in Figure 1. The procfs interface, which is what pmap(1) uses (as well as all the /usr/proc/bin commands), maintains address space information in the as structure in the /proc/PID/as hierarchy. We'll get back to procfs a little later.
A process is often described simply as the executable form of a program. As such, the program itself must first exist as an executable file on disk in a file system, which gets loaded when the process is started (executed). The p_exec member of the process structure points to the vnode for the executable file. As we've discussed in the past, file modes determine if a file is executable, and whether system users have permission to execute, read, or write a file. Permission checks are done against the effective user ID (UID) and group ID (GID) of the user, who is typically attempting an operation on a file via a shell -- which is, of course, a process. The user credentials are maintained in a separate structure, the credentials structure, which is indicated by the p_cred pointer in the proc structure. This is where all user credentials are maintained -- including the real and effective user and group IDs, and an array of GIDs for additional groups that the user belongs to.
|
|
|
|
|
Go with the flow
Let's get back to the process creation flow, as it will provide a
good foundation for discussing other key areas of the Solaris
process model.
When the fork(2) system call is entered, the kernel allocates a process
table slot in kernel memory (the process_cache), sets the
process start time field (p_mstart), and sets the process state
to SIDL, which is a state flag to indicate that the process is in an
intermediate "creation" state. The kernel then assigns a PID to the
process and allocates an available slot in the /proc directory for
the procfs entry. The process session data is copied to the child,
in the form of the session structure, which maintains the process
controlling terminal information. The process structure pointer
linkage between the parent and child is established (reference
Figure 1 -- the p_child and p_parent pointers), and the uarea of the
parent process is copied into the newly-created child process
structure.
The Solaris kernel implements an interesting throttle here in the event of a process forking out of control, as such a process will consume an inordinate amount of system resources. A large amount of process creation activity is indicated by failure in the kernel pid_assign() code (which is where the new process PID is acquired) or the lack of an available process-table slot. In this circumstance, the kernel implements a delay mechanism, which forces the process that issued the fork call to sleep for an extra clock tick (10 milliseconds). The throttle ensures that there will be no more than one fork failure per CPU per clock tick. The throttle will also scale up, such that an increased rate of fork failures results in an increased delay before the code returns the failure and the issuing process can try it again. In such a situation, you'll see the console message "out of processes." In addition, in the sar -v output, the overflow (ov) column to the immediate right of the process table values (proc-sz) column will have a non-zero value. Also, you can look at the kernel "fork_fail_pending" variable with adb. If this value goes non-zero, the system has entered the fork throttle code segment.
Aug 9 21:55:44 sunsys last message repeated 4584 times Aug 9 21:55:44 sunsys unix: out of per-user processes for uid 1001 # adb -k /dev/ksyms /dev/mem physmem fdde fork_fail_pending/D fork_fail_pending: 1 $q #
In the above example, I started a program that forks in a tight while loop, to create the out-of-control forking process. I cut the text from my console window, and you can see the "out of per-user processes for uid 1001" message generated by the kernel. I then examined the fork_fail_pending value, and it had in fact been set to one (it's normally zero).
There are actually a couple of different flavors of fork(2) available in Solaris that take different code paths from this point in the process creation sequence. The traditional fork(2) call duplicates the entire parent process, including all the threads and lightweight processes (LWPs) that exist within the process when the fork(2) is executed. A variant of fork(2), fork1(2), was added in Solaris 2.X along with thread support. In the fork1(2) call, only the thread that issues the fork1(2) call and its associated support structures get replicated. This is extremely useful for multithreaded programs that also do process creation, as it reduces the overhead of replicating potentially tens or hundreds of threads in the child process. Note that the behavior of fork can also be modified by linking with a particular threads library. Linking with the Solaris threads library (-lthread compilation flag) will result in the described replicate-all fork(2) behavior. Linking with the POSIX threads library (-lpthread) will result in a call to fork(2) replicating only the calling thread. In other words, linking with -lpthread (POSIX threads library) and calling fork(2) results in fork1(2) behavior. The different behaviors are often referred to as fork-all and fork-one when referenced in papers and some books I've read.
Finally, there's vfork(2), which is described as a "virtual-memory-efficient" version of fork. A call to vfork(2) results in the child process "borrowing" the address space of the parent rather than the kernel duplicating the parent's address space for the child, as it does in fork(2): The child's address space following a vfork(2) is the same address space as the parent. The child actually executes using the same virtual memory pages as the parent. The implication here is that the child must not change any state while executing in the parent's address space until it either exits or execs. Once an exec(2) call is executed, the child gets its own address space.
In fork(2) and fork1(2), the address space of the parent is copied for the child via the kernel address space duplicate (as_dup()) routine. In this case, each segment of the parent processes' address space is duplicated, beginning with the initialization of an address space (as) and hardware address translation (hat) structure for the child process. Once an initialized address space structure is available in the child proc structure, we loop through all the segments in the parent, duplicating each one for the child. Once completed, the child process has a replica of the parent address space, for the most part. Memory locks the process may have set to lock segments of the address space in memory (using one of several available APIs to do this -- plock(3C), memcntl(2), mlock(3C), etcetera), do not get replicated.
The other bits of the parent process that get inherited by the child are the aforementioned credentials structure (real and effective UID and GID), open files, the parent's environment (the environment list includes typical environmental variables such as HOME, PATH, LOGNAME, etcetera), mode bits for set UID or set GID, the scheduling class, the nice value, attached shared memory segments, current working and root directories, and the file mode creation mask (umask). For a more complete list of process members that are inherited, see the fork(2) man page.
Process state and structure components that are not inherited by the child include file record locks. (The open files are inherited; the file locks set via fcntl(2) are not.) Pending signals to the parent are cleared in the child, and resource utilization metrics are set to zero (the rlimit values).
The scheduling class information is also inherited by the child. Each LWP has its own scheduling class structure: Different threads in a process can execute in different scheduling classes. The notion of scheduling classes came over from Unix SVR4. Initially, Solaris supported three scheduling classes, two of which were available to users. The timeshare (TS) scheduling class provides behavior that pretty much follows the traditional notion of timeshare systems -- as processes run, their priority gets worse; as they wait, their priority gets better. It's designed to provide a fairly even distribution of hardware processor resources to all processes and threads. The realtime (RT) scheduling class provides some degree of realtime application support. Realtime applications require bounded, predictable latencies for getting processor time, and need to stay on a processor for as long as they need it. Basically, timeshare threads get to run until their time quantum runs out; realtime threads run until they voluntarily surrender the processor.
The third scheduling class is the system class, which is reserved for use by the operating system. Finally, Solaris added the interactive (IA) class, which was designed to provide snappier behavior for desktop systems. This class takes the process attached to the input focus of the user's window and bumps it to the top dispatch queue for processor execution.
Next month, we'll get into the scheduler in detail. We'll look at the
dispatch tables for the various scheduling classes, the end-user
admin commands for controlling and changing priorities and classes, and
the behavior of the user-level threads scheduler.
![]()
Resources
About the author
Jim Mauro is currently an area technology manager for Sun
Microsystems in the Northeast, focusing on server systems,
clusters, and high availability. He has a total of 18 years of industry
experience, working in educational services (he developed
and delivered courses on Unix internals and administration) and
software consulting.
Reach Jim at jim.mauro@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-09-1998/swol-09-insidesolaris.html
Last modified: