Learn how to configure your disk subsystems for improved reliability and price/performance
This excerpt from Configuration and Capacity Planning for Solaris Servers gives straightforward advice for maximizing storage capabilities
July 1997
|
|
Learn how to configure your disk subsystems for improved reliability and price/performanceThis excerpt from Configuration and Capacity Planning for Solaris Servers gives straightforward advice for maximizing storage capabilities
|
July 1997 |
This article has been adapted from Configuration and Capacity Planning for Solaris Servers by Brian L. Wong, Sun Microsystems Press, a Prentice Hall title, Mountain View, CA. © Copyright 1997 Sun Microsystems Inc. This particular selection applies the architectural facets of disk subsystems and their components to the three basic real-world criteria for configuring disk subsystems: performance, reliability, and cost. When in doubt as to the relative importance of performance or reliability, configure for reliability. The performance of a system that fails is zero. (4,000 words)
|
Mail this article to a friend |
Many users configure systems on the basis of price, and others configure for highest performance. Unfortunately, far too many ignore configuration for reliability. Storage subsystems on Solaris-based systems have grown so fast in the past year or two that the reliability of storage has rapidly become a major unrecognized issue. Disk drives have become almost an order of magnitude more reliable in the past decade, but even this fantastic improvement has been dwarfed by the almost unbelievable improvement in density and price/performance.
In 1988, a typical Sun-4/280 had about six disk drives, each with an MTBF of approximately 75,000 hours; the resulting reliability was about 12,500 hours -- about 17 months. One failure every year and a half is reasonably easy to manage. In 1992 the typical SPARCserver 690 was configured with about 16 disks, with individual MTBF of about 175,000 hours. The cumulative disk MTBF was about 11,000 hours (15 months). In 1996, a typical SPARCcenter 2000E has more than 250 disk drives with a greatly improved MTBF for individual disks of about 500,000 hours. The reliability of the pool of disks is about 2000 hours -- less than three months. Large configurations are becoming increasingly affordable, and systems with a thousand or more drives are becoming commonplace. With 1,000 drives configured, anticipate an average failure rate of one drive every three weeks!
These realities strongly suggest that mission-critical systems
must configure protected storage. The type and extent of
the protection varies with the application and criticality of the
data and operation. Disks should not be automatically
mirrored -- at double the storage cost, or more -- but some
storage on virtually every system should be mirrored, or at least
protected. Any storage that is crucial to the system's continued
operation must be protected. Normally this means the root and
/usr partitions, as well as swap space and the
application binaries. When DBMS systems are involved, the logs and
rollback segments usually must be protected, and the log devices of
mission-critical UFSUFS+ file systems should also be mirrored. (UFS+
log devices are usually so small that protecting them with RAID-5
turns out to cost more than simply mirroring the relatively small
data and being done with it. Moreover, they are virtually
write-only, a bad fit for a RAID-5 volume.)
|
|
|
|
|
Hot sparing
Disk functions that are worth protecting should be further protected
by some number of hot spares. A multitude of hot spares is not
necessary -- just a few should suffice. There only need be
sufficient hot spares to cover the reasonably anticipated
simultaneous failures. For example, if a 5-data+1-parity RAID-5
volume is configured, only one hot spare is required, since multiple
simultaneous failures will destroy volume integrity anyway. Hot
spares need not be dedicated to single volumes, either. One global
hot spare drive can serve many volumes, and a small pool of several
drives can be allocated to back a large number of volumes. This
method applies when hot pluggable disk subsystems are used, because
the hot spare only needs to serve until a physical replacement can
be installed, rather than until the next system shutdown.
Other reliability considerations
Configuring storage for maximum reliability typically means
eliminating single points of failure, while minimizing the
overall number of components. For example, given roughly
equivalent MTBF, one 4.3 GB disk is considerably less likely to fail
than two 2.1 GB disks. On the other hand, the notion that fewer
disks are more reliable is not universally true. In
general, 3.5" disks are much more reliable than contemporary 5.25"
drives, and older disks are nearly always less reliable than newer
models. For example, the Seagate 3.5" ST15150W 4.3 GB disk is rated
at over 500K hours MTBF, whereas the 5.25" Seagate ST41080N 9 GB
drive delivers only about 200K hours MTBF. In this case, two of the
smaller disks are more reliable than one of the larger
disks, as well as delivering higher performance. Note that
reliability engineers are in the same position as configuration
planners: they are predicting the future. Often the achieved MTBF of
a disk is very different from the rated MTBF (in some instances
field MTBF has achieved only 30 percent of original manufacturer's
rating). Check with your vendor for field MTBF data. Another vendor
selling "the same disk" may or may not have the same product --
packaging can significantly affect disk reliability, for
example, by having different electrical, shock, vibration, or
thermal characteristics. Firmware characteristics can also vary
widely among suppliers of seemingly the same part.
Packaging
Minimizing the number of components can mean more than just
minimizing the number of disk drives. In particular, look for simple
and streamlined packaging. Many disk arrays use an elaborate carrier
for each disk drive whose purpose is to interface a commodity disk
without hot plug connectors into a fully hot-pluggable subsystem.
This solution seems elegant and likely to improve system
reliability, but careful analysis often reveals otherwise. Literally
every component can fail, and most such carriers have a number of
wires and connectors in them. Although the failure of the physical
carrier is unlikely to have an operational impact, the failure of
either a cable or connector is likely to result in an operational
disruption.
Multiplying disk enclosures is another common configuration that results in sub-optimal reliability, although it is not as problematic as it once was. A configuration that uses four desktop disk packages is far less reliable than a "just a bunch of disks" enclosure with an equivalent number of disks. Consider a system configured with four desktop quad-disk boxes, compared with the same 16 disks in a typical disk array. The disk array will have just one power cord, one SCSI or FibreChannel cable, and probably is self-terminating, whereas the desktop disk enclosures have four SCSI cables, four terminators, and four power cables.
Environmental considerations
One final comment on disk reliability is that disks, more than most
other computer system components, are sensitive to environmental
factors. The MTBF figures quoted by most vendors are for ideal
operating conditions -- typically in an environment in which
temperature and humidity are controlled in the center of the
specified operating ranges. When operated at the limits of the
approve operating range, reliability falls off substantially. A disk
that is rated for operation between 10° and 40°C is about
half as reliable at 40°C than at 25°C.
Most large configurations (the ones most at risk from disk reliability concerns) are located in environmentally-controlled data centers, but this generalization is far from universally true, and environmental considerations should be kept in mind when building configurations of this magnitude. Small-scale systems are affected too, but the arithmetic is much more reasonable. For example, an Ultra-1 server with a 30-disk array expects a disk failure about every two years at 25° and about once a year at 35°-40°C. However, the 1,000 drive example above likely will suffer a failure every ten days at 40°C.
Disks in the real world -- configuring for performance
Maximizing disk performance amounts to reducing contention for
physical resources, and, to some degree, enabling multiple resources
to work together on a single problem. The basic strategies are
easily derived from the strengths and weaknesses of the various disk
organizations.
Reducing disk utilization
Industry consensus indicates that, for high-performance systems,
disk drives should be busy no more than about 60 percent of the
time. Disks that are busier than this level should have their access
load spread across two or more drives. Device utilization governs
how long an individual request is pending against the
device. Although the device is usually able to sustain its maximum
overall throughput rate, individual requests may spend considerably
longer time in the service queues, resulting in slower perceived
performance for the end user. Figure 70 illustrates
this point*.
This principle applies equally to other resources in the system,
particularly busses such as SCSI, MBus, and Gigaplane. Fortunately,
most busses have sufficient bandwidth that utilization stays
relatively low, even during high activity periods. Disks, have very
limited capabilities and are often driven at very high utilization.
Caution: The impact of excessive resource utilization cannot be overestimated. Many systems have a single disk drive that is operated at 99-100 percent utilization. In such cases, the length of the request queue for the disk is also very long -- sometimes as many as 80-250 requests may be pending against the drive. Given that most modern disks can service about 100 disk operations per second, a queue length of 80-250 means that requests at the end of queue will experience delays of 800-2,500 milliseconds. I/O requests issued against the disk thus suffer delays well in excess of a second, the equivalent of nearly 400 million CPU instructions!
Even at the 60 percent utilization level the disk can still be a bottleneck. Utilization and the associated latency can be reduced significantly by providing additional disk resources. The time taken to service a specific user I/O request consists of two parts: the time spent waiting for the device to service previously pending requests, and the time spent waiting for the device to service the request. Of these, the device service time is by far the greatest component, since the device is mechanical. Intuitively, a less busy device is able to respond to a given request more quickly. Accordingly, major reductions in utilization usually correspond to improvements in overall perception of performance.
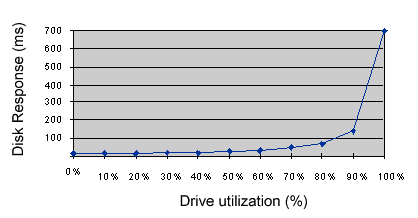
Disk response time as utilization increases. The response time governs the performance of the system as perceived by the user. |
By far the most effective way to reduce drive utilization is to
spread the access load across as many disks as are economically
feasible. This solution can sometimes be accomplished through the
simple expedient of logically dividing the data and locating it on
multiple disks, for example, by putting one half of the users on one
disk and the other half on another disk. Unfortunately, this
approach usually falls short of the desired results, because disk
access is frequently not coordinated with data volume. In this
example, two users out of an entire community may generate 80
percent of the I/O load, and if they happen to land on the same
disk, they will cause a severe usage imbalance. The situation is
even less clear when the data is of varying usage; for example, the
home directories account for more than 90 percent of the disk space
on a typical server, yet nearly 50 percent of all disk accesses are
made to the root file system, because /var/mail resides
there.
Because the division of disk accesses is usually far from clear, especially within a specific set of data, disk striping (RAID-0, RAID-3, or RAID-5) provides the easiest, most reliable mechanism to spread data access across multiple disks. A RAID metadisk can be used "as is" in place of a raw disk partition, or with a file system built on top. This flexibility permits metadisks to function for either databases or file systems as appropriate. As with most other facets of disk configuration, the metadisk configuration depends upon the dominant access pattern.
Data layout -- minimizing seek time
The magnitude of each of the components of disk access time can be
used to optimize the performance of disk I/O subsystems.
Fundamentally the idea is to eliminate as many seeks as possible and
to minimize the remaining ones. Careful location of data on the
physical disks can substantially reduce the amount of time spent
waiting for mechanical I/O operations.
The Berkeley Fat Fast File System format used by Solaris divides the disk space occupied by a file system into contiguous segments called cylinder groups. The system goes to considerable effort to keep files entirely within a cylinder group; this minimizes seek distance and seek time. This service is provided transparently by the file system code. Applications that use raw disks must perform similar optimizations, and the most notable consumers of raw disks -- database management systems -- provide some sort of similar optimization.
Even given these optimizations, administrators can do a considerable amount to minimize seek times. The more data a cylinder can hold, the less often that a seek will be required. The geometry of physical disks is of course fixed, but striping can be used to enlarge the effective size of the cylinder. The effect is to make logical cylinders the sum of the size of the cylinders making up the stripe. Because a given quantity of data now fits in fewer cylinders, the disks must perform fewer physical seeks to access the data.
Reducing seek times is possible even on a single disk. Nearly all disks shipped today use Zone Bit Recording. Because the outside cylinders are physically larger than the inside cylinders, using the these cylinders where possible results in fewer seeks. As with the larger logical cylinders created by striping, the use of a larger cylinder size results in fewer seeks; moreover, the seeks that are still required are shorter.
The fact that long seeks take much longer than short ones leads to a further recommendation: where possible, configure disks with just a single primary purpose. In particular, avoid frequent access to two different partitions of a disk. Database systems are frequently configured with a disk that contains a partition for data tables and a separate partition for logs. The logs are "fitted" onto the end of a disk because they consume relatively little space. However, if configured onto the end of a disk that contains a frequently used table or index, the performance penalty could be significant. It is best to configure frequently used functions onto independent disk arms. If necessary to consolidate multiple functions onto a single disk, configure one "hot" function per drive.
If the number of specialized purposes requires assignment of several
functions to a single disk, put the most frequently accessed slices
in adjacent slices. The boot disk warrants special attention. For
historical reasons, most system disks are configured with at least
four partitions (slices): root, swap, /usr, and
/export. This organization is far from optimal, since
swap will probably be the most frequently accessed slice, and
/export is nearly always referenced more than
/usr. If a seek outside of the current partition is
required, it probably will cross most of the disk, either from swap
to /export or vice versa. Configuring the slices in the
order root, swap, /export, /usr reduces
the length of seeks for absolutely no cost!
The exception to this rule is the configuration of additional swap
space. Most systems use dedicated swap partitions for backing store
for anonymous virtual memory. However, if a disk must be used for
both swap and a heavily used file system, combining these functions
in a single partition is possible. The mkfile(8)
command can be used to create a swap file, and the
swap(8) command is then used to make it active.
Creating the swap file in a heavily used file system helps
reduce disk seek length. The degradation associated with swapping
onto a file system rather than a raw partition is less than one
percent and can be safely ignored.
Using RAID to optimize -- random access
Optimizing disk utilization in the random access case is relatively
simple. A stripe of the available disks normally minimizes the
utilization. The choice of chunk size is dependent upon the type of
usage. If a file system is to be built on the metadisk, choose a
chunk optimized for the 56 KB file system blocks. If the metadisk is
to be used as a raw disk for a DBMS tablespace, the default chunk (a
disk cylinder) is the most appropriate, since most DBMS systems
normally operate with data blocks less than or equal to the size of
the minimum chunk. The choice of a large chunk imposes the minimum
overhead for splitting I/O transactions yet evenly distributes the
data across the drives so that all drives are utilized.
Surprisingly, disk mirroring can also improve disk access performance in some cases. The geometric read mirroring option improves serial reads by using alternate submirrors to supply data -- in effect the same as a disk stripe. The other alternative, round-robin, usually improves random reads by permitting load balancing across the submirrors. Writes to a mirror, of course, are not faster than writes to a non-mirror.
Using RAID to optimize -- sequential access
For access that is sequential, the choice of chunk size is
important. A stripe of at least four disks on two host adapters with
a small chunk size normally yields the highest sequential
throughput. If more than four disks are available, the optimal
configuration uses four-way stripes and concatenates them together.
The small chunk size is used to spread individual accesses across as
many drives as possible as often as possible. For very small
requests such as the typical 2 KB raw DBMS I/O, breaking up the I/Os
into small enough chunks is impossible. Nonetheless, striping
normally does improve throughput as it lowers disk utilization,
especially in multi-user or multitasking environments. Multithreaded
DBMS servers with as few as one active process also benefit from
this organization, since most of these DBMS implementations use
asynchronous I/O completion notification to generate many
simultaneously pending I/O requests. A four-way stripe normally
delivers about three times faster serial throughput than a single
disk, and a two-way stripe normally delivers about 85 percent more
serial throughput than a single disk.
Note that unlike hardware striping, the use of software striping
does not lock all of the disk arms in the stripe set
together. Only the drives that are required to complete an I/O are
activated. For example, consider a system that has a four-way stripe
with 64 KB chunks. If this system receives a request for
128 KB of data, only two of the four disks will be used; the
others will be free to respond to other requests. Even if the
request is not aligned on a 64 KB boundary, only three disks will
be activated.
Performance in perspective
After a long discussion about performance, note that users are often
more concerned with performance than is warranted. The most common
system performance problem is a misconfigured disk
subsystem, much sleep is lost needlessly over disk subsystem
configuration. The disk subsystem may or may not be the limiting
factor in a configuration -- and often it is not. For example, many
(perhaps most) users are concerned with obtaining as much
host-to-disk I/O bandwidth as possible, not recognizing that the
typical application does many very small I/Os, rather than moving
enormous amounts of data.
At first glance configuring 30-50 disk drives on a single 20 MB/sec SCSI bus seems ridiculous, since a disk is capable of delivering 5+ MB/sec. More in-depth analysis suggests that for the 2 KB random I/O that is normally found in most database applications, 50 disk drives can deliver only about 12 MB/sec, rather than the expected 250 MB/sec. This overall throughput is low even in the extremely unlikely circumstance that all of the disks are running at full utilization. Experience shows that 50 disks running at full utilization is often enough to support as many as 300-500 users, if the application is similar to an Online Transaction Processing (OLTP) workload.
Likewise, the choice between RAID-1 and RAID-5 is often agonizing, since write performance is so drastically different. Yet for most applications that do moderate amounts of I/O, the difference may be small indeed. The TPC-C is reasonably representative of a large class of database applications. When the storage subsystem is configured for RAID-1+0 instead of simple RAID-0, the overall performance decreases by 8-10 percent, rather than the 15-30 percent that one might expect from looking at mirroring performance in isolation. Configuring the same database on RAID-5 storage results in an overall degradation of only 15-20 percent compared to RAID-0. This is particularly surprising given the extreme differential between RAID-0 and RAID-5 write performance (sometimes a factor of four**) TPC-C does relatively little I/O, accounting for the higher than expected overall performance.
Of course, for applications that are dominated by I/O activity, such as decision support, online analytical processing (OLAP) and data-intensive NFS, overall performance may be governed directly by I/O performance. For example, configuring a data-intensive NFS server with host-based RAID-5 storage is unlikely to result in acceptable performance -- especially if the clients use the NFS V2 protocol, resulting in much smaller I/O sizes to the disk, the particular weakness of the RAID-5 storage organization.
Balancing performance, reliability, and cost
Many different concerns arise when configuring storage subsystems.
Performance and cost are hard to avoid, and reliability is always a
concern. Balancing these considerations can be difficult, especially
in a uniform configuration. For example, a storage system is
typically optimized for performance using many small disks, but such
a configuration normally costs significantly more than equivalent
storage built from much denser disk spindles. Overall subsystem
reliability may lie with either, depending on specific components.
Fortunately, configuring subsystems with many different types of
components is nearly always both possible and constructive.
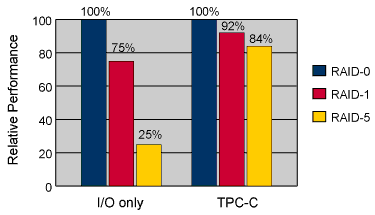
Real-world RAID performance comparison. Despite significant differences in the I/O-only benchmark, an application shows a much less dramatic differential due to varying RAID organizations. |
The basic principle for overall configuration is to divide the storage into segments, based upon their performance and reliability concerns. Whether reliable storage should use RAID-1 mirroring or RAID-5 is often difficult. However, dividing the overall data into groups with differing requirements usually results in a configuration that involves both RAID-1 and RAID-5. Deciding between small, fast disks and large, inexpensive ones often results in a system that stores current data on the fast disks but archives most older data on the less expensive storage, possibly protected by RAID-5 instead of the much more expensive mirroring. For example, root and swap should probably always be mirrored (an I/O error in the swap area can cause a system panic). Large historical data sets such as the transaction history for 1986 are unlikely to be updated very often, so they are excellent candidates for storage on large, dense disks and protected by RAID-5. At the same time, current transactions are probably updated frequently. The current transactions, the transaction logs, and the rollback segments are mission-critical data. Mirroring is much more appropriate, as is configuration on many small, fast disks.
|
|
* Chen, P. An Evaluation of Redundant Arrays of Inexpensive Disks Using an Amdahl 5890. M.S. Thesis, University of California at Berkeley, Computer Sciences Division, 1989, p. 562.
** In this case, the database log was configured as a mirror, rather than a RAID-5 device, since the small size of the device precluded any savings in the disk space. Since this part is the write-bound part of the workload, configuring it with RAID-5 would not have resulted in as good performance.
![]() Title: Configuration and Capacity Planning for Solaris Servers
Title: Configuration and Capacity Planning for Solaris Servers
Author: Brian L. Wong
Publisher: Sun Microsystems Press/Prentice Hall
ISBN: 0133499529
List price: $40.67
Resources
About the author
Brian L. Wong is Chief Scientist for the Enterprise Engineering group
at Sun Microsystems. He has been a data processing consultant and software
architect and has held other positions at Sun.
Reach Brian at brian.wong@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-07-1997/swol-07-diskconfig.html
Last modified: