Peeling back the process layers, Part 1This month we'll take a look at the Solaris implementation of processes, threads, and lightweight processes |
August 1998 |
We spent a lot of time over the last several months discussing files and file-related topics. This month, we'll get to the other fundamental abstraction on which Unix was built: processes. The Solaris process model has evolved considerably, and Solaris 2.X (SunOS 5.X) added support for multithreaded applications (along with a multithreaded kernel). In addition, a file-like abstraction has been created that provides a simpler programming model for interfacing with processes: the process file system (procfs).This month we'll begin examining the Solaris process model, the threads implementation, the scheduler, signals and session management, and the process file system. (2,100 words)
|
Mail this article to a friend |
max_nprocs = (10 + 16 * maxusers) maxuprc = (max_nprocs - 5)
The max_nprocs value is the maximum number of processes, systemwide. Maxuprc determines the maximum number of processes a non-root user can have occupying a process table slot at any point in time. The system actually uses a data structure to store these values in -- the var structure, which holds generic system configuration information. There are three related values. v_proc is set equal to max_nprocs. v_maxupttl is the maximum number of process slots that can be used by all non-root users on the system, and is set to max_nprocs minus some number of reserved process slots (currently reserved_procs is five). Finally, _maxup is the maximum number of process slots a non-root user can occupy, which is set to the maxuprc value. The astute reader will have observed that v_maxup (an individual non-root user) and v_maxupttl (total of all non-root users on the system) end up getting set to the same value, which is max_nprocs minus five.
You can use adb to examine the values of maxusers, max_nprocs, and maxuprc on a running system:
sunsys> adb -k /dev/ksyms /dev/mem /* invoke adb */ physmem fdde /* and returns this */ maxusers/D /* type this */ maxusers: /* adb returns this and the next line */ maxusers: 253 max_nprocs/D /* type this */ max_nprocs: /* adb returns this and the next line */ max_nprocs: 4058 maxuprc/D /* type this */ maxuprc: /* adb returns this and the next line */ maxuprc: 4053 $q /* type this to quit adb */ sunsys>
You can also use crash(1M) to dump those values, as well as the system var structure:
#/etc/crash > od -d maxusers /* type this. dump in decimal */ f0274dc4: 0000000253 /* crash returns this */ > od -d max_nprocs /* type this */ f027126c: 0000004058 > od -d maxuprc /* type this */ f0270f28: 0000004053 > var /* type this */ v_buf: 100 v_call: 0 v_proc: 4058 v_nglobpris: 110 v_maxsyspri: 99 v_clist: 0 v_maxup: 4053 v_hbuf: 256 v_hmask: 255 v_pbuf: 0 v_sptmap: 0 v_maxpmem: 0 v_autoup: 30 v_bufhwm: 5196 >q /* type "q" to quite crash */ #
Note the /etc/crash var utility does not dump the v_maxupttl value, just v_proc and v_maxup.
Finally, sar(1m) with the -v flag will give you the maximum process table size, along with the current number of processes on the system:
# sar -v 1 SunOS sunsys 5.6 Generic sun4m 07/18/98 23:01:04 proc-sz ov inod-sz ov file-sz ov lock-sz 23:01:05 72/4058 0 2430/17564 0 446/446 0 0/0 #
Under the proc-sz column, the 72/4058 values represent the current number of processes (72), and the maximum number of processes (4058).
The kernel does impose a maximum value in case max_nprocs is set in /etc/system to something beyond what is reasonable, even for a large system. In Solaris 2.4, 2.5, 2.5.1, and 2.6, the maximum is 30,000, which is determined by the MAXPID in the param.h header file (available in /usr/include/sys). In Solaris 2.7 (not yet released) this is cranked up to 999,999.
In the kernel fork code, a check is made on the current number of processes against the v_proc parameter. If the limit is hit, the system produces an "out of processes" message on the console, and increments the proc table overflow counter maintained in the cpu_sysinfo structure. This value is reflected in the "ov" column to the right of proc-sz in the sar(1M) output. For non-root users, a check is made against the v_maxup parameter, and an "out of per-user processes for uid (UID)" message is logged. In both cases, the calling program would get a "-1" return value from fork(2), indicating an error.
|
|
|
|
|
Processes, treads, and lightweight processes (LWPs)
Solaris supports multithreaded processes -- that is, a process can
have multiple threads of execution that share the context of the
process and can be scheduled independently. Things like the address
space, open files, etc., are shared by all the threads within a
process. Threading offers several advantages. The most salient
advantage is that it provides applications a means of getting
high degrees of parallelism on multiprocessor systems (e.g. Sun SMP
desktops and servers) without having to use the traditional
fork/exec multiprocess execution model. Prior to threading, if an
application wished to achieve concurrency in execution (getting more
than one thing done at once), it spawned additional processes. If
there was any sharing of information required between the processes,
various forms of interprocess communication (IPC) needed to be
employed, such as shared memory segments or message queues. (See Resources
section below for a link to the September 1997, October 1997, and November 1997 Inside Solaris columns that discuss IPC facilities.)
This all worked well enough -- but information, file and/or data sharing typically involve a fair amount of code, and processes have an associated "weight" that can keep the kernel pretty busy. You may have heard processes sometimes referred to as "heavyweight" processes, while threads are typically referred to as "lightweight". "Weight" refers to the amount of kernel resources involved in maintaining, scheduling, and executing processes. Simply put, the system can create, manage, and schedule threads within a process with much less overhead and fewer kernel resources consumed than an equivalent number of processes. To illustrate the point, I have two test programs: ftime (fork time) and ttime (thread time). The ftime test does 100 forks in a loop, timing each one, and outputs the average time for a fork to complete. The ttime test does the same loop, only it executes thread creates instead of forks. Below is the execution and output of each test program on a two-processor Ultra 2 desktop, 167-MHz processors, running Solaris 2.6.
fawlty> ftime Completed 100 forks Avg Fork Time: 1.137 milliseconds fawlty> ttime Completed 100 Thread Creates Avg Thread Time: 0.017 milliseconds
As you can see, the average fork took 1.137 milliseconds, while the average thread create took .017 milliseconds (17 microseconds). In this example, thread creates were about 67 times faster. Note that these numbers and results do not reflect an official, audited Sun benchmark, and do not imply any guarantees of performance by Sun. Also, my test case for threads did not include flags in the thread create call to tell the kernel to create a new LWP with the thread and bind the thread to the LWP. This would have added additional weight to the call, bringing it closer to the fork time. Even if LWP creation closes the gap in creation times between processes (forks) and threads, user threads still offer advantages in resource utilization and scheduling -- as we will see shortly.
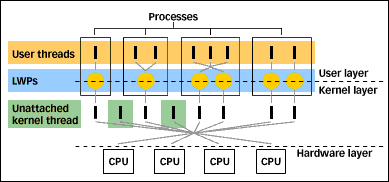
Since I've introduced some potentially unfamiliar terms in the above section and made reference to things like "bound threads", it's time to take a look at the big picture. Figure 1 below shows the process/thread/lwp model in Solaris.
How Solaris handles threads: the kthread model |
Figure 1 shows several processes, each with a different number of user threads, LWPs, and kernel threads. We already introduced the concept of user threads. These are threads that get created explicitly by the programmer using either the Solaris or POSIX threads library. There's no hard limit on the number of user threads a process can create and use. The boundary condition that tends to limit threads is available process address space. Every user thread shares a process address space -- the memory pages mapped to the process for the text, data, and stack. Each user thread requires its own stack space, the size of which is one megabyte by default. The programmer can specify a different stack size as an argument to the thr_create(3T) call to minimize the address space requirement of a lot of threads in a process.
Lightweight processes and kernel threads are shown in the diagram as separate physical entities. This is consistent with the traditional Solaris threads architecture description that's been around since the early days of Solaris 2.X, and is supported by some of the early documentation I've read (for example, Solaris white papers) that distinguish between LWPs and kernel threads. Actually, the distinction is much more subtle. The diagram is intended to drive home an architectural feature of the Solaris threads implementation. The goal of the implementation is to maximize the efficiency of user threads by not imposing any significant amount of burden on the kernel for the management and scheduling of user threads, while at the same time providing processes the ability to have multiple threads of execution running concurrently on multiple processors.
In order to achieve those goals, there needs to be a layer between the user threads in a process and the entity that the Solaris kernel schedules to run on a processor. That is why the multi-layer model exists. The kernel is blissfully unaware of user threads. The threads library deals with user thread priorities and scheduling user threads. In order for a user thread to execute on a processor, it must get mapped to an underlying LWP or kernel thread. Kernel threads and LWPs are essentially the same thing. When the Solaris design work was done, there was a bit of shuffling around of certain bits of data that were traditionally stored in the process and user structures (aka the "uarea"). Figure 2 shows the current model, and the relationship between the process structure, LWP, and kernel thread.
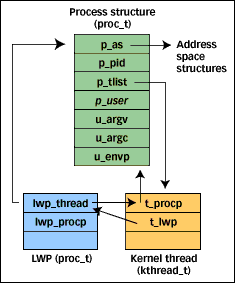
Process, LWP, and kernel thread structure relationships |
Figure 2 does not include all the structure members for the proc, LWP, and kernel thread structures. The goal is to illustrate the linkage between the components we've discussed thus far. The LWP, defined as a klwp_t data type in /usr/include/sys/klwp.h, provides a separate storage area for data that can be paged out. The kernel thread, defined as a kthread_t data type in /usr/include/sys/thread.h, is not pageable, nor is the process structure. Note that the user area is now embedded in the proc structure, and not maintained as a separate entity anymore.
User threads management is done by the threads library (more on this later). Once a user thread has been bound to a kernel thread, it's up to the Solaris kernel to schedule the kernel thread. This makes for an interesting departure from the conventional Unix scheduling implementation. In Solaris, kernel threads are the entity that gets put on a dispatch queue and scheduled. A non-threaded process will have one kernel thread (proc 1 in the diagram); a multithreaded process may have several. The ratio of kernel threads to user threads is driven by a couple of things. First, the programmer can tell the system to create an LWP (kernel thread) and bind to it in the thread create call. Theoretically, a process can have every user thread bound to a corresponding kernel thread (proc 4 in Figure 1). Also, the thr_setconcurrency(3T) routine exists so that an application programmer using threads can tell the system how many active threads can be run. This will nudge the kernel and get more kernel threads created for use by application threads. Finally, a signaling mechanism is in place such that if a process has runnable threads but no available kernel thread, additional kernel threads will get created. This is something of an oversimplification -- we'll get into more specifics in this area in next month's column.
This is a good place to break. We'll peel back more layers next month.
A couple of notes to readers. First, August marks the one-year
anniversary of Inside Solaris. I'd like to thank readers for
their interest, support, and kind words over the past year. I make
it a point to return every e-mail I get, although I do get pretty far
behind from time to time. I appreciate your patience in waiting for
replies -- unfortunately, I do still have a day job that keeps me
pretty busy!
![]()
Source code
/*
* Time 100 forks
* To compile: cc -o ftime ftime.c
*/
#include <sys/types.h>
#include <sys/proc.h>
#include <sys/time.h>
#include <sys/wait.h>
#include <thread.h>
#include <unistd.h>
#include <stdio.h>
#define NANO2MILLI(x) (x/1000000)
hrtime_t st, et, tt, accum;
main()
{
int i,ret,stat,loop_cnt=100;
float avg;
accum=0; st=0; et=0; tt=0;
for (i=0; i < loop_cnt; i++) {
st=gethrtime();
ret=fork();
et=gethrtime();
if (ret > 0) {
waitpid(ret, &stat, 0);
if (!WIFEXITED(stat)) {
printf("child not exited normally \n");
printf("%d, pid %d, stat = %d",
i, ret, stat);
exit(1);
}
tt=et-st;
accum=tt+accum;
continue;
} else if (ret == 0)
exit(0);
else {
fprintf(stderr,"fork(0 # %d failed !\n", i);
exit(1);
}
}
printf("Completed %d forks\n",i);
avg=(float)accum / (float)loop_cnt;
printf("Avg Fork Time: %.3f milliseconds\n",NANO2MILLI(avg));
}
/*
* Time 100 thread creates.
* To Compile: cc -o ttime ttime.c -lthread
*/
#define _REENTRANT
#include <sys/types.h>
#include <sys/proc.h>
#include <sys/time.h>
#include <thread.h>
#include <unistd.h>
#include <stdio.h>
#define NANO2MILLI(x) (x/1000000)
hrtime_t st, et, tt, accum;
void* tfunc(void *);
main()
{
int i,ret, loop_cnt=100;
int flags=0;
float avg, tmilli=0.0;
thread_t tid;
st=0; et=0; tt=0; accum=0;
for (i=0; i < loop_cnt; i++) {
st=gethrtime();
ret=thr_create(NULL,NULL,tfunc,(void *)NULL,flags,&tid);
et=gethrtime();
if (ret != 0) {
printf("thr_create failed on %d\n",i);
perror("thr_create");
exit(1);
} else
thr_join(NULL,NULL,NULL);
tt=et-st;
accum=(float)tt+accum;
}
printf("Completed %d Thread Creates\n",i);
avg=(float)accum/(float)loop_cnt;
printf("Avg Thread Time: %.3f milliseconds\n",NANO2MILLI(avg));
}
void* tfunc(void *f)
{
thr_exit(0);
}
Resources
About the author
Jim Mauro is currently an area technology manager for Sun
Microsystems in the Northeast area, focusing on server systems,
clusters, and high availability. He has a total of 18 years of industry
experience, working in service, educational services (he developed
and delivered courses on Unix internals and administration), and
software consulting.
Reach Jim at jim.mauro@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-08-1998/swol-08-insidesolaris.html
Last modified: