Turnstiles and priority inheritanceLast month's coverage of sleep queues and the sleep/wakeup mechanism in Solaris provides a perfect springboard for this month's topic -- turnstiles |
August 1999 |
Last month, Jim described the implementation of sleep queues in Solaris, and how, in conjunction with condition variables, they provide the framework for kernel thread sleep and wakeup. This month, he looks at another method employed for handling sleep and wakeup in Solaris -- turnstiles. He'll also cover the kernel implementation of priority inheritance. (4,000 words)
|
Mail this article to a friend |
Building such systems presents several challenges. It can be difficult getting scalable performance through concurrent execution of kernel code; protecting critical state so that multiple processors are not manipulating the same set of data at the same time (for example, adjusting pointers to the same data structure on a linked list) can be problematic as well. This is where mutex locks and reader/writer locks come in. Locks are created, initialized, and designed to synchronize access to kernel data structures; kernel code is then written that complies with the locking scheme. The lock must be acquired before data can be written or read. Mutex locks are binary in nature; only one lock holder is allowed at time. Reader/writer locks are implemented in situations where it is safe to allow multiple reads, but only one write, of data at any given moment.
Solaris implements two flavors of mutex locks, adaptive and spin. When a kernel code segment attempts to acquire a mutex lock, and the lock is being held, the thread can do one of two things: spin or block. Spinning on a mutex means simply executing a tight loop, with lock acquisition attempted in each pass through the loop. Blocking means putting the thread to sleep. There are pros and cons to both approaches. Spinning has the advantage of not requiring a context switch off the processor, such that, once the lock is acquired, execution continues. The downside is that a processor is consumed during the spin. Blocking frees up the processor, as the blocked thread is put to a sleep state and context switched off the processor, freeing it up for other work. It does, however, require the overhead of context switching the thread back in once the lock is available, and the general overhead of dealing with a wakeup mechanism.
Adaptive mutex locks deal with the above choices in a dynamic fashion. If a mutex lock is currently owned by another thread when a kernel thread attempts to acquire the lock, the state of the thread is examined. If the thread holding the lock is running, the kernel thread trying to get the lock will spin, based on the assumption that the running thread will release the lock in relatively short order. If the holder is sleeping, then the thread wanting the lock will also block (sleep), because it doesn't make sense to consume a processor spinning and waiting for the holder to wake up and release the lock. Most mutex locks in the Solaris kernel are adaptive. Spin locks are used only for locks held at high system priority levels (above level 10 -- high-priority interrupt handlers), where context switching is not allowed (more on this next month).
In the event of a kernel thread blocking on a mutex, or a reader/writer lock (reader/writer locks are not adaptive -- a held write lock will always result in a sleep), turnstiles are used to manage the sleep queues and synchronize the wakeup when the lock is available.
The last bit of background information we need before going into the details of turnstiles involves a problem known as priority inversion. Picture a scenario in which a high-priority thread needs a lock in order to execute, but the lock is being held by a lower-priority thread. In essence, the lower-priority thread is preventing a higher-priority thread from executing. This is the priority inversion problem. Solaris addresses this problem with a scheme known as priority inheritance, where the higher priority thread can will its global dispatch priority to the lower priority thread holding the lock. The lower-priority thread inherits the higher priority, and is therefore able to get scheduled sooner so it can complete the process of releasing the lock. At this point, it will be reassigned the priority it had prior to the inheritance.
A final note before getting into the specifics of turnstiles.
Solaris 2.6 added a new utility called lockstat(1M), which is built
on a pseudodevice (/dev/lockstat) and driver in the kernel.
lockstat(1M) reports statistical information on mutexes, both
adaptive and spin, and reader/writer locks. This utility is, of
course, available in Solaris 7 as well, but not in releases prior to
Solaris 2.6.
Turning our attention to turnstiles
A turnstile is a data abstraction that encapsulates sleep queues and
priority inheritance information associated with mutex locks and
reader/writer locks. The implementation of turnstiles was changed
substantially in Solaris 7, although the underlying premise has remained the
same. We'll begin by looking at the 2.5.1/2.6 mechanism, and then
get into what changed in Solaris 7.
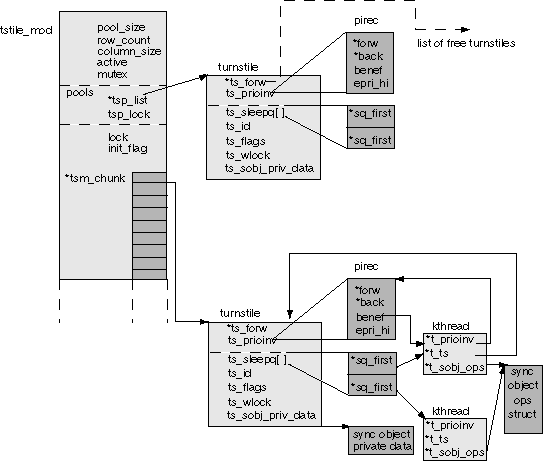
Figure 1. Structure of tstile_mod |
The tstile_mod structure is where it all begins. It maintains the
links to the turnstiles, as well as various fields required for
implementation, such as the number of turnstiles in the pool, number
of active rows in the tsm_chunk array, number of active turnstiles,
a link to the pool of turnstiles, and an array of pointers to chunks
of turnstiles (tsm_chunk[] -- these are the active turnstiles). The
turnstile itself maintains a forward link to other turnstiles on the
list, a structure with priority inheritance information (pirec), and
an array with two sleep queues; for reader/writer locks, readers and
writers are kept on separate sleep queues, while only one of them
is used for mutex locks. As we saw last month, the sleep queue points to
the kernel thread on the queue (sq_first). Other links that bind it
all together include kernel thread links to the turnstile (set when
a kthread is blocking on a synchronization object), and a point from
the kthread to the pirec structure if the priority of the kernel
thread was changed due to priority inversion. The benef
field of pirec points back to the kernel thread that is the
recipient (benefactor) of a better priority due to inheritance.
The kernel creates a small pool of turnstiles at boot time and
allocates a turnstile from the pool when a thread needs to block on
a mutex or reader/writer lock. This pool is the list of turnstiles
linked off tsp_list in Figure 1. The turnstile is returned to the
available pool when the thread is woken up. The code attempts to
maintain a pool of turnstiles that keep pace with the number of
kernel threads on the system by looking at the turnstile pool every
time the internal thread_create() function is called to create a new kernel thread. If the number of kernel threads is greater than the
number of turnstiles in the pool when a kernel thread is created,
the code will dynamically allocate more turnstiles for the pool.
When an executing kernel thread requires a lock, it calls either
mutex_enter() or mutex_tryenter(), passing either function the
address of the mutex lock it's trying to acquire. mutex_enter() is
called more frequently; mutex_tryenter() will return immediately if
the lock can not be acquired, whereas mutex_enter() will result in
the typical spin or block behavior if the lock is held. The
mutex_tryenter() routine exists for situations in which the calling
code cannot afford to spin or block if the required mutex is not
immediately available. One such use of mutex_tryenter() is as a
"function-is-running" flag, where a kernel function grabs a mutex
when the function starts. If another kernel thread makes the same
function call, it makes a mutex_tryenter() call upon entry; and if
mutex_tryenter returns an error (the lock is held), we know
another thread is running the function. Let's take a look at the
flow of a mutex_enter() call, and see where turnstiles and priority
inheritance kick in.
The mutex_enter() function checks the lock type (adaptive or spin) that
is established when the lock is created and initialized. If
the lock is a spin lock, and it is being held, the code enters a
spin loop, trying to acquire the lock with each pass through the
loop. If the lock is adaptive, and currently being held, the code
checks the state of the thread holding the lock. If the holder is
running, a spin loop is entered; if not,
the kernel thread that made the
mutex_enter() call and originally requested the lock is set to block (sleep). As a note, the code
segment that is entered for adaptive locks is where the
mutex_adaptive_lock_enter field in the processor's sysinfo structure
is incremented. The number of adaptive lock enters is reflected in
the smtx column in mpstat(1M).
When a lock is being held and the
holder is not running, it's time to get a turnstile to set the
requesting thread up for sleep. A turnstile is allocated from the
pool of turnstiles, and the relevant structure fields are
initialized. Both the turnstile structure and adaptive mutex
structure contain fields used by the kernel as part of the overall
implementation. An adaptive mutex structure contains a field that
stores the ID of the turnstile awaited by the thread. If the
waiters field is zero (that is, there are no threads waiting), a turnstile is allocated from
the pool, the waiters field in the mutex is set to the turnstile ID
of the turnstile just allocated, and the turnstile's
ts_sobj_priv_data (turnstile synchronization object private
data) field is set to point to the address of the adaptive mutex
structure. Otherwise, if a thread is already waiting for the mutex,
the address of the turnstile that has already been allocated for the
mutex is retrieved.
In either case, we now have a turnstile for the synchronization
object (the adaptive mutex), and we can proceed with changing the
thread state to sleep and setting up the sleep queue associated with
the turnstile. The kernel t_block() function is called for this
purpose, and the CL_SLEEP macro is invoked. Remember from previous
columns that the scheduling-class-specific functions are invoked via
macros that resolve to the proper function based on the scheduling
class of the kernel thread. In the case of a TS or IA class thread,
the ts_sleep() function is called, and the thread's priority is set to a SYS priority. This is a priority boost -- when it wakes up, it will get to run above TS and IA priorities -- and the thread state is set to
TS_SLEEP. The kernel thread's t_wchan field (wait channel) is set to
the address of the synchronization object operation's vector -- an
array of functions specific to the adaptive mutex object. Recall
from last month that a link to a similar set of functions is done
for sleep queues. In the case of turnstiles, the different
synchronization object's turnstiles are used to define an operation's
vector, which is a simple data structure that contains the object
type, the address of the owner, and unsleep and priority change
functions specific to the object. A synchronization object
operation's structure is declared for all of the sync objects that
exist in the Solaris kernel. Here's the structure definition from
/usr/include/sys/sobject.h:
/*
* The following data structure is used to map
* synchronization object type numbers to the
* synchronization object's sleep queue number
* or the synch. object's owner function.
*/
typedef struct _sobj_ops {
char *sobj_class;
syncobj_t sobj_type;
qobj_t sobj_qnum;
kthread_t * (*sobj_owner)();
void (*sobj_unsleep)(kthread_t *);
void (*sobj_change_pri)(kthread_t *, pri_t, pri_t *);
} sobj_ops_t;
Finally, the thread's t_ts field is set to the address of
the turnstile, and the thread is inserted on the turnstile's sleep
queue. The sleep queue functions we discussed last month are invoked
indirectly through marcos defined in the turnstile header file
(insertion of the thread on a sleep queue is done through the
TSTILE_INSERT macro that calls the kernel's sleepq_insert() function).
When it's all done, the kernel thread resides in the sleep queue
associated with the turnstile (as depicted in Figure 1), and the
kernel thread's t_ts field is set to reference the address of the
turnstile. A kernel thread can only be blocked on one, and no more
than one, synchronization object at any point in time. So, t_ts will
either be a null pointer or a pointer to a single turnstile.
We're not quite done -- now it's time for the priority
inheritance check to determine if the thread holding the lock is at
a lower (worse) priority than the thread requesting the lock (the
one that was just placed on a turnstile sleep queue). The kernel
pi_willto() function is called, and the priority of the mutex
owner is checked against the thread waiting. If the owner priority
is greater than the waiting thread's priority, we do not have a priority
inversion condition, and the code just bails out. If the waiter
priority is greater than the owner, we do have a priority inversion
condition, in which case the priority of the mutex owner is boosted to
that of the waiter. The t_epri field of the kernel
thread is used for inherited priorities, and a nonnull value in
t_epri will result in the inherited priority of the thread being
used when it's time to place the thread on a dispatch queue (after
the wakeup) for scheduling.
At this point, the turnstile has been set, with the waiting thread
on the turnstile's sleep queue; the potential for a priority inversion
problem has been checked; and a priority inheritance, if needed, has been performed.
The kernel now enters the dispatcher swtch() function to find the
best runable thread on a dispatch queue and run it, resulting in
the executing kernel thread relinquishing the processor.
The scenario for a reader/writer lock is essentially the same. When an attempt is made by a kernel thread to acquire a reader/writer lock, and the lock is currently being held (owned) by another thread, the turnstile functions are called to allocate a turnstile (or set the turnstile pointer if a turnstile already exists for the lock, meaning that there is at least one other thread waiting). The kernel thread is then placed on a sleep queue associated with the turnstile. As we noted earlier, a turnstile associated with a reader/writer lock will maintain two separate linked lists of sleep queues -- one for readers and one for writers.
The wakeup mechanism is actually quite simple. The convention for
using locks in the kernel requires that a call to a synchronization
object enter routine (mutex_enter() or rw_enter(), for example) is
followed at some point by a exit call (mutex_exit() or rw_exit(), for example),
which releases the lock being held. For an adaptive mutex or a
reader/writer lock, the release function checks the waiters field
maintained in the synchronization object. If there are waiting
kernel threads, a turnstile macro, TSTILE_WAKEONE(), is referenced,
which results in the sleepq_wakeone() function being invoked. The highest
priority thread on the turnstile's sleep queue will be woken up
through the scheduling-class-specific wakeup routine and placed on
the appropriate dispatch queue based in its priority (a SYS priority in this case
-- remember, the thread was given a SYS priority when it was put to
sleep; upon wakeup it would get scheduled before any TS and IA
class threads). Once executing, it'll make another grab at the sync
object for which it was blocking. The turnstile can now be returned to the
pool of available turnstiles.
|
|
|
|
|
So what's different in Solaris 7?
As we mentioned earlier, the implementation of turnstiles in Solaris 7
was rewritten; a significant amount of code was removed, and some new,
more efficient functions were developed. Turnstiles are maintained in a
system-wide hash table, turnstile_table[], which is an
array of turnstile_chain structures. Each entry in the
array is a turnstile_chain structure, and is the beginning
of a linked list of turnstiles for the same lock. The array is indexed
via a hash function on the address of the synchronization object (the
mutex or reader/writer lock). The turnstile_table array,
shown below in Figure 2, is statically initialized at boot time.
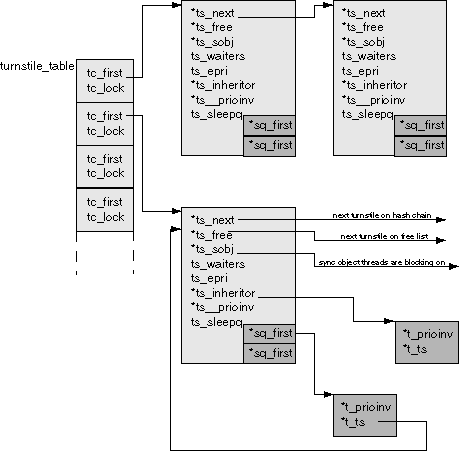
Figure 2. Structure of turnstile_table |
Each entry in the chain has its own lock, allowing chains can be
traversed concurrently. The turnstile itself has a different look;
for each chain, there is an active list (ts_next) and a free
list (ts_free). There is also a count of threads waiting on the sync
object (waiters), a pointer to the synchronization object (ts_sobj),
a thread pointer linking to a kernel thread that had a priority
boost through priority inheritance, and the sleep queues. As with
the 2.6 implementation, there are two sleep queues per turnstile. Note that
the priority inheritance data is integrated into the turnstile, so
there is no longer a pirec structure.
New turnstile functions were developed to support the new model
and integrate the priority inheritance functionality. In prior
releases, the priority inheritance code was a distinct set of kernel
routines (the pi_willto() function to which we referred earlier, for example). The
general sequence of events is the same across all the releases.
Let's take the same sample situation from our previous section in which a kernel thread executes a
mutex_enter() or rwlock_enter() call to grab a lock, and the lock
is currently being held by another thread -- and see what happens when it occurs on a Solaris 7 system. As above, in the case of
an adaptive mutex with the owner not running, the caller will block
(for reader/writer locks, the caller always blocks if the lock is
owned). The changes in Solaris 7 result in a call to look up the
turnstile for the synchronization object in the turnstile_table[].
We index the array by hashing on the address of the sync
object; so, if a turnstile already exists (that is, there are already waiters),
we'll get the correct turnstile. Otherwise, the lookup function will
simply return the address of a turnstile with no waiters.
The first step is now completed. This means the code has a turnstile; next, the
kernel thread needs to be set to a sleep state and placed on the
sleep queue associated with the turnstile, and a priority inversion
condition needs to be tested for and resolved if it exists. The Solaris 7
turnstile_block() function handles the placement of the thread onto the sleep
queue for the requested lock, does the priority inversion test on
any threads that may already be waiting for the same lock, and, as
in the 2.6 example, relinquishes the processor by entering the
dispatcher's swtch() function.
In turnstile_block(), the pointers are set up based on the return
from turnstile_lookup(). If the turnstile pointer is null, we link
up to the turnstile at which the kernel thread's t_ts pointer is pointing. (When a kernel thread is initialized in Solaris 7, a turnstile is
created and linked to its t_ts pointer). If the pointer returned
from the lookup is not null, then there's already at least one kthread
waiting on the lock; as a result, the code sets the pointer links up
appropriately (see Figure 2). The thread is then put into a sleep
state, as with the previous example, through the scheduling-class-specific sleep routine (ts_sleep()). It is inserted on the
sleep queue associated with the synchronization object using the
sleepq_insert() interface described last month. The waiters field in the turnstile is incremented, and the code does the priority
inversion check (now part of the turnstile_block() routine). The
same rules apply: if the priority of the lock holder is
lower (worse) than the priority of the requesting thread, the
requesting thread's priority is willed to the holder; the
holder's t_epri field is set to the new priority, and the inheritor pointer in the turnstile is linked to the kernel thread. At this
point, the dispatcher is entered via a call to swtch(), and another
kernel thread is yanked off of a dispatch queue and context switched
in.
The wakeup mechanics are initiated as previously described: a
call to the lock exit routine will result in a turnstile_wakeup() if there are threads blocking on the lock. In the Solaris 7 code all the threads blocking on the lock are woken up, as opposed to waking just one of
potentially several threads as was the case in 2.5.1/2.6. Readers familiar with issues around operating systems design have likely seen references to the
thundering herd problem, which is a colorful term used to
describe a situation in which multiple threads are woken up that are
waiting for the same resource; they're all made runable, and on a
multiprocessor system, they all make a grab for the resource at the
same time.
Sun engineering coded the turnstile_wakeup() in Solaris 7 in a
generic enough way so that a single thread wakeup could be
executed, instead of all threads inevitably waking up together. Exhaustive testing under
a variety of different loads has shown that, in practice, we very
rarely end up with a large blocking chain of threads, and thus
almost never run into the thundering herd problem. The wakeup-all
implementation also solves some bit synchronization issues that make
a wakeup-one scenario tricky.
Closing notes
With this month's coverage of turnstiles, we have covered the
sleep/wakeup mechanisms implemented in Solaris for both
synchronization objects and other events that require putting a
kernel thread on a sleep queue. A separate facility, turnstiles, was
created for synchronization objects for the purposes of speed
(performance) and cleaner implementation of priority inheritance.
It is worth noting that, in actual practice, it is not frequently necessary to
place a thread in a sleep state for purposes of blocking on a mutex
lock. Also, there are several inherent
complexities in developing locking and sleep/wakeup strategies
around locks in the kernel that we didn't really get into this
month. For instance, in a multiprocessor system, you need to deal with the fact
that another thread executing on another processor may be attempting to
acquire or has acquired the lock for which you're currently establishing state. There are issues involved with the different interrupt levels, in terms of thread context switching and sleeping. Also,
there's the matter of memory state, ensuring that a set lock is globally visible
to all processors that may reference the memory location of the
lock.
We didn't get into all the particulars of these issues due to complexity and level of detail; we have yet to provide enough background information to make them understandable to those that may not be familiar with the joys of developing a kernel for parallel systems. Suffice it to say, at this point that these issues are, in fact, addressed through some very clever and carefully coded kernel functions and algorithms. Beginning next month, we'll start talking about lower-level kernel support functions and the subtleties of parallel systems, and get into more detail on the implementation of the synchronization primitives.
As a final note, this month's column marks two years of Inside Solaris, which is about 23 months longer than I thought I'd be able to
sustain developing material! I'd once again like to thank everyone
for their continued interest and support.
![]()
Resources
About the author
![]() Jim
Mauro is currently an area technology manager for Sun Microsystems
in the Northeast, focusing on server systems, clusters, and high
availability. He has a total of 18 years of industry experience,
working in educational services (he developed and delivered courses on
Unix internals and administration) and software consulting.
Reach Jim at jim.mauro@sunworld.com.
Jim
Mauro is currently an area technology manager for Sun Microsystems
in the Northeast, focusing on server systems, clusters, and high
availability. He has a total of 18 years of industry experience,
working in educational services (he developed and delivered courses on
Unix internals and administration) and software consulting.
Reach Jim at jim.mauro@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-08-1999/swol-08-insidesolaris.html
Last modified: