How to construct your cluster configuration, Part 2: Plugging in
Notes on implementation and testing before you go live
August 1999
|
|
How to construct your cluster configuration, Part 2: Plugging inNotes on implementation and testing before you go live |
August 1999 |
Last month, Peter described the ins and outs of clustering -- in theory. This month that theory meets reality, as he describes the implementation details and the status of his Sun Enterprise 10000 cluster rollout. (2,400 words)
|
Mail this article to a friend |
Peter Baer Galvin Objective: To find a challenging and rewarding job that does not involve clustering computers...
![]() finished last month's column hours before the rollout of the new Sun
cluster on which I was working. Fortunately, the rollout was a success. It
was not without its challenges, however. First up this month are
some details of the implementation and testing; then come the
implementation results. Of course, plenty of those aforementioned
challenges are detailed here as well.
finished last month's column hours before the rollout of the new Sun
cluster on which I was working. Fortunately, the rollout was a success. It
was not without its challenges, however. First up this month are
some details of the implementation and testing; then come the
implementation results. Of course, plenty of those aforementioned
challenges are detailed here as well.
Implementing the shared storage
Architecting a supported and well performing Sun Cluster 2.X
facility is still a challenge. For starters, let's look at the issue
of storage. SCSI has never been a happy participant in multiple
host scenarios. It was designed to allow one host to talk to a
string of devices, or multiple strings of devices. It has now been
folded, spindled, and mutilated to the point that it -- grudgingly -- allows two hosts can talk to a given device string. Each host is an initiator of SCSI
commands on the SCSI bus. Attaching two hosts to a SCSI chain is
called multi-initiator SCSI -- and it is ugly.
Sun only supports multi-initiator SCSI in Sun Cluster configurations. That means that you can't take two Sun servers and share a SCSI disk storage unit between them unless you're running the Sun Cluster software -- if you're still planning on getting support from Sun, anyway. Veritas is a little more forgiving, supporting the use of Volume Manager to manage a SCSI shared storage device. Of course, if there is a problem with your facility, Sun may refuse to provide support and send you crying to Veritas.
Another difficulty comes from the SCSI numbering convention. Every SCSI device must have an ID number unique on its chain, including the SCSI controller itself. By default, every Sun host sets the SCSI ID of its controller cards to 7. 0 through 6 are allowed for the devices on a nondifferential chain. For differential SCSI, 0 through 6 and 8 through 15 are allowed. Now, consider two SCSI hosts with various SCSI devices sharing a Sun UltraSCSI storage device (such as an A1000 or A3500). Both hosts will try to use ID 7 -- leaving two devices (the hosts) on the shared chain with the same SCSI ID. This violates the SCSI protocol and will cause all sorts of nasty problems, SCSI resets and the failure of systems to boot among them.
Figure 1 shows just such a situation. If Host A and Host B were booted in the configuration shown in the figure, they would likely hang. The problem is that, on the shared storage SCSI bus, there are two SCSI devices with ID 7 (the two hosts). To fix the problem, a free SCSI target ID must be found on one of the hosts. For instance, Host B has IDs 4, 5, 6, and 7 in use. Therefore, the ID of the SCSI controllers (the SCSI initiator ID) on that host can be set to one of the free numbers. This change would avoid the collision of SCSI ID 7 on the bus that drives the shared disk chain.
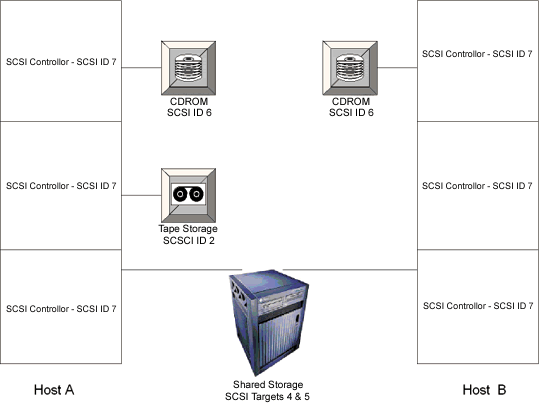
Figure 1. Problem with shared storage |
One problem is that you need to create a SCSI map like this to make
the proper choice of SCSI IDs. Unfortunately, it is a manual
process. Because Sun machines set all SCSI cards in the
host to the same initiator ID, one host has to find an unused SCSI
ID on all of its SCSI chains. This is accomplished by careful use of
the probe-scsi-all EEPROM command. Be careful here, because
that command can hang the system if it is not executed after a clean
reset. The steps to accomplish such a reset are:
OK prompt, use setenv auto-boot? false to disable automatic booting after a reset
reset to clear the system
probe-scsi-all to get a list of all target IDs
setenv auto-boot? true to reenable automatic booting after
resets
With that accomplished, connect the to-be-shared storage to one of the hosts in
question. Then, perform the probe-scsi-all magic and
search the resulting SCSI ID lists for an unused ID, on all SCSI
buses, under 8. Even though differential SCSI allows IDs greater
than 7, only the original nondifferential numbers work for this
procedure. At this point, you have a SCSI address under 8 that is
unused within the system. The final step is to tell the system to
use that number as the SCSI ID for its own SCSI controllers. This is
accomplished by setting the EEPROM variable scsi-initiator-id to
that value. The value is only read at system reset time, so follow
the setting of this value with a reset. When the system
starts booting, it will display a message for each SCSI controller
indicating that the controller's ID has been set to the value of
that variable. Finally, the shared storage unit can safely be
attached to both systems, and the requisite boot -r will
find the device.
This resolution of SCSI target address conflicts is only slightly more pleasant than driving into Boston during rush hour. Fortunately, the future looks bright. For instance, fibre channel and fibre channel arbitrated loop (FCAL) do not suffer the embarrassment of requiring preset unique addresses. They allow more than one host to attach to the fibre to communicate with the storage. They also allow for hot-attach and -detach of devices to the loops.
FCAL from Sun is currently limited to two hosts per loop. Why, then, if you need to create a shared storage solution, would you ever use SCSI storage devices? The simple answer is that Sun's FCAL solutions are appropriate in some, but not all, circumstances. They are very fast for sequential I/O, but not for random I/O. Random writes are especially problematic because there is no nonvolatile cache in which to hold the writes. Instead, they must be transferred all the way to the disk before the write is considered complete. Why doesn't Sun include a cache and controller on its FCAL devices? The unofficial explanation is that there isn't (currently) a controller that can keep up with FCAL's throughput performance. Rather than slow down the whole device, Sun keeps SCSI devices with caches for random write duty, and FCAL without cache for sequential I/O duty.
More information about Sun's storage offerings can be found in my January 1999 Pete's Super Systems column.
Once the proper Sun cluster facility is architected and servers purchased, the installation of the cluster is straightforward: you pay Sun to do it. Sun engineers install the hardware and software, including all of the heartbeat bits and the cluster monitor.
Data transfer from old facility to new
Of course, before this facility can move to production, several
other steps are needed. If the system is replacing an existing one,
then current data must be moved to the new system. In the instance
of the dual E10000 cluster, this phase took the most discussion,
debate, planning, testing, and implementation time. The details of
how to move production data from one facility to another may be
worthy of coverage in a future column. (If you are interested in
this topic, drop me a line.)
|
|
|
|
|
Testing the finished product
Frequently, testing reveals things for which planning failed to account. The
more complex the project, the more important and thorough the test
should be. The theory is sometimes easier than the fact. In this
project, schedules were very tight (due to Y2K pressures and Sun
ship dates). Another week or two of testing would have made everyone
more comfortable.
The tests covered the following areas:
Our testing revealed some issues that needed to be resolved before the facility could move to production. For instance, a single disk failure in the A3500 caused the controller (and sometimes the pair) to reset or hang. Obviously, that should not be the case. The problem was traced to a lack of grounding on the A3500s. When electrical devices are attached in sequence (say, when a disk cabinet is attached to two separate systems) grounding grows in importance. Once properly grounded, the disk arrays behaved as expected.
Another problem resulted in Oracle crashing under load. Again, this doesn't have a pleasant result. In this case the problem was a bug in some versions of the kernel jumbo patch that only affected E10000s. A couple of core dumps dispatched to Sun and Oracle resulted in Sun generating a patch to solve the problem.
When planning and scheduling testing, it's important to leave yourself time to repeat those tests. In our case, once the two problems described above were found and fixed, another full round of testing was required to be sure that they were really fixed, and that there weren't any other problems lurking behind them. For instance, there could have been another Oracle bug that was never seen because Oracle crashed before the second bug was triggered.
Final cluster thoughts
System availability is measured along a continuum. At the "less
available" end, there are single systems with no redundant
components and no recoverability features (PCs running lesser
operating systems, for instance). At the other end are machines like the Tandems
with true fault tolerance (every instruction is executed on multiple
CPUs, and the results compared to assure proper execution) and full,
remote disaster recovery sites with live data replication. Most
facilities fall in between those extremes. The cheapest insurance
for Suns is the use of RAID storage and enterprise-class servers
with N+1 power, cooling modules, a hot plug/hot swap
system, and I/O boards. Beyond that, clusters add an extra level of
insurance. Current cluster technology works well but requires care
to architect, implement, test, and roll out to production.
Once a cluster is running, the work continues, in the form of monitoring and maintenance. Even a cluster can fail if single component failures go unnoticed and uncorrected.
One final thought: it's cool to call into Sun service with an E10000 serial number. It gets the staff's attention. It's even more fun to place a service call on an E10000 cluster. They are automatically priority one, and seemingly everyone within the area code of your cluster gets paged!
Credit where credit is due
The dual E10000 project was successful; it met its
schedule and has so far matched facility reliability goals. The great team at the
client site was responsible for the vast majority of the testing and
implementation of the facility. High pressure, short deadline, big
dollar major company impact projects only succeed with talented
people playing major roles. In this case Rick, Doug, Mark, Tareq,
Debbie, Nelsy, Feng, and Javier -- along with the Sun team -- were the keys to its success. Oh
yes, and Liz!
Next month
Many systems administrators arrive to work in the morning (or early
afternoon), leave later in the day, and realize that they "got
nothing done." Fire fighting is a hazard of the profession, but
there are general and specific ways to move out of fire-fighting
mode and regain control of your schedule and to-do list. Next month
Pete's Super Systems discusses such potential conflicts
and tries to provide some solutions.
![]()
|
|
Resources
About the author
![]() Peter Baer Galvin is the chief technologist for
Corporate Technologies, a systems
integrator and VAR. Before that, Peter was the systems manager for
Brown University's Computer Science Department. He has written articles
for Byte and other magazines, and previously wrote Pete's Wicked World, the security column for SunWorld. Peter is coauthor of the Operating Systems Concepts textbook. As a consultant and trainer, Peter has taught tutorials on security and system administration and given talks at many conferences and institutions.
Peter Baer Galvin is the chief technologist for
Corporate Technologies, a systems
integrator and VAR. Before that, Peter was the systems manager for
Brown University's Computer Science Department. He has written articles
for Byte and other magazines, and previously wrote Pete's Wicked World, the security column for SunWorld. Peter is coauthor of the Operating Systems Concepts textbook. As a consultant and trainer, Peter has taught tutorials on security and system administration and given talks at many conferences and institutions.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-08-1999/swol-08-supersys.html
Last modified: