Priorities revisitedJim addresses a consistent thread of questions that have come in over the last several months: kernel thread priorities and how they're altered by user-level interfaces |
June 1999 |
Jim's recent string of columns on processes, threads, and the kernel dispatcher have raised some interesting questions from our astute readers. Of the batch, the most common reader questions deal with thread priorities (how they're established, altered, etc.). Because this topic is quite complex, Jim devotes this month's column to a thorough discussion of kernel thread scheduling classes and priority implementation. (5,000 words)
|
Mail this article to a friend |
Scheduling classes: A brief review
As we discussed back in the October 1998 column, the Solaris kernel implements multiple scheduling classes, where each class has a defined range of priorities. Table 1, below, offers a breakdown of scheduling classes, including each class's range of priorities and a brief description.
| Class | Priorities | Description |
| Timeshare (TS) | 0-59 | The TS class handles general timesharing behavior, where the dispatcher attempts to give each kernel thread a fairly even allocation of processor time. Threads that wait have their priorities boosted to a high value; threads that consume their alloted time quantum have their priorities lowered. TS is the default class for user-level threads. |
| Interactive (IA) | 0-59 | The IA class is an extension to the TS class. IA class threads provide snappier performance for end users using X-based windowing on a Solaris desktop by giving threads running in the window with current input focus a boosted priority. The IA class has the same priority ranges as TS and uses the same dispatch table and much of the same kernel code. |
| System (SYS) | 60-99 | SYS class threads are reserved for use by operating system kernel threads. As a fixed-priority class, a SYS class thread runs until it voluntarily surrenders the processor; it is preempted only if a higher priority (RT or INT) thread comes in. TS and IA class threads may be placed at a SYS priority for specific conditions, such as acquiring a reader lock. |
| Realtime (RT) | 100-159 | RT class threads provide support for applications that require a minimal dispatch latency. RT class threads are the highest priority threads on a Solaris system, with the exception of interrupt threads, and they implement a fixed-priority scheme. |
| Interrupt (INT) | 160-169 | The highest priority threads on the system are INT threads. INT threads are executed as a result of the Solaris kernel taking an interrupt (a device interrupt from an I/O controller, for example). An INT thread is typically a very short (quick) bit of kernel code that does some preliminary interrupt handling. Any lengthy work is passed off to a kernel thread so the system can return from the interrupt as quickly as possible, allowing lower priority work to continue. INT priorities may land at values 100 to 109 if the realtime class is not loaded into the kernel. |
Figure 1, below, illustrates the scheduling class priorities. For more detail on the scheduling classes, please refer to the October 1998 column.
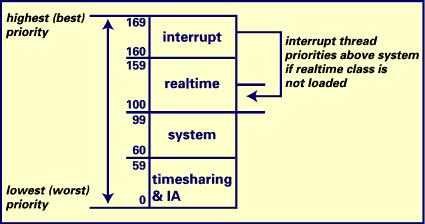
Figure 1. Scheduling classes |
The different scheduling classes may implement a dispatch table for defining time quantums at a given priority level. The TS/IA dispatch table actually contains several columns of values used for establishing thread priorities under several conditions (e.g., after sleep). The RT table is much simpler, since RT thread priorities are fixed. There is no dispatch table for SYS or interrupt class threads. The SYS class uses an array that defines its range of priorities. No time slicing is performed on SYS class threads; they simply get a priority and run until they're done. Interrupt threads get their priority level based on the level of the interrupt itself (SPARC Solaris systems provide for 15 interrupt levels; interrupt levels 1 to 10 run at interrupt-thread-priority levels 1 to 10). Please refer to the October 1998 and December 1998 Inside Solaris columns for a detailed description of the dispatcher tables.
You can use dispadmin(1M) to examine a dispatch table:
sunsys> dispadmin -g -c TS
# Timesharing dispatcher configuration
RES=1000
# ts_quantum ts_tqexp ts_slpret ts_maxwait ts_lwait PRIORITY LEVEL
200 0 50 0 50 # 0
200 0 50 0 50 # 1
...
If you look back to Figure 1, you can see that there are two ways to view priorities: the global priority, which is a unique priority across all loaded scheduling classes, and a per-class range of priorities (TS/IA priorities range from 0 to 59, SYS priorities range from 0 to 39, etc.). Because TS and IA are the lowest priority threads on a system, there's a direct correlation between the per-class priority and the global priority. SYS class priority 0 corresponds to global priority 60. If the RT class is loaded, RT priority 0 corresponds to global priority 100. In the next section, we'll discuss some other priority views, and then bring it all together. In Solaris, the higher the number, the higher the priority (as is the case in generic Unix SVR4). The traditional Unix scheduler was the inverse; lower priority values indicated higher priorities.
Remember, kernel threads, not processes, are given a priority and
assigned to a scheduling class, which is inherited from the parent when the thread is created. The class and priority can be changed either programatically via the priocntl(2) system call or from the command line using priocntl(1). Note that the system call allows for changing the scheduling class of threads within a process -- different kernel threads within the same process can be in different scheduling classes.
The priocntl(1) command works only at the process level, and thus, affects all the kernel threads in a process.
|
|
|
|
|
Get your priorities straight
Let's start with a look at the various fields in the kernel thread and scheduling class datastructures that maintain priority information.
| Field name | Structure | Description |
| t_pri | kthread | The thread's actual priority |
| t_epri | kthread | The thread's inherited priority |
| t_kpri_req | kthread | A flag to indicate a kernel (higher) |
| ts_cpupri | tsproc | Kernel controlled part of ts_umdpri |
| ts_uprilim | tsproc | User priority limit |
| ts_upri | tsproc | User priority |
| ts_umdpri | tsproc | User priority within TS class |
| ts_nice | tsproc | Nice value |
| ts_boost | tsproc | IA class priority boost value |
| rt_pri | rtproc | Priority within the RT class |
Recall from October that there is a class-specific datastructure
linked to the kthread, which maintains additional data required for
scheduling and priority management. The tsproc and
rtproc structures from the table above are the TS and RT class-specific structures, respectively. IA class threads use a TS structure.
SYS and interrupt threads do not require a class-specific structure.
The structure is linked to via the kernel thread's t_cldata pointer in
the kernel thread. The fields in tsproc and rtproc are initialized when
the thread is created (at fork(2) time or thread_create()) with values
from the parent.
The t_pri field in the kernel thread is the actual priority
value used by the dispatcher code to determine which queue the thread
will be placed on. Remember, Solaris implements a queue of queues,
in which each CPU has a set of queues, one queue for every priority below
RT (unbound RT priority threads are placed on a systemwide kernel preempt queue;
if processor sets are used, each processor set has
its own kernel preempt queue). Every thread at a given priority is
placed on a linked list in a processor's queue. The priority field
displayed in the PRI column of the ps -c command is obtained from the
kernel thread's t_pri field, as shown here:
PID LWP CLS PRI TTY LTIME CMD
0 1 SYS 96 ? 0:01 sched
1 1 TS 58 ? 0:02 init
2 1 SYS 98 ? 0:00 pageout
3 1 SYS 60 ? 54:28 fsflush
235 1 TS 58 ? 0:02 sendmail
184 2 TS 58 ? 0:00 syslogd
184 3 TS 58 ? 0:00 syslogd
184 4 TS 58 ? 0:00 syslogd
180 4 TS 58 ? 0:00 automoun
180 6 TS 58 ? 0:00 automoun
163 1 TS 58 ? 0:00 statd
214 1 TS 58 ? 0:00 lpsched
325 1 IA 59 ? 0:00 dtlogin
204 1 TS 58 ? 0:00 nscd
204 4 TS 58 ? 0:01 nscd
394 1 IA 59 ? 0:00 dsdm
418 1 IA 59 ? 0:37 dtwm
Most of the remaining fields in the tsproc struct exist to support the
notion of user priorities, as well as the nice(1) command.
Support for user priorities exists for TS/IA threads, where a user has
some level of control over the priority of a thread. The user priority
is a component of what ultimately becomes the thread's actual priority --
setting the user priority to a specific value for a thread does not
result in the thread's priority being set to that precise value.
Rather, the kernel uses it as a hint to move the priority in particular
direction. It's really a "modern" implementation of the traditional
nice(1) functionality. The user priority fields are manipulated via
priocntl(1), which should be thought of as the equivalent of nice(1)
for the Solaris dispatcher.
The priocntl(1) command can list priority limits and ranges for all
loaded scheduling classes, as shown here:
sunsys> priocntl -l
CONFIGURED CLASSES
==================
SYS (System Class)
TS (Time Sharing)
Configured TS User Priority Range: -60 through 60
IA (Interactive)
Configured IA User Priority Range: -60 through 60
RT (Real Time)
Maximum Configured RT Priority: 59
sunsys>
The lack of output for the SYS class is the kernel's way of telling us
that the priority of a SYS class thread is not user changeable or
configurable. Using the priocntl(1) command, a user can raise or lower
the user priority of a process, or a group of processes. As I
mentioned earlier, priocntl(1) does not provide thread-level
granularity, although the kernel supports thread-level priority
modifications, and you could write a program using priocntl(2), which
alters thread priorities within a process. Look for examples of this further down.
First, let's take a close look at the what happens with thread priority adjustments inside the kernel clock handler. Our starting point is an existing kernel thread that has been executing for a bit. The kernel thread inherited its scheduling class, priority, and user-priority values and limits from its parent.
The kernel receives a clock interrupt 100 times per second (every 10 milliseconds) and enters a clock interrupt handler. Several housekeeping chores are done, and the clock handler loops through the linked list of all installed processors on the system. Clock tick handling is done for each configured and online processor, such as updating system, user, idle, and wait I/O times. Ultimately, the code looks at the thread running on the processor, and if it isn't an interrupt thread, tick processing is done for the kernel thread.
The system maintains an lbolt counter, which is incremented
in the clock interrupt handler. In the kernel thread, there's a
t_lbolt field, which also is incremented in the clock
interrupt handler if the kthread happens to be running on a processor
when the handler is entered. Sleeping or stopped threads won't have
their t_lbolt field incremented. The test to determine if we need to do
tick processing for the kernel thread is quite simple:
if (current lbolt value > threads lbolt value) to tick processing else don't do tick processing
Tick processing involves adjusting the thread's t_pctcpu field
(percent of CPU used since the last clock tick -- that
algorithm is a bit of rat hole, so we'll save it for another day);
setting t_lbolt to the current lbolt value in the system;
and calling the kernel clock_tick() code, which in turn invokes the class-specific
tick-handling code via the CL_TICK() macro. CL_TICK will resolve to
either ts_tick() for TS/IA class threads, or rt_tick() for RT class
threads. Tick processing is not done for SYS or interrupt class
threads. The ts_tick() code is represented in the following pseudocode.
ts_tick()
{
if (thread is not at a SYS priority) {
if (thread has used its time quantum) {
if (scheduler activation has been set for the thread) {
if (thread had at least 2 extra ticks)
force thread to yield CPU
return
}
else { /* no scheduler activation - typical case */
set new value for ts_cpupri
calculate the new user mode priority (ts_umdpri)
set ts_dispwait to zero
set a new_pri value from the ts dispatch table
do boundary check on new_pri value
set the threads t_pri field to the new_pri value
put it on a dispatch queue
}
else { /* thread did not use up its time quantum */
if (a higher priority thread was placed on the dispatch queue)
force the thread to surrender the CPU (preempt the thread)
}
}
}
What happens in the s_tick handler is pretty straightforward. A check
is made to ensure that the thread is not at a SYS priority -- the
system will boost a thread's priority to a SYS priority if it's holding
a resource, such as a reader/writer lock (as a reader), or a memory
page structure lock. Note that this approach is different from priority
inheritance, which exists for a similar reason, but is implemented
differently. If the thread isn't at SYS priority, we check the
ts_timeleft field in the tsproc structure, which is used to determine
if the thread has used up its CPU time quantum (the time quantum for a
given global priority level can be found in the ts_quantum column of
the dispatch table). If the time quantum has been used, the code checks
for a scheduler activation for the thread.
Scheduler activations are a feature of Solaris that allow an application to make a call into the kernel to notify it that a thread is holding a critical resource. In such a case, it is desirable to let the thread execute until it is done, so it will free the resource and avoid contention problems if other processes or threads also need the same resource (an application-level mutex lock or semaphore, for example). If an activation has been set, the code will potentially give the thread a few extra clock ticks to run -- two extra ticks to be precise. If an activation has been set, and the thread is within its two-tick limit, it will fall through to the next code segment for priority recalculation; otherwise, the thread will be forced to yield the CPU, and the code will return.
The typical scenario (I'm taking some liberties using the word
typical here; the use of scheduler activations in applications
that run on Solaris isn't widespread) is no activation, so the
priority adjustment is done. Using values from the tsproc structure,
ts_cpupri is reset, a new user mode (ts_umdpri)
is calculated, ts_dispwait is reset to 0, and the new
priority is set in the kernel thread. ts_cpupri is described
above as the "kernel component of the user priority," and is used by the
kernel as part of user-priority arithmetic.
To illustrate what happens, we'll establish some initial values. First,
a simple case. A compute-intensive thread is running at priority 58,
has not set a user priority via priocntl (thus a value of 0 in
ts_umdpri), has the initial default value of 29 in
ts_cpupri, and has a
default value of 20 in ts_nice. When a tsproc
structure is first initialized, ts_cpupri is set to 29 and
ts_nice is set to 20. As these
values are inherited during fork() or thread_create(),
the ts_nice value will remain at 20 assuming a nice(1)
command was never invoked. The ts_cpupri value will probably have changed from its initial value, because it is recalculated during the execution lifetime of a thread.
That is, it's recalculated when the thread is put to sleep, on return from
a trap, on a wakeup, or when the thread is about to be preempted. It will
also be recalculated inside the ts_tick() currently under examination.
First, ts_cpupri is set to the ts_tqexp value in the dispatch table,
indexed by the current ts_cpupri value:
ts_cpupri = ts_dispatch_table[ts_cpupri].ts_tqexp
The ts_tqexp column defines the new ts_cpupri
for threads that have used their time quantum, which is the case we're walking through.
Assuming a current ts_cpupri value of 29, the corresponding ts_tqexp
value is 19 (refer to the default TS dispatch table values), so the new
ts_cpupri value is 19. The new user priority value is calculated as
the sum of ts_cpupri + ts_upri + ts_boost.
Assuming the ts_upri is 0
(we didn't set a value with priocntl), the ts_boost value will either
be 0 (for a TS class thread) or 10 (for an IA class thread -- that's
the boost priority to give interactive processes better priorities).
Assume 0 for the purposes of our example. So the new ts_umdpri value
becomes 19 + 0 + 0, or 19. After the arithmetic is done, a boundary
check makes sure that ts_umdpri isn't less than 0 or greater than the
maximum allowable value (60). If it's greater, it is set to 60; if it's
less than 0, it is set to 0.
The new ts_umdpri value of 19 is now used as an index into the dispatch
table to retrieve the corresponding global priority:
new_priority = ts_dispatch_table[ts_umdpri].ts_globpri
Because the array indexing begins with the 0th entry, the global priority corresponding to the 19th array location is 18, thus the
thread's new priority will be 18. This follows with the intention of a timesharing scheduling class; a thread that has used its time quantum
has consumed a lot of CPU, so its priority is set to a lower (worse)
value. Lesser priorities have longer time quantums, so the thread will
potentially have to wait longer to run due to its lower priority, but
when it does run it will have a larger time quantum, going from 40
ticks as a priority-58 thread to 160 ticks as a priority-18 thread. If
this thread were to use up its time quantum on its next execution
cycle, and hit the clock_tick()->ts_tick() code again, its next
priority would be 6. ts_cpupri (value 19) would be reset based on
ts_tqexp in the 19th table location, which has a value of 7.
The new ts_umdpri value would be 7 (7 + 0 + 0) and
would be used to index into the TS dispatch table to fetch the corresponding
global priority (which in this case is 6). Once again, the thread used
its time quantum and had its priority worsened. This pattern would continue
for compute-bound threads, preventing them from starving other threads of
CPU cycles.
In practice, a thread will eventually fall victim to running on a processor that grabs a trap or interrupt, or a kernel preemption, and the priority adjustment will be boosted to compensate the thread for having been prematurely booted off the CPU.
As you can see from the priority arithmetic, if a priocntl(1) command
is issued on a process, the value specified will alter the final
priority the thread gets, where a negative value will worsen the
priority, and a positive value will potentially make it better. The
value specified on the priocntl(1) command line is plugged into the
ts_upri field, which is a component of the values used to determine
ts_umdpri. Note that even though the scheduling classes (TS and IA)
support user priority ranges of -60 to 60, the default priority limit
will be 0. In order to increase the limit, thereby allowing for
increasing the user priority to a value greater than 0, you must be
root.
Below is an example of the use of priocntl(1) on a program that creates two
bound compute-intensive threads. Note first that the threads are in the
IA class. This is because they inherited their scheduling class from the
parent process, which, in this case, was the kornshell that started the
program. Note also that even though the program explicitly creates two
bound threads, there are five threads total. The three additional threads are
the main() part of the program, which is implicitly a thread, and two
threads created by the threads library: the aslwp thread for signal
handling (see last month's column on signals) and a scheduler thread
used to schedule user-level threads. The code creates user threads, but
because it sets the THR_BOUND|THR_NEW_LWP flags in the thr_create(3T)
call, an LWP/kthread pair is created and the user thread is permanently
bound to its LWP/kthread pair. It is the LWP/kthread that is visible to
the kernel and the ps(1) command, not the user threads:
$ ./thr1 &
[1] 20323
$ ps -cL
PID LWP CLS PRI TTY LTIME CMD
20321 1 IA 55 pts/11 0:00 ksh
20323 1 IA 42 pts/11 0:00 thr1
20323 4 IA 0 pts/11 0:05 thr1
20323 5 IA 42 pts/11 0:00 thr1
20323 6 IA 0 pts/11 0:05 thr1
20323 7 IA 42 pts/11 0:00 thr1
$ priocntl -d -i pid 20323
INTERACTIVE CLASS PROCESSES:
PID IAUPRILIM IAUPRI IAMODE
20323 -12 -12 1
$ priocntl -s -m 50 -i pid 20323
Permissions error encountered on pid 20323.
$ priocntl -s -m 0 -i pid 20323
Permissions error encountered on pid 20323.
$ priocntl -s -m -50 -i pid 20323
$ priocntl -d -i pid 20323
INTERACTIVE CLASS PROCESSES:
PID IAUPRILIM IAUPRI IAMODE
20323 -50 -50 1
You can tell which LWP/kthreads are actually running the compute-bound
user threads by looking at the LTIME column -- they're the ones accumulating CPU
time. The first interesting thing to note is that when we first dumped the
upri (user priority) and uprilim (user priority limit) values, they came up as -12. This behavior is
specific to the ksh (kornshell). The kornshell will automatically
nice(1) a command put in the background. The tsproc structure maintains
a ts_nice field for compatibility with the nice(1) command, and the
nice value is used when calculating ts_uprilim and ts_upri. The default
value for the ts_nice field is 20. The ksh does a nice(4) (increment by 4), which results in a ts_nice value of 24. The ts_donice() function, which is the TS/IA class-specific function run as a result of a nice(1)
command, calculates ts_uprilim and ts_upri when a nice value is set.
The way the arithmetic works, they end up with a value of -12 when the
nice value is 24. Keep in mind that the implementation of nice(1) in
Solaris exists for compatibility purposes (old shell scripts and such;
use priocntl(1) instead of nice(1) for anything you're doing that's
new). Traditionally, a positive nice value resulted in a worse
priority, because older Unix systems had an inverse priority scheme,
lower values meant better priorities. The ksh uses a positive increment
of 4, which is intended to make the priority a little worse. The
formula used in the kernel code inverts the value so the desired
behavior is achieved (ts_upri ends up with a negative value, for example).
Back to the example, when I try to increase the uprilim to a higher (better) value, I get permission errors. Only when I set the uprilim to a more negative value (-50 in this case) does the command succeed, and both upri and uprilim are changed from the -12 to the -50 value, which will make their actual priority worse. Now let's try the whole thing again, this time as root (there are several more lines in this example, so I included line numbers for reference in the following text):
01 sunsys> su 02 # ./thr1 & 03 20380 04 # ps -cL 05 PID LWP CLS PRI TTY LTIME CMD 06 20380 1 IA 54 pts/10 0:00 thr1 07 20380 3 IA 54 pts/10 0:00 thr1 08 20380 4 IA 20 pts/10 0:07 thr1 09 20380 5 IA 54 pts/10 0:00 thr1 10 20380 6 IA 20 pts/10 0:06 thr1 11 20379 1 IA 55 pts/10 0:00 sh 12 20381 1 IA 45 pts/10 0:00 ps 13 # priocntl -d -i pid 20380 14 INTERACTIVE CLASS PROCESSES: 15 PID IAUPRILIM IAUPRI IAMODE 16 20380 0 0 1 17 # priocntl -s -m 60 -i pid 20380 18 # priocntl -d -i pid 20380 19 INTERACTIVE CLASS PROCESSES: 20 PID IAUPRILIM IAUPRI IAMODE 21 20380 60 0 1 22 # priocntl -s -p 50 -i pid 20380 23 # ps -cL 24 PID LWP CLS PRI TTY LTIME CMD 25 20380 1 IA 59 pts/10 0:00 thr1 26 20380 2 IA 59 pts/10 0:00 thr1 27 20380 3 IA 59 pts/10 0:00 thr1 28 20380 4 IA 59 pts/10 1:25 thr1 29 20380 5 IA 59 pts/10 0:00 thr1 30 20380 6 IA 59 pts/10 1:25 thr1 31 20380 7 IA 59 pts/10 0:00 thr1 32 20379 1 IA 59 pts/10 0:00 sh 33 20390 1 IA 59 pts/10 0:00 ps 34 # priocntl -d -i pid 20380 35 INTERACTIVE CLASS PROCESSES: 36 PID IAUPRILIM IAUPRI IAMODE 37 20380 60 50 1 38 # priocntl -s -p -50 -i pid 20380 39 # ps -cL 40 PID LWP CLS PRI TTY LTIME CMD 41 20380 1 IA 4 pts/10 0:00 thr1 42 20380 2 IA 14 pts/10 0:00 thr1 43 20380 3 IA 4 pts/10 0:00 thr1 44 20380 4 IA 0 pts/10 2:15 thr1 45 20380 5 IA 4 pts/10 0:00 thr1 46 20380 6 IA 0 pts/10 2:15 thr1 47 20380 7 IA 4 pts/10 0:00 thr1 48 20379 1 IA 58 pts/10 0:00 sh 49 20395 1 IA 58 pts/10 0:00 ps 50 #
After suing to root, starting the test program, and displaying the
LWP/kthreads with ps (lines 1 to 12),
we dump the upri and uprilim values (lines 13 to 16). This time
they're 0, because when we sued
to root, a /bin/sh (borne shell), not ksh, was started.
The /bin/sh and /bin/csh shells do not automatically
nice background processes. We
first increase the uprilim and dump the values (lines 17 to 21),
then increase the upri to 50 (line 22) and take a look
with a ps(1) command (lines 23 to 33). As you can see,
the priority is up on the threads, with values of 59. I can tell you that the
two-processor workstation I'm using to write this column got very
sluggish, performancewise, once I bumped the priorities up (two
compute-bound threads running at a high priority on a two-processor
system -- what did I expect?!).
After looking at the uprilim and upri values again (lines 34 to 37), I knocked the priority down by setting the user priority to -50 (line 38). At this point, the priorities of the threads went down and my workstation started behaving again. Note that even though, over time, the kernel would have normally bumped down the priority of the compute bound threads, with the upri at a constant 50, it will be factored in every time a priority calculation is done, and thus will always result in the thread getting a good priority. (Now you know why only a root user can create a better user priority!)
Although our example here used a compute-bound thread -- a thread that
has used its time quantum -- much of what we've talked about also applies to
threads that sleep and are awakened, or are preempted, or that for some
reason have been forced to wait an inordinate amount of time for a CPU.
Recall from earlier columns that the TS/IA dispatch table maintains
values for adjusting thread priorities as a result of not only using up
the time quantum (ts_exptq), but also for sleep and sleep returns
(ts_slpret), and lengthy waits for a processor (ts_lwait).
For these different conditions, the calculation of the new user priority is the
same in terms of the formula used, however, the actual values that are plugged
in will be different. When we index into the dispatch table using
ts_cpupri, we'll retrieve the corresponding value from the
ts_slpret column in the case of a return from sleep, versus
the ts_tqexp column we used for an expired time quantum.
For example, use
new_ts_cpupri = ts_dispatch_table[ts_cpupri].ts_slpret
instead of
new_ts_cpupri = ts_dispatch_table[ts_cpupri].ts_tqexp
Take our earlier example of the priority-58 thread with a
ts_cpupri value of 29. Same thread, only this time
it's getting a new priority from a sleep wakeup. In this case,
the thread would end up at priority 58 again, which
follows desired behavior for the TS class -- a thread that was
sleeping should get a high priority, to ensure it gets CPU soon.
One final note on TS/IA threads. A kernel ts_update() function is called
once per second via the callout mechanism. ts_update will update the
priorities of threads sitting on a dispatch queue waiting for a
processor. It checks the ts_dispwait field of the tsproc structure (how
long the thread has been waiting for the dispatcher to schedule it)
against the ts_maxwait column from the dispatch table, as indexed by
the thread's ts_umdpri. If the thread has been waiting longer than
ts_maxwait, its priority is made better, using the same method we
discussed earlier, this time getting the new ts_cpupri value from the
ts_lwait column and recalculating the user priority.
The clock tick handler for RT threads is infinitely simpler, because we don't time slice RT threads. It goes like this:
rt_tick()
{
if (thread has used its time quantum) OR
(a higher priority thread has been placed on the dispatch queue)
surrender the CPU
}
The RT dispatch table has only two columns, a time quantum and global priority. An RT thread runs until it completes, voluntarily sleeps (issues a blocking system call), or is preempted due to a higher priority thread.
The priocntl(1) command works with RT class threads as well. The ranges
are different: 0 to 59 in the case of the RT class. priocntl(1) can be
used to change the priority of an RT class thread, or alter the allotted
time quantum. RT threads don't support or implement the notion of user
priorities; the rtproc structure maintains a rt_pri field for
priorities set via priocntl(1), and uses that value as in index into
the RT dispatch table to retrieve the corresponding global priority.
Final thoughts
I am hopeful that this column has cleared up any lingering questions you may
have had, but if you're still left scratching your head, please let me know.
Next month, we're going to munge several miscellaneous topics together, including priority inheritance, preemption (another subject that has raised many a reader query), and signal queuing support.
Stay tuned!
![]()
Resources
About the author
![]() Jim
Mauro is currently an area technology manager for Sun Microsystems
in the Northeast, focusing on server systems, clusters, and high
availability. He has a total of 18 years of industry experience,
working in educational services (he developed and delivered courses on
Unix internals and administration) and software consulting.
Reach Jim at jim.mauro@sunworld.com.
Jim
Mauro is currently an area technology manager for Sun Microsystems
in the Northeast, focusing on server systems, clusters, and high
availability. He has a total of 18 years of industry experience,
working in educational services (he developed and delivered courses on
Unix internals and administration) and software consulting.
Reach Jim at jim.mauro@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-06-1999/swol-06-insidesolaris.html
Last modified: