Fiddling around with files, part threeJim Mauro continues fiddling around with file types and moves on to look into file access modes and other file bits |
April 1998 |
I should rename this column "Forging ahead with files"! This, the third column in the series, continues with file types. Following that, we'll get into file access modes, file flags, and file locking.Note to readers: Last month's column went online with a few bugs. Thanks to our astute readers, we located the problems and applied fixes. It's possible, however, that you read the column before it was corrected, as the final fixes did not get out until March 10. If you read the column prior to that date, you may want to take a minute to reread the first six paragraphs of the column along with the section on APIs.
Some of the information provided in last month's "Readers Speak Out: Letters to the Editor," where Jim addressed a question from a reader, was also incorrect. That information has been corrected now as well. (3,800 words)
|
Mail this article to a friend |
Links actually come in two flavors, hard links and symbolic links.
Hard links are not really file types, but rather are simply
directory entries. A file with multiple hard links is a file whose
name appears in multiple directories. The name does not have to be
the same, as the reference to the same file is managed by the
operating system using the file's inode number (remember from last
month -- the file entry in a directory includes the file's inode
number, which is guaranteed to be unique within the same file
system). The actual number of hard links to a file are maintained in
the file's inode, so as new links get created, the link count is
incremented. The kernel can then track unlinks (to remove a file the
shell rm(2) and rmdir(2) commands actually
use the unlink(2) system call) such that the kernel does
not really remove a file until the unlink results in a link count of
zero, which means that no other links to the file exist. If additional
file links exist, when an unlink to a file is executed the kernel will
simply remove the directory entry (providing the permissions allow for
the operation).
Creating hard links to directories is allowed only if the effective uid of the operation is root (superuser). As you can imagine, creating hard links to directories without careful thought could create some interesting directory traversal problems.
The ln(1) command is used to create hard links.
sunsys> ls -li of.c
11294 -rw-r--r-- 1 jim staff 253 Mar 8 21:08 of.c
sunsys> ln of.c ../oflink.c
sunsys> ls -li of.c
11294 -rw-r--r-- 2 jim staff 253 Mar 8 21:08 of.c
sunsys> ls -li ../oflink.c
11294 -rw-r--r-- 2 jim staff 253 Mar 8 21:08 ../oflink.c
sunsys>
In the above example, we do a long listing, including the inode number of the file of.c. Note that the inode number is 11294 and there is only one link to the file (third column from the left is the link count). We then create a link to the of.c file in the parent directory and do another long listing of of.c, as well as the newly created link, oflink.c. Note that the link count goes up to two, and the inode number remains the same. We now have a file with two names, each of which appears in a different directory in the same file system. By definition, hard links cannot span file systems.
Symbolic links are a very different animal and are actual file
types. A symbolic link is logically a "pointer" to a file somewhere
else in a file system. Unlike hard links, symbolic links can
reference files in other file systems. Symbolic links are created
using the same ln(1) command with the -s command flag.
sunsys> ln -s files/files.p3 flink sunsys> ls -li flink 5651 lrwxrwxrwx 1 jim staff 14 Mar 3 22:16 flink -> files/files.p3 sunsys> ls -li files/files.p3 11284 -rwxr-xr-x 1 jim staff 3680 Mar 3 22:11 files/files.p3 sunsys>
In the above example, we create a symbolic link to the file
files/files.p3 called flink. Taking a look at the
flink, we see that the ls -li flink output
properly identifies flink as a symbolic link with an "l" in
the left-most column of the mode field. Also, the symbolic link has
a different inode number, 5651, than the file it is linked to,
files.p3, inode number 11284.
Solaris provides "fast" symbolic links. Remember, every file in the file system has a corresponding inode. The file's inode contains, among other things, two arrays used to point to the data blocks that contain the body of the file (the file's actual data). The first array, called ic_db, has 12 locations for storing disk block addresses. The second array, ic_ib, is for indirect addresses (blocks that contain pointers to blocks) and has three locations. Since a disk block address occupies four bytes, the combined space available in both arrays is (12 x 4) + (3 x 4) = 60 bytes. Both arrays are contiguous in the inode, so the 60 available bytes is addressable from the first array's location. The actual size Solaris allows for a fast symbolic link is 56 bytes, allowing room for a null terminator on the path name stored.
When a symbolic link is created, the system checks to see if the link size, the size of the character string that represents the link name (the pathname), is 56 bytes or less. If it is, the link name can be stored right in the inode in the space allocated for the disk block address arrays. This speeds up symbolic link references considerably because the kernel does not have to traverse a disk address pointer and fetch a disk block to get the link name -- it will get the name from the inode. The kernel maintains a flag field in the inode. One of the possible flag bits, IFASTSYMLNK, is used to indicated that the file described by the inode is a fast symbolic link. The file mode field in the inode, where the type of file is stored, will be IFLNK, which identifies the file type as a symbolic link. Remember, not all symbolic links are fast symbolic links; the pathname must meet the aforementioned size criteria. That's why the flag is needed.
Symbolic links are used extensively by the core Solaris system in the device name space. All the files under the /dev directory are actually symbolic links to the character and block device special files located in the /devices directory. Symbolic links have other practical uses. We use them often in database installations. Creating symbolic links to the actual devices that hold the database objects allows for using descriptive names (e.g. /oracle/dbdevices/index1_dev) to describe what's actually on the device. It also makes it easier to make changes to the underlying storage without having to recreate new device names for the database. You simply tell the database about the link names and change what the link points to if you need to alter the database storage (e.g. move some data from a RAID 5 volume to a RAID 1+0 volume).
That concludes our discussion of file types. The remaining files will be discussed in a future column that focuses on the file and its associated file system. Sockets, for example, now are implemented on sockfs, the socket file system. Named pipes, or FIFOs, are implemented on the fifofs and use the kernel STREAMS infrastructure.
|
|
|
|
|
Bits is bits
Let's now turn our attention to another aspect of files in Solaris
that often raises questions: access modes, file flags, and the
sticky bit.
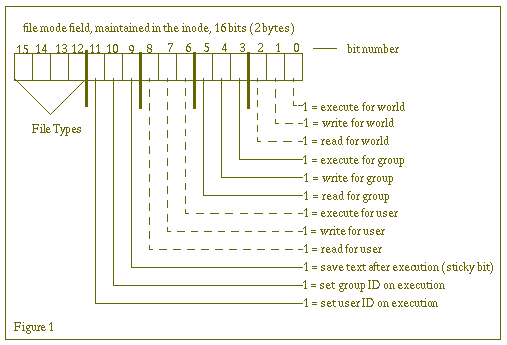
File modes are maintained in a field in the file's inode, generically
referred to as the mode field, and use various bit
combinations to identify the type of file, access permissions to the
file, and do other miscellaneous things (See Figure 1). This is
why, when we do a long file listing (ls -l command), the file
types, permissions, set uid, set gid, and sticky bit are all grouped
together in the far left-hand column of the ls -l output. All
this information is maintained in the same inode structure member,
so the kernel simply walks through the bits, displaying the
appropriate information based on which bits are set and which are
not.
|
ufs_setattr() (set attributes) ensures inode updates are done.
| File Type | Character |
|---|---|
| Named Pipe (FIFO) | p |
| Character Device Special | c |
| Directory | d |
| Block Device Special | b |
| Regular | - |
| Symbolic Link | l |
| Door (2.6 and beyond) | D |
| Socket (2.6 and beyond) | s |
We already discussed file types -- what the possible file types are and how they are represented in the left-most column of a long listing. The kernel uses four bits of the mode field. Bits 12 through 15 describe the type of file (the table to the right here shows a list of possible file types and the characters used to describe them). The remaining 12 bits are used to define the access modes to the file, some possible execute actions, and the sticky bit. The access modes are pretty straightforward, so we'll review them briefly here.
For a given file, regardless of the type, we can potentially do one of three things: read the file, write the file, or execute the file. Permissions are maintained for three possible users: the owner of the file, the group the user belongs to, and everyone else (typically referred to as "other" or "world" meaning the rest of the world). Every user on a Solaris system has a user ID (uid) and group ID (gid) that is established when the user's account is created. This information is referred to as the user's credentials, and is maintained in a data structure, the credential structure, that is embedded in the process structure. Remember, every operation you attempt on a file will be initiated from within a process, either something executed explicitly from the command line, or from the user's shell.
The credential structure has fields for a user's real uid
and gid, and effective uid and gid. An effective ID comes
into play if a user executes a file that has either setuid
or setgid bits set, which effectively alter the uid or gid
of the user during the execution of the file (more on this in a few
minutes). When a user attempts to do something on a file, the user's
ID credentials are checked against the file permissions. If the
operation is allowed, the system performs the requested I/O (read or
write) or executes the file.
The behavior for directory files is a little different than it is
for regular files. Read and write permissions allow you to read the
contents of a directory and create files in a directory,
respectively. Write also allows for deleting files in a directory.
Execute permissions affect a user's ability to cd(1) to
the directory or access the files in the directory for the purposes
of reading, writing, or execution. For example, if permissions where
such that you had read and write on a directory, but not execute,
you could list the files in the directory (ls
directory_name), but you could not make the directory your
current working directory, which is what happens when you cd
directory_name. Simply put, without execute permissions to a
directory, all you can really do (potentially) is list the files.
The kernel checks file access in a hierarchical fashion when a user attempts a file operation. First, a check is made to determine if the effective uid of the process is root. If it is, permission is allowed. Next, if the uid of the process matches the uid of the file owner, the owner mode bits allow for the attempted operation. If not, the gid of the process is matched against either the group the file belongs to or one of the supplementary gids (other groups that the user belongs to). If there's a match, the group mode bits are checked again to determine if the operation is allowed. Finally, if it's not root, a uid match, or a gid match, the system checks the mode for the rest of the world (other) and determines whether or not to allow the operation.
Files in Solaris support an additional security feature, access control lists, or ACLs. ACLs provide a method of defining finer-grained permissions for access and execution of files, above and beyond the traditional mode bits discussed above. We will cover the implementation of ACLs in Solaris in part four next month.
The
Here's another example of using
These are the types of applications that make
The mode bit for
Mandatory locking is enforced by the kernel. When the UFS read or
write code is entered, the file mode is checked to determine if
mandatory locking has been set for the file. If it has, a
The implementation of file locking in Solaris is basically driven by
the
It's up to the programmer to set the lock type, F_RDLCK for shared
or F_WRLCK for exclusive in the l_type field. The l_whence field
provides a method of having the l_start field offset from the
beginning, current position, or end of the file. The l_len is the
number of bytes from the offset to lock. Reference the
What's the sticky bit?
The sticky bit in Solaris affects different file types in different
ways. For simple text files, it basically has no affect. For
directories, it provides an additional level of security for
non-root users that do not own the directory file. If the directory
has the sticky bit set, the user must own the directory or the
target file in order to remove or rename a file in it, whereas
without the sticky bit set on the directory file, a user can remove
or rename the file in the directory even if they do not own the file or
have write permission to it, as long as they have write permission
to the directory.
Put another way, removing a file from a directory requires the user to
have write permission for the directory, but not necessarily write
or ownership of the underlying file. With the sticky bit set
for the directory, the user would not be allowed to remove the file
under the same set of conditions unless the user owned the
directory, owned the target file, or had write permissions to the
target file.
As far as the sticky bit and executable files go, Solaris no longer
implements the traditional "save-text-in-swap" functionality that
originated with the sticky bit. Again, with the natural evolution of
the virtual memory system design, much faster disks, shared object
libraries, and memory page locking capability, this type of
functionality is somewhat dated.
Solaris does, however, use the sticky bit for one other case. For swap
files that are created using the
Readers should reference the
That's it for part three. We'll continue with files and file systems
next month. On the short list for coverage are 64-bit files, flags,
ACLs, FIFOs, sockets, and socketfs, and a detailed discussion of
UFS (not necessarily in that order!)
Thanks for staying with us on what I originally thought would be a one-
or maybe two-part topic.
Resources
About the author
If you have technical problems with this magazine, contact
webmaster@sunworld.com
URL: http://www.sunworld.com/swol-04-1998/swol-04-insidesolaris.html
setuid and setgid bits provide the
ability to have a user execute a file that requires permissions to do
things that the user may normally not have. The most common example is
the Solaris passwd(1) command. In order for users to
change their passwords, they must be able to write to the
/etc/passwd and /etc/shadow files. Obviously, it
would be a serious security hole to leave these files writeable by
anyone. For this reason, the /usr/bin/passwd(1) command is a
setuid and setgid file, which means that when
the command is executed, the user's effective uid and gid become that
of the file, which in this case is root (user) and sys (group). Thus,
the setuid and setgid mode bits tell the
system to alter the uid and gid of the user executing the file to that
of the file they wish to execute. Once execution has completed, the
user's uid and gid are restored to whatever they where prior to
executing the file. Note that in order for the file owner to set the
setuid or setgid mode bits, the file must be
executable first (the execute mode must be true for the corresponding
setid bit: user execution for setuid and
group execution for setgid). As I said, there are 16 bits
(two bytes) available for the file modes, but a long listing via
ls -l displays only nine of these. Therefore, depending on
the file mode, the system will alter what appears in a particular mode
field in the output. For setuid and setgid, a
lowercase s appears where the execution bit is normally
displayed. For executable files that are not setuid or
setgid, the familiar lowercase x appears.
setuid (the lefthand column represents line numbers used in the annotation that follows).
1 fawlty> setfdlimit 10000
2 WARNING: setfdlimit open files may not work as expected
3 Setting Open FDs to 10000
4 setfdlimit[17]: ulimit: exceeds allowable limit
5 64 open files set
6 fawlty> su
7 Password:
8 # chown root setfdlimit
9 # chmod 4755 setfdlimit
10 # ls -l setfd
11 -rwsr-xr-x 1 root tech 312 Mar 17 16:54 setfdlimit
12 # exit
13 fawlty> setfdlimit 8192
14 Setting Open FDs to 8192
15 8192 open files set
16 fawlty> setfdlimit 10000
17 WARNING: /bin/ksh open files may not work as expected
18 Setting Open FDs to 10000
19 10000 open files set
20 fawlty>
setfdlimit is a shell script that does some rudimentary checking and
is used to increase the number of open files a user can have. In
order to circumvent the hard limit in Solaris, one needs to be root.
When I tried executing the program when it was owned by me (user jim),
I could not set my file descriptor limit to 10000 (lines 1 - 5). So, I
made myself root (lines 6 to 7), changed the owner of the file to
root (line 8), and changed the mode bits to read and execute for the
world and group, read, write, execute for the owner, and the setuid
bit (line 9). Next I checked the mode of the setfdlimit file and verified
the modes I set were in fact true for the file. I became user jim
again (line 12), and re-ran the program (line 13). This time it
worked, as I successfully bumped my fds to 8000. I tried it again (lines
16 to 19) and was able to bump fds up to 10000.
setuid and setgid useful. However, it should be obvious that setuid programs that make the user "root"
have security implications, and thus should be written and
implemented with care. Note also that in this example I used the
octal notation for the mode bits I wished to set for the file. The
chmod(1) command also takes ASCII text flags as command line
arguments for those users not familiar with octal representation.
setgid, bit 10 (see Figure 1), plays a dual role.
If bit 10 is set, and the group execute bit is also set (bit 3),
bit 10 provides setgid behavior as described above. However,
if bit 10 is set and bit 3 (group execute) is clear, this means that
mandatory locking has been set on the file. Solaris supports two
methods of file locking for regular files, advisory and
mandatory. Advisory locking requires that the developer
writing the file I/O code uses the proper interfaces for setting and
getting file locks. This is typically done with the fcntl(2) system
call. It is up to the program to follow the rules of checking for
locks prior to issuing a read or write to the file. It's analogous
to using mutex locks in multithreaded code; the kernel does not
prevent a process from grabbing a shared resource that is locked --
the code must explicitly check for the locks. The same applies for
advisory file locks.
chklock()
kernel routine is called to determine if the requested file
operation is allowable. The kernel will return an EAGAIN error to
read(2), write(2), or fcntl(2) if the requested I/O is not allowed due to mandatory locking (this is not a complete list of all the possible system calls that could result in such an error return).
fcntl(2) system call. Solaris provides for shared or exclusive
locks, and the user defines how much of the file to lock by
establishing a starting offset value in the file and some number of
bytes from the offset. The programmer must set up an flock
data structure to be passed in the fcntl(2) system call:
struct flock {
short l_type; /* lock operation type */
short l_whence; /* lock base indicator */
off_t l_start; /* starting offset from base */
off_t l_len; /* lock length; l_len == 0 means
until end of file */
long l_sysid; /* system ID running process holding lock */
pid_t l_pid; /* process ID of process holding lock */
}
fcntl(2) manual
page for more information on doing file locking in code. A library
routine, lockf(3C), is also available to use for file locking. It is simpler to use, but not as flexible as fcntl(2).
Finally, we get to the sticky bit, which is bit 9 in the inode's
file mode field. The sticky bit originated as a means of telling the
operating system to keep the text portion of an executable file
available on the swap device if it had to be moved out of physical
memory due to space constraints. It provided a method of keeping
commonly used executable text on the faster swap device so the
system could retrieve the pages faster if they were needed again
after being paged out.
mkfile(1M) command, Solaris sets a
flag in the vnode that identifies the file as a swap file. This flag
instructs the kernel not to cache this file in the page cache (because
it's a swap file, it's already in memory1).
chmod(1) and chmod(2)
manual pages for information on how to set file modes and descriptions of
the various mode fields.
![]()
http://www.sun.com/sunworldonline/swol-02-1998/swol-02-insidesolaris.html
http://www.sun.com/sunworldonline/swol-03-1998/swol-03-insidesolaris.html
http://www.sun.com/sunworldonline/common/swol-backissues-columns.html#insidesolaris
http://www.amazon.com/exec/obidos/ISBN=0130981389/sunworldonlineA/
http://www.amazon.com/exec/obidos/ISBN=0131019082/sunworldonlineA/
Jim Mauro is currently an area technology manager for Sun
Microsystems in the Northeast area, focusing on server systems,
clusters, and high availability. He has a total of 18 years industry
experience, working in service, educational services (he developed
and delivered courses on Unix internals and administration), and
software consulting.
Reach Jim at jim.mauro@sunworld.com.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Last modified: