Getting to know the Solaris filesystem, Part 1
Learn all about the inner workings of your on-disk filesystem, including allocation management, storage capacity and access control list support, and metadata logging
May 1999
|
|
Getting to know the Solaris filesystem, Part 1Learn all about the inner workings of your on-disk filesystem, including allocation management, storage capacity and access control list support, and metadata logging
|
May 1999 |
Richard starts this journey into the Solaris filesystem by looking at the fundamental reasons for needing a filesystem and at the functionality various filesystems provide. In this first part of the series, you'll examine the evolution of the Solaris filesystem framework, moving into a study of major filesystem features. You'll focus on filesystems that store data on physical storage devices -- commonly called regular or on-disk filesystems. In future articles, you'll begin to explore the performance characteristics of each filesystem, and how to configure filesystems to provide the required levels of functionality and performance. Richard will also delve into the interaction between Solaris filesystems and the Solaris virtual memory system, and how it all affects performance. (5,000 words)
|
Mail this article to a friend |
These functions have grown into what we now commonly know as the complex file manipulation facilities offered in the modern Unix environment. The capabilities of the filesystems have grown tremendously, and the data management interfaces they provide are much more extensive.
An application uses the file as an abstraction to address a linear range of bytes that are to be stored on some form of input/output medium, typically a storage device such as an SCSI disk. To access a file, the operating system provides file manipulation interfaces to open, close, read, and write the data within each file. In addition to read and write, the operating system provides facilities to seek within each file to allow random access to the data.
The storage devices also provide access to a linear series of data bytes, organized into groups of bytes known as blocks. For example a 1-gigabyte (GB) disk stores 230 (1,073,741,824) bytes of data that may be accessed in 512-byte groups known as blocks. Each block of data is individually addressable and may be accessed in a random order. Using the basic file interfaces, an application can access all the data in a storage device by seeking to individual locations and retrieving the data. However, without any way of organizing the storage of multiple files, each storage device will appear as a single file to the application. The job of the filesystem is to provide a layer between the application's notion of files and the storage device, so that multiple files may reside on a single storage device, and the filesystem is responsible for managing the storage of each file. The filesystem presents each storage device as a series of directories each of which holds several files.
Support for multiple filesystem types
Early versions of Unix were designed around a single filesystem, which
was used to implement the entire directory hierarchy for the operating
system. Sun Unix 0.7 was the first BSD-based Sun Unix, and just like BSD
4.2 it used the fast filesystem (FFS) as its only filesystem type.
This basic provision of a single filesystem was sufficient because there
was only one type of storage medium on which files were held. Files were known
internally to the operating system by a special node, called the index node or inode, that described the files' size, contents, and attributes.
The need to support file access across networks led to the development of a flexible environment that allowed concurrent support of multiple file systems. A new type of filesystem was introduced that allowed remote files to be accessed just like the files on a regular disk-based filesystem. The filesystem representation of remote files is known as the network filesystem, NFS, and was introduced in 1985 by Sun. It is now shared between many different computer system vendors.
The virtual filesystem (VFS) framework, which provides support for multiple concurrent filesystem types, and a new virtual abstraction of the inode concept, the vnode, were first implemented in Sun Unix 2.0 in 1985. The Berkeley fast filesystem was converted to make use of the new vnode architecture, and since then has been known as the Unix filesystem, or UFS.
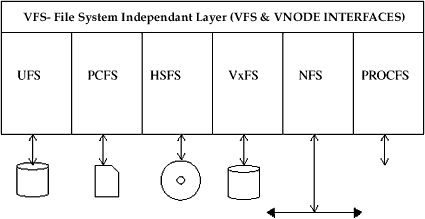
Figure 1. Solaris filesystem framework |
The vnode framework has evolved into the flexible virtual filesystem framework used in Solaris today. Along with Unix System V, BSD, and many other flavors of Unix, vnode has provided the environment under which many different filesystems have been developed. Figure 1 shows some of the filesystem types available in Solaris today.
The notion of a filesystem that presents non-disk devices as a filesystem has been used extensively since its introduction with the NFS filesystem. Filesystems have now been used to represent many operating system abstractions to the user. For example, in Solaris the list of processes can be mounted as a filesystem, and each process appears as a file. The Solaris pseudofilesystems are used to represent processes, network sockets, character device drivers, and some other virtual file abstractions. Filesystems that don't represent physical disk devices are known as pseudofilesystems, while filesystems that provide a means to store and retrieve regular files are known as regular filesystems. The filesystem types available in Solaris are shown in the following table:
| Filesystem | Type | Device | Description |
| UFS | Regular | Disk | Unix Fast filesystem; default in Solaris |
| VxFS | Regular | Disk | Veritas filesystem |
| QFS | Regular | Disk | QFS filesystem from LSC Inc. |
| pcfs | Regular | Disk | MSDOS FAT and FAT32 filesystem |
| hsfs | Regular | Disk | High Sierra filesystem (CDROM) |
| tmpfs | Regular | Memory | Uses memory and swap |
| nfs | Pseudo | Network | Network filesystem |
| cachefs | Pseudo | filesystem | Uses a local disk as cache for another NFS filesystem |
| autofs | Pseudo | filesystem | Uses a dynamic layout to mount other filesystems |
| specfs | Pseudo | Device drivers | filesystem for the /dev devices |
| procfs | Pseudo | Kernel | /proc filesystem representing processes |
| sockfs | Pseudo | Network | Filesystem of socket connections |
| fifofs | Pseudo | Files | FIFO filesystem |
In addition to the filesystems provided with Solaris, there are a number of third-party filesystems that provide an additional set of features to the regular UFS filesystem.
Regular (disk) filesystems
Regular filesystems are those that allow storage of files and data on
some form of storage media and are the most commonly known type of file
system. Regular filesystems implement the basic operating system
facilities, which include
filesystems that are implemented on local storage are known as on-disk filesystems, and use a rigid filesystem structure on the storage media. In this article, we'll explore three disk-based filesystems for Solaris:
Allocation and storage strategy
A filesystem stores data on the storage device by managing the allocation
of each file's blocks within the filesystem. This is done by maintaining
the location of each block for each file in an on-disk structure. Each
filesystem uses a different method for allocation and retrieval of file
blocks.
There are two common types of filesystem space allocation strategies: block allocation and extent allocation. Block-based allocation creates incremental disk space for a file each time it is extended, whereas extent-based allocation creates a large series of contiguous blocks each time the file exhausts the space available in its last extent.
Block-based allocation
The block-based allocation mechanism used by traditional Unix filesystems (such as UFS) provides a flexible and efficient block allocation
policy. Disk blocks are allocated as they're used, which means that a minimal
number of filesystem blocks are allocated to a file in an attempt to conserve
storage space. When a file is extended, blocks are allocated from a free
block map, so that blocks are sometimes allocated in a random order.
This can cause excessive disk seeking, and subsequential reads from the
filesystem will result in the disk mechanism seeking to all of the random
block locations that were allocated during the extension of the file. Random
block allocation can be avoided by optimizing the block allocation policy
so that it attempts to allocate a sequential series of blocks. By using
a smarter block allocation, large sequential allocations can be achieved.
This results in greatly reduced disk seeking. Continuous filesystem block
allocation will, however, eventually end up with file blocks fragmented across
the filesystem, and filesystem access will eventually revert back to
a random nature.
The block allocation scheme must also write information about where each new block is allocated every time the file is extended. If the file is being extended one block at a time, a lot of extra disk I/O will be required to write the filesystem block structure information. Filesystem block structure information is known as metadata. Filesystem metadata is always written synchronously to the storage device, which means operations that change the size of a file need to wait for each metadata operation to complete. As a result, metadata operations can significantly slow overall filesystem performance.
Extent-based allocation
Extent-based filesystems allocate disk blocks in large groups at a single time,
which forces sequential allocation. As a file is written, a large number
of blocks are allocated, after which writes
can occur in large groups or clusters of sequential blocks. Filesystem
metadata is written when the file is first created. Subsequent writes within the first allocation extent of blocks do not require additional metadata writes (until the next extent is allocated).
This optimizes the disk seek pattern, and the grouping of block writes into clusters allows the filesystem to issue larger physical disk writes to the storage device, saving the overhead of many small SCSI transfers. Figure 2 shows a comparison between block- and extent-based allocation. We can see that a block address number is required for every logical block in a file on a block-allocated file, resulting in a lot of metadata for each file. In the extent-based allocation method, only the start block number and length is required for each contiguous extent of data blocks. A file with only a few very large extents requires only a small amount of metadata.
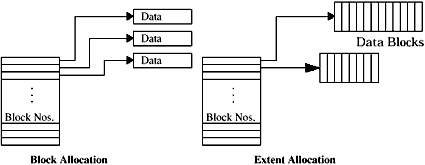
Figure 2. Block allocation vs. extent allocation |
Extent-based filesystems provide good performance for sequential file access because of the sequential allocation policy and block clustering into larger writes; however, many of the benefits of extent-based filesystems aren't leveraged when the filesystem is being used for random I/O. For example, if we want to read sequentially though an extent-based file, we only need to read the start block number and the length; then we can continue to read all of the data blocks in that extent, which means very little metadata read overhead is incurred in reading sequentially. In contrast, if we were to read a file in a random manner, we would need to look up the block address for the desired block for every data block read -- this is similar to what we would do with a block-based filesystem.
| Filesystem | Allocation format |
| UFS | Block, allocator tries to allocate sequential blocks |
| VxFS | Extent based |
| QFS | Extent based |
Using block clustering to achieve extent-like performance
The sequential access performance of the block-allocated filesystems quickly became a major limiting factor for overall system
performance. This has motivated several enhancements to block allocation
of filesystems. In 1991, a study by Steve Kleiman and Larry McVoy
at Sun showed that by modifying UFS to allocate large sequential
series of disk blocks and grouping reads and writes into larger
clusters, UFS could be made to perform at similar rates to that of an
extent-based filesystem. The UFS filesystem allocator was enhanced
so that UFS can allocate up to 16-megabyte (MB) extents at once
when a file is sequentially written. This provides the foundation to
perform reads and writes larger than the block size when accessing a
file sequentially because the filesystem blocks are now ordered
adjacent to the storage device.
Several enhancements to the UFS write code were implemented to delay writes long enough so that one large write could be performed in place of several smaller writes. This allows the filesystem to issue one large write to the disk device, which is much more efficient than many smaller writes. Similarly, the UFS read paths were changed, such that if sequential access is being made to a file, a whole group of blocks are read in at once, effectively reading ahead into the file being accessed. The read enhancements also facilitated UFS to generate large read requests of the storage device in place of smaller requests, which eliminated the need to wait for many small individual disk I/Os for each read. The size of the groups or "block clusters" being read and written is controlled by the filesystem maxcontig parameter, and defaults to either 128 KB or 1 MB. We'll go into cluster sizes in more depth in future articles in this series.
The initial tests showed an increase in throughput increase of 100 percent, with a reduction of CPU overhead of 25 percent. Today, block clustering allows sequential reads of single files at over 100 MB per second with some configurations. To make best use of the block clustering and sequential allocation, a file should be preallocated where possible. This will provide proper sequential allocation of the disk blocks, and as a result, future disk I/O can take advantage of the block clustering capability for extended performance.
Filesystem capacity
Filesystem capacity has become very important in
recent years. This is the result of two important happenings:
Disk capacity has grown from average sizes of 50 MB to more than 36 GB per spindle, and the introduction of logical storage (RAID) has meant that storage device size is now a function of the number of drives in the storage device. Storage devices provide virtual disk representation of multiple disks, and often 10 or more disks will be combined into a single virtual disk, with sizes now exceeding the 1 terabyte (TB) mark.
Many Unix filesystems were designed in the early 1980s to use disk sizes in the order of 50 MB. At the time sizes of 1 TB sounded unrealistic; by contrast, today's storage devices are often configured with several terabytes of capacity.
The mechanism by which devices are addressed in many Unix implementations is a function of 32-bit addressing, which limits file and filesystem addresses to 2 GB. As a result, early filesystems were limited to a maximum file system size of 2 GB. Solaris introduced the ability for a filesystem to grow beyond the 2-GB limit by implementing 64-bit file offset pointers in the disk device drivers. The filesystem is now able to provide support beyond the 2-GB limit because filesystem addresses are divided into 512-byte sectors, translating into a maximum file and filesystem size of 2 31 * 512 = 1 TB.
With Solaris 2.6, support was added to the operating system to allow logical file sizes up to 263 bytes; this means that a file on UFS may be as large as the filesystem (1 TB).
The Veritas VxFS and LSC QFS filesystems provide support beyond 1 TB. In fact, filesystem sizes up to 263 bytes are supported.
| Filesystem | Max. capacity | Max. file size |
| SunOS 4.x UFS | 2 GB | 2 GB |
| Solaris UFS | 1 TB | 2 GB |
| Solaris 2.6 UFS | 1 TB | 1 TB |
| VxFS | 8,000 TB | 8,000 TB |
| QFS | 1 petabyte | 1 PB |
Variable block size support
The block size used by each filesystem often differs with the type of
filesystem, and in many cases each filesystem can support a range of different
block sizes. The block size of a filesystem is typically configured at
the time the filesystem is created by a tunable parameter.
The block size of a filesystem affects the performance and efficiency of the filesystem in different ways. When a file is allocated, the last block in the file is partly wasted. If the file is small, the amount of overhead in the filesystem can be large in proportion to the amount of disk space used by files. A small block size provides very efficient space utilization because the space wasted in the last block of each file is minimal; however, small block sizes increase the amount of information required to describe the location and allocation of each disk block, so that sequential performance of large files can be adversely affected. A large block size provides greater filesystem performance at the penalty of efficiency because more space is wasted at the end of each file.
| Space used | Percentage wasted | File size & filesystem block size |
| 2 MB | 0% | 2-KB files on 512-byte blocks |
| 2 MB | 0% | 2-KB files on 1024-byte blocks |
| 4 MB | 50% | 2-KB files on 4096-byte blocks |
| 8 MB | 75% | 2-KB files on 8192-byte blocks |
| 1 GB | 0% | 1-MB files on 512-byte blocks |
| 1 GB | 0% | 1-MB files on 1024-byte blocks |
| 1 GB | 0% | 1-MB files on 4096-byte blocks |
| 1 GB | 0% | 1-MB files on 8192-byte blocks |
| 1 GB | 6% | 1-MB files on 64-KB blocks |
Table 4 shows the amount of space wasted for 1,000 files of two different sizes on filesystems with various block sizes. The efficiency tradeoff is clearly only applicable for filesystems containing many small files. Filesystems with file sizes an order of magnitude higher than the block size have no significant space overhead from the different block sizes, and since disk space is so cheap the efficiency overhead is rarely an issue.
Another important factor for block sizes is the data access size. Although the average filesystem size has catapulted over the years, the average size of data accessed is often still very small. For example, an OLTP database with tables containing customer information such as name, address, and zip only occupies a few hundred bytes, and the read/write operations to the filesystems will be very small. Databases typically access the filesystems in 2 KB,4 KB, 8 KB, or 16 KB sizes. Here, the smaller block size may well be better suited to the size of the database access size. A larger block size may provide better sequential performance, but the small and random access from a database will not benefit from having to retrieve a larger block because they are only using a small portion of the block.
A block size of 4 KB or 8 KB is often optimal for databases, where the largest possible block size is optimal for large sequential file access. At this time, the Solaris UFS only supports a 4-KB or 8-KB block size. Table 5 shows the different block sizes supported on different filesystems.
| Filesystem | Block size support | Sub block support |
| Solaris UFS | 4 KB or 8 KB | 512-8 KB fragments |
| VxFS | 512 bytes to 8 KB | N/A |
| QFS | 1 KB to 512 KB | N/A |
The UFS filesystem provides an additional allocation unit known as a fragment, which is smaller than the filesystem block size. A fragment may be allocated in the last block of a file to provide more space efficiency when storing many small files. The UFS fragment may be configured between 512 bytes and the block size of the filesystem, and defaults to 1 KB.
|
|
|
|
|
Access control lists
The traditional Unix filesystem provides a simple file access scheme based
on users, groups, and world, where each file is assigned an owner and a
Unix group. A bit map of permissions for user, group, and world
is then assigned.

Figure 3. Unix filesystem access scheme |
This scheme is flexible when file access permissions align with users and groups of users, but it does not provide any mechanism to assign access to lists of users that do not coincide with a Unix group. For example, if we want to give read access to file1 to Mark and Chuck, and then read access to file2 to Chuck and Barb, we would need to create two Unix groups, and Chuck would need to switch groups with the chgrp command to get access to either file.
To overcome this, some operating systems use an access control list (ACL), where lists of users can be assigned to a file with different permissions. Solaris introduced the notion of ACLs in the B1 secure version, known as Trusted Solaris in 1993. Trusted Solaris ACLs were integrated with the commercial Solaris version in 1995, with Solaris 2.5. Solaris ACLs allow the administrator to assign a list of Unix users IDs and groups against a file with the setfacl command, and to review the ACLs with the getfacl command. For example, we can assign access to a file for a specific user by using the setfacl command. Note that the Unix permissions on the file now contain a plus sign (+), which indicates that there is an ACL assigned to this file.
# setfacl -m user:jon:rw- memtool.c
# getfacl memtool.c
# file: memtool.c
# owner: rmc
# group: staff
user::r--
user:jon:rw- #effective:r--
group::r-- #effective:r--
mask:r--
other:r--
# ls -l memtool.c
-r--r--r--+ 1 rmc staff 638 Mar 30 11:32 memtool.c
Multiple users and groups can be assigned to a file, which provides a flexible mechanism for assigning access rights. Access control lists can be assigned to directories as well. Note that unlike some other operating systems, ACLs are not inherited from their parent -- creating a new directory under a directory with an ACL will not have an ACL assigned by default.
| Filesystem | ACL support? |
| Solaris 2.0-2.4 UFS | No |
| Solaris 2.5 UFS | Yes |
| VxFS | Yes |
| QFS | No |
Logging filesystems
Two important criteria for commercial systems are reliability and
availability, both of which may be compromised if the filesystem
does not provide the required level of robustness. We have become
familiar with the term journaling to mean just one thing, but in
fact there are several ways filesystem logging can be
implemented. The three most common forms of journaling are
A filesystem must be able to deliver reliable storage to the hosted applications, and in the event of a failure it must also be able to provide rapid recovery to a known state. The original implementations of Unix filesystems did not meet this criteria, since they left the filesystem in an unknown state in the event of a system crash or power outage, and often took a very long time (30-plus hours for a filesystem with many files) for consistency checking at boot time.
To overcome these issues, we can dramatically increase the robustness of a filesystem by using logging (aka journaling) to prevent the filesystem structure from becoming corrupted during a power outage or a system failure. The term journaling is used to describe a filesystem that logs changes to on-disk data in a separate sequential rolling log. The primary reason for doing this is to maintain an accurate picture of the filesystem state, so that in the event of a power outage or system crash, the state of the filesystem is known; thus, rather than doing a lengthy scan of the entire filesystem (via fsck), the filesystem log can be checked, and the last few updates can be corrected where necessary. A logging filesystem can mean the difference between mounting a heavily populated filesystem in 20 seconds versus 30-plus hours without a log.
It should also be noted that logging doesn't come for free, and there is a significant performance overhead. Logging does require more slow synchronous writes, and the most popular implementation of logging (metadata logging) requires at least three writes per file update, which is significantly more than would be required without logging. As a result, we should pay attention to what our requirements are: Do we want the filesystem to go fast, or do we need maximum reliability? For example, if we're using a filesystem for a high performance HPC task that creates a lot of output files, we want absolute performance but may not care about filesystem robustness were a power outage to occur, and in this case we should choose not to use logging. On the other hand, if we're building a clustered database system we absolutely require filesystem reliability, and logging is considered mandatory, even with the performance overhead.
Table 7 shows the types of logging used in different filesystems.
| Filesystem | Logging characteristics | Comments |
| UFS (2.6 and earlier) | No logging without SDS | |
| Solaris 2.4-2.5.1 UFS with SDS 3.0-4.x | Metadata logging with logging of small sync user data | Can have separate log device |
| Solaris 2.6 with SDS 3.0-4.x | Metadata logging only | Can have separate log device |
| Solaris 7 UFS | Metadata logging | Log is embedded in filesystem |
| VxFS | Data and metadata logging | Default is metadata logging only |
| VxFS with NFS Accelerator | Data and metadata logging | Log is placed on a separate device |
| QFS | Logging not used | Can do quick mount on reboot without fsck after crash |
Metadata logging
The most common form of filesystem logging is metadata logging.
When a filesystem makes changes to its on-disk structure, it uses
several disconnected, synchronous writes to make the changes. If an
outage occurs half way through an operation, the state of the filesystem is unknown, and the whole filesystem must be consistently
checked. For example, if one block is appended to the end of a file,
the on-disk map that tells the filesystem where each block for the
file is located needs to be read, modified, and rewritten to the
disk before the data block is written. When a failure occurs, the
filesystem must be checked before it is mounted at boot; the filesystem doesn't know if the block map is correct, and it also doesn't
know which file was being modified during the crash -- this results
in a full filesystem scan, often taking minutes or hours.
A metadata-logging filesystem has a cyclic, append-only log area on the disk it can use to record the state of each disk transaction. Before any on-disk structures are changed, an intent-to-change record is written to the log. The directory structure is then updated and the log entry is marked complete. Since every change to the filesystem structure is in the log, filesystem consistency can be checked by looking in the log without the need for a full filesystem scan. At mount time, if an intent-to-change entry is found but not marked complete, then the file structure for that block is checked and adjusted where necessary.
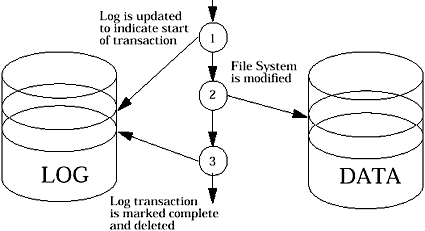
Figure 5. Filesystem metadata logging |
This method of logging has been implemented successfully on several filesystems, and is the basis for the logging UFS filesystem used in Solaris. It retains the on-disk filesystem structure for UFS and can be enabled or disabled at any time without the need to change on-disk data. The Veritas VxFS filesystem also uses metadata logging. Some filesystems have the log embedded in the same partition as the filesystem data, while others allow separation of the log from the filesystem. The unbundled UFS logging in Solstice Disk Suite allows a separate log and data, while the bundled logging UFS in Solaris 7 does not. Veritas allows the log to be separated only when the Veritas NFS Accelerator option is purchased to enable this feature.
Logging of both data and metadata
Some filesystems provide an option to put file data into the log in
conjunction with the metadata. This can be particularly useful for
small synchronous writes, which would require two or more writes to
different parts of the disk for every application write (one for the
data and one for the log write). By putting the data into the log, we
can avoid the second seek and write. The data is first written to
the log, and then replayed into the filesystem. This does two
things: it ensures data integrity up to but not including the last
block written, and it can help performance for small synchronous
writes. The Veritas VxFS filesystem has an option to log both data
and metadata.
Log-structured filesystems
Traditional filesystems are block-allocated, and device blocks are
allocated from a map of free blocks. An alternative filesystem
format is a log-structured filesystem, which implements the entire
filesystem as a log. The log-structured filesystem appends data
blocks to the end of the log each time blocks are written to a file,
invalidating earlier written blocks as it goes. This approach
allows every file to be written to sequentially, regardless of the
block order of the writes, which provides very fast write
performance.
The log-structured filesystem offers extremely high write performance at the cost of read performance and complexity. Read performance is often much slower since blocks are allocated in the order they are written, which may mean that files are fragmented across the disk in an arbitrary order. Another downside to log-structured filesystems is complexity, because a separate garbage collector or cleaner process is needed to scan the filesystem and remove invalidated blocks, and a complex caching/lookup mechanism is required to enable efficient lookups. The lookup cache is needed because blocks are allocated in a random order, and the location of the blocks for each file must be maintained.
Log-structured filesystems prove to be efficient in metadata-intensive environments, but have yet to be proven more efficient for data-intensive workloads. It is important to note the difference between log-structured and logging filesystems. Log-structured filesystems are also known as write anywhere filesystem layout (WAFL).
There are currently no log-structured filesystems available for Solaris.
Expanding and shrinking filesystems
A common requirement for online storage management is the ability to
grow and shrink filesystems. Early filesystems did not support
this requirement because a disk was fixed in size. Now that we have
virtual disks via volume managers, we have the ability to change the
size of the underlying device. Without the ability to grow a file
system we would need to backup the filesystem, make the filesystem
again with mkfs/newfs, and then restore all the filesystem data. A
filesystem that has the ability to grow in size online removes the
need for this disruptive process. A Solaris UFS filesystem may be
extended with the mkfs command using the -M option for mounted
filesystems and the -G option for unmounted filesystems. Examples
of this will be shown in future articles.
In addition to growing a filesystem, there is sometimes the requirement to do the reverse. For example, if we want to reclaim space from one device to assign to another, we would need to shrink the filesystem first, so that any allocated file blocks are moved away from the end of the filesystem that is being shrunk.
| Filesystem | Grow | Shrink |
| Basic UFS | Yes, via mkfs -M | No |
| VxFS | Yes, via fsadm | Yes, via fsadm |
| QFS | No | No |
Direct I/O
In order to provide near-device performance, many filesystems have
the option to bypass the filesystem cache via a mechanism known as
direct I/O. This reduces the overhead of managing cache allocation
and completely removes all interaction between the filesystem and
the memory system. Often in such cases the resulting performance can be
many times worse, because there is no cache to buffer reads and
writes; but when caching is done in the application, direct I/O can be a
benefit. Another important use of direct I/O involves backups, when
we don't want to read a file into the cache during a backup.
Applications such as databases do their own caching, and direct I/O offers a mechanism to avoid the double caching that would occur if they were to use a regular filesystem. Without direct I/O, an application reads a file block into the Solaris filesystem cache, and then reads it into the database shared buffer (e.g., Oracle's block cache). So, the block exists in two places. However, with direct I/O, the block is read directly into the database cache without the need to pass though the regular filesystem cache.
Because direct I/O bypasses the filesystem cache, it also disables filesystem read ahead. This means that small reads and writes result in many separate I/O requests to the storage device which would have otherwise been clustered into larger requests by the filesystem. Therefore, direct I/O should only be used for random I/O or large-block sequential I/O. Another side effect of direct I/O is that it does not put load on the Solaris memory system, and removes the typical paging that can be seen when a regular filesystem is used. This is a frequent motivator for the use of direct I/O, but it should be noted that the new priority paging feature of Solaris can be used to provide similar separation between the filesystems and applications. Refer to http://www.sun.com/sun-on-net/performance.html for more detail on how priority paging improves filesystem behavior.
Direct I/O was initially implemented in the UFS filesystem, and VxFS has subsequently been enhanced to provide a wide range of direct I/O facilities. The UFS direct I/O facility provides a mechanism to enable direct I/O per file or per filesystem. The VxFS filesystem implements direct I/O automatically for I/O sizes larger than 256 KB by default (this size can be tuned), and also provides a mechanism to create a raw device which represents direct access to the file. QFS has similar options to UFS to allow direct I/O on a per-file basis.
Sparse files
Some filesystems allow the creation of files without allocation of disk
blocks. For example, a 1-GB file can be created by opening a file, seeking
to 1 GB and then writing a few bytes of data. The file is essentially created
with a hole in the middle, and although the file size is reported as 1
GB, only one disk block would be used to hold such a file. Files with allocation
holes are known as sparse files. Accesses to locations with a sparse file that have no blocks allocated simply return a series of zeros, and blocks
are not allocated until that location within the file is written to. Sparse
files are particularly useful when using memory mapped files, or files for
databases, because they remove the need for complex file allocation algorithms
within an application. For example, a simple database application can store
records in a file by seeking to the require offset and storing the record,
and the file will only use as much space as there are records in the file,
and leave holes where there are empty records.
Integrated volume management
Volume management allows multiple physical disks to be utilized as a single
volume to provide larger aggregate volume sizes, better performance, and
simplified management. Volume managers are typically implemented
as a separate layer between the physical disks and present themselves as virtual disk devices. Databases and filesystems may be mounted on these
larger virtual disk devices, and the same management techniques may be
used to manage the data within each virtual volume.
There are however, some filesystems that provide volume management capabilities within the filesystem. The QFS filesystem from LSC provides integrated volume management and allows striping and concatenation of files within the filesystem. The filesystem is configured on multiple devices, rather than the traditional single device. Each file within the filesystem may be concatenated or striped with different interlace sizes, on a file-by-file basis.
Summary
In this article we've walked though the most common filesystem features
and drawn comparisons between different filesystems. Table 9
summarizes the filesystem features we've covered so far.
Next month, we'll begin to look more deeply into the implementation and performance of different filesystems, and how filesystem caching in Solaris is implemented and tuned.
| Feature | UFS | VxFS | QFS | Notes |
| Max. file size | 1 TB | 263 | 263 | Maximum file size |
| Max. filesystem size | 1 TB | 263 | 263 | Maximum size of filesystem |
| Logging | Yes | Yes | No | Greater data integrity, faster reboot, faster fsck |
| Separate log | Yes, with SDS | Yes, with NFS Accelerator | No | A separate log device can be attached to the filesystem to avoid seeking back and forward from the log to the data |
| Extent-based | No | Yes | Yes | Less disk seeks due to simpler block allocation schemes |
| Direct I/O | Yes, Solaris 2.6 and up | Yes | Yes | Direct I/O options allow bypassing of the page cache based on mount options and runtime directives |
| Extendable | Yes | Yes | No | The filesystem size can be expanded online |
| Shrinkable | No | Yes | No | The filesystem size can be shrunk online |
| Snapshot, by locking filesystem | Yes | Yes | No | The filesystem can be locked and frozen for a backup snapshot. Locking suspends all filesystem activity during the backup |
| Online Snapshot | No | Yes | No | A frozen version of the filesystem can be mounted while the main filesystem is online. This can be used for online backup |
| Quotas | Yes | Yes | No | Disk space quotas can be enforced |
| ACLs | Yes | Yes | No | Enhanced file permissions via ACLs |
| HSM Capable | No | Yes | Yes | Automatic hierarchical storage management options available |
| Page Cache Friendly | Yes | No | No | UFS will not cause memory shortage when used in sequential mode. VxFS and QFS must be used in direct mode to avoid causing a memory shortage |
| Stripe Alignment | No | Yes | Yes | Ability to align clustered writes with storage stripe to allow whole stripe writes. Provides superior RAID-5 performance |
| Integrated Volume Manager | No | No | Yes | Striping and concatenation across multiple storage devices possible from filesystem |
|
|
Resources
About the author
![]() Richard McDougall is an established engineer in the Enterprise Engineering group
at Sun Microsystems where he focuses on large system performance and
operating system architecture. He has more than 12 years of performance
tuning, application/kernel development, and capacity planning experience
on many different flavors of Unix. Richard has authored a wide range of
papers and tools for measurement, monitoring, tracing and sizing of Unix
systems including the memory sizing methodology for Sun, the set of
tools known as "MemTool" allowing fine grained instrumentation of memory
for Solaris, the recent "Priority Paging" memory algorithms in Solaris
and man of the unbundled Tools for Solaris. Richard is currently
co-authoring the Sun Microsystems book, Solaris Architecture with Jim
Mauro, which details Solaris architecture, implementation, tools, and
techniques.
Richard McDougall is an established engineer in the Enterprise Engineering group
at Sun Microsystems where he focuses on large system performance and
operating system architecture. He has more than 12 years of performance
tuning, application/kernel development, and capacity planning experience
on many different flavors of Unix. Richard has authored a wide range of
papers and tools for measurement, monitoring, tracing and sizing of Unix
systems including the memory sizing methodology for Sun, the set of
tools known as "MemTool" allowing fine grained instrumentation of memory
for Solaris, the recent "Priority Paging" memory algorithms in Solaris
and man of the unbundled Tools for Solaris. Richard is currently
co-authoring the Sun Microsystems book, Solaris Architecture with Jim
Mauro, which details Solaris architecture, implementation, tools, and
techniques.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-05-1999/swol-05-filesystem.html
Last modified: