Fiddling around with files, part oneThis month, we address one of the most frequently asked questions about Solaris, "How many files can I have open?" We'll examine the file interfaces in Solaris, how the kernel manages open files, and what the limits are and why they exist |
February 1998 |
Everyone who touches a Solaris system (or any Unix system) does file I/O, either implicitly as an end user, or explicitly as an application developer, systems programmer, or systems administrator. The ubiquitous nature of file I/O in Solaris creates a constant flurry of questions about dealing with files. How many files can I have open at any point in time? Per user? Systemwide? How do file permissions work? What does the "sticky bit" do? This month, we'll get inside the implementation of files in Solaris with an eye to answering the above questions and more. (2,600 words)
|
Mail this article to a friend |
![]() rom
its inception, Unix has been built around two fundamental entities:
processes and files. Everything that is executed on
the system is a process, and all process I/O is done to a
file. File I/O takes the form of intuitive read and write
operations to a file in the file system, and more abstract forms, as in
the implementation of device special files (for I/O to hardware
devices) and the process file system (ProcFS), which allows for reading
and writing process information using file-like interfaces and
semantics.
rom
its inception, Unix has been built around two fundamental entities:
processes and files. Everything that is executed on
the system is a process, and all process I/O is done to a
file. File I/O takes the form of intuitive read and write
operations to a file in the file system, and more abstract forms, as in
the implementation of device special files (for I/O to hardware
devices) and the process file system (ProcFS), which allows for reading
and writing process information using file-like interfaces and
semantics.
Solaris, as with other modern implementations of Unix, follows this convention, employing traditional file abstractions for the purpose of reading and writing files and doing device I/O. Some things haven't changed much over the years, such as the notion of file modes, where permissions to read, write, and/or execute a file are defined. A subset of the file mode, called the sticky bit, has changed only somewhat over time, while other things have changed a great deal. For example, the types of files known within a file system have increased from the original regular, directory, and device special files to include file types such as named pipes, symbolic links, and sockets.
|
|
|
|
|
Kernel file table and open file limits
There are several things that can potentially affect the per-process
limit and the number of open files Solaris can maintain at any one
time. We'll start with a system view, looking at the kernel file
table.
Every opened file in a Solaris system occupies a slot in the system file table, defined by the kernel file structure:
typedef struct file {
kmutex_t f_tlock; /* short term lock */
ushort_t f_flag;
ushort_t f_pad; /* Explicit pad to 4 byte boundary */
struct vnode *f_vnode; /* pointer to vnode structure */
offset_t f_offset; /* read/write character pointer */
struct cred *f_cred; /* credentials of user who opened it */
caddr_t f_audit_data; /* file audit data */
int f_count; /* reference count */
} file_t;
The fields maintained in the file structure are, for the most part,
self-explanatory. The f_tlock kernel mutex lock protects
the various structure members. These include the f_count
reference count, which lists how many threads the file has opened, and
the f_flag file flags, which maintain information such as
file locking (read and write locks for application programs, used to
manage I/O to the same file by multiple threads or processes). It also
protects the close-on-exec flag, which instructs the system to close
the file when the process executes an exec(2) system call.
(We'll be covering file flags in more detail later in the column. You
can reference the fcntl(2), fcntl(5), and
open(2) man pages for additional information on file
flags.)
Early versions of Unix implemented the system file table as a static array, which was initialized at boot time to some predetermined size. If the required number of open files systemwide exceeded the size of the file table, file opens would fail. When this happened, the system had to have the tunable parameter that defined the file table size increased, a new kernel needed to be built, and the system rebooted.
Solaris implements kernel tables as dynamically allocated linked lists. Rather than populate and free slots in a static array, the kernel allocates file structures for opened files as needed, and thus grows the file table dynamically to meet the requirements of the system load. Therefore, from a pure systemwide standpoint, the maximum size of the kernel file table, or the maximum number of files that can be opened systemwide at any point in time, is limited by available kernel address space and nothing more. The actual size the kernel can grow to depends on the hardware architecture of the system, as well as the version of Solaris the system is running. Table 1 provides a matrix with the kernel address size limits for a given hardware architecture and Solaris release. By way of a data point, I've never seen Solaris run out of kernel address space due to file table growth.
| sun 4m | sun 4d | sun 4u | |
|---|---|---|---|
| Pre Solaris 2.5/2.5.1 | 128MB | 256MB | N/A |
| Solaris 2.5/2.5.1 | 256MB | 576MB | 4GB |
| Solaris 2.6 | 256MB | 576MB | 4GB |
The Solaris kernel actually implements kernel memory allocation through an object caching interface. This was first introduced in Solaris 2.4 in order to provide a faster and more efficient method of allocating and de-allocating kernel memory for objects that are frequently allocated and freed. File table entries are a good example of this because the volume and rate of file opens and closes can be quite high on a large production server. A detailed explanation of the kernel memory allocator and object cache interface is beyond the scope of this month's column. We'll address it in a future installment.
The system initializes the file table during startup, by calling a
routine in the kernel memory allocator code that creates a kernel
object cache. Basically, the initialization of the file table is really
the creation of an object cache for file structures. The file table
will have several entries in it by the time the system has completed
the boot process and is available for users, as all of the system
processes that get started have some opened files. As files get
opened/created, the system will either reuse a freed cache object for
the file table entry or create a new one if needed. You can use
/etc/crash to examine the file table (as root):
# /etc/crash dumpfile = /dev/mem, namelist = /dev/ksyms, outfile = stdout > file ADDRESS RCNT TYPE/ADDR OFFSET FLAGS f5951008 1 SPEC/f609246c 0 read write f5951030 1 FIFO/f5ecb800 0 read write f5951058 1 SPEC/f60589b4 0 read write ... >quit #
I didn't include the entire listing because it's quite long. ADDRESS is the kernel virtual memory address of the file structure. RCNT is the reference count field (f_count). TYPE is the type of file, and ADDR is the kernel virtual address of the vnode. OFFSET is the current file pointer, and FLAGS are the flags bits currently set for the file.
You can use sar(1M) for a quick look at how large the file table is:
# sar -v 1 SunOS sunsys 5.6 Generic sun4m 01/13/98 22:46:51 proc-sz ov inod-sz ov file-sz ov lock-sz 22:46:52 66/4058 0 2035/17564 0 407/407 0 0/0 #
In this example, I have 407 file table entries. The format of the sar
output is a holdover from the early days of static tables, which is why
it is displayed as 407/407. Originally, the value on the
left represented the current number of occupied table slots, and the
value on the right represented the maximum number of slots. Since the
file table is completely dynamic in nature, both values will always be
the same.
That pretty much addresses the maximum number of systemwide open files question. Now we'll get into the per-process limits and what they're all about.
Per-process open file limits
Every process on a Solaris system has a process table entry with an
embedded data structure, historically called the user area or
uarea. Each process maintains its own list of open files with
a pointer rooted in the uarea called u_flist. The
u_flist pointer points to uf_entry
structures, which look like this:
struct uf_entry {
struct file *uf_ofile;
short uf_pofile;
short uf_refcnt;
};
The uf_entry structure contains a pointer to the file
structure (uf_ofile) -- a uf_pofile flag field used by the
kernel to maintain state information that the operating system needs to
be aware of. The possible flags are FRESERVED, to indicate that the
slot has been allocated, FCLOSING, to indicate that a file-close is in
progress, and FCLOSEXEC, which is the user-settable close-on-exec flag.
It also maintains a reference count in the uf_refcnt
member. Remember, Solaris is a multithreaded operating system that
supports multithreaded applications that can run on multiprocessor
systems. Multiple threads in a process can be referencing the same
file, which makes a per-process reference count handy. For example, say
you need to prevent one process from closing a file that another
process is reading; state flags, used in conjunction with mutex locks
(which protect the setting of the state flags), will ensure that
multiple processes hitting the same kernel code path do not
The u_flist pointer is implemented as an array pointer,
where the open file list is an array of uf_entry
structures. The kernel allocates the required structures dynamically,
as processes open files. A process uses one uf_entry
structure for each open file, and the kernel does allocation in
increments of 24. When a process first comes into existence, the
number of available uf_entry structures is set to 24. When
the available entries all get used, subsequent allocations are done in
chunks of 24. Since the uf_entry structure is only 8 bytes
in size, virtual address space limits are definitely not a concern
here. Consider, for example, that even 124,000 open files would only
require 1 megabyte of process VA space to store the open file list. At
a system level, each file structure is 40 bytes, so 124,000 open files
would require about 5 megabytes of kernel address space for the system
file table. Figure 1 shows the big picture.
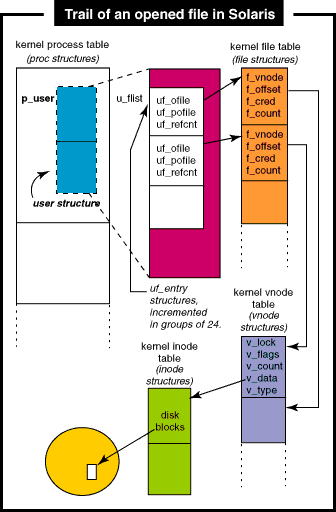
|
ulimit(1) command if you're using the
Korn shell (/usr/bin/ksh) or Bourne Shell (/usr/bin/sh). Use
limit(1) if you're using the C shell (/bin/csh).
sunsys> ulimit -a time(seconds) unlimited file(blocks) unlimited data(kbytes) 2097148 stack(kbytes) 8192 coredump(blocks) unlimited nofiles(descriptors) 64 vmemory(kbytes) unlimited
The above example was executed under the ksh. The limit we're
interested in is displayed as nofiles(descriptors), which
has a default value of 64 open files per process.
The system establishes default values and maximum values for each of
the resources controlled by the resource limits. For each of the seven
resource limits defined, there is a rlim_cur (current
resource limit), which is the default value, and a
rlim_max (maximum resource limit), which is the
system-imposed maximum value for the resource. In Solaris 2.5.1 and
2.6, the hard limit value set by the system is 1,024. You can reset the
limits in the /etc/system file as follows:
set rlim_fd_cur = 1024 set rlim_fd_max = 8192
If you put the above in the /etc/system file, users will
have a default of 1k open files and be able to set their own
limit up to 8k. If you're superuser (root), you can go beyond
the max limit to some arbitrarily high value.
Here is some real output to drive this point home (note the annotations
between /* and */):
fawlty> ulimit -n /* System name is "fawlty." Check open
file limit with ulimit(1) */
64 /* Output from ulimit, default value of 64 */
fawlty> of /* Run a program called "of," which is a `C'
program that opens files in a loop until the
open(2) call returns an error. It counts the
number of successful opens, and outputs that
value */
61 File Opens /* Output from "of" program. 61 files opened */
fawlty> ulimit -n 1024 /* Change my open file limit to the max, 1024 */
fawlty> of /* Run the "of" program again */
1021 File Opens /* 1021 files opened this time */
fawlty> su /* Make myself root */
Password:
# ulimit -n /* Check the open file limit at root */
1024 /* It's 1k */
# ulimit -n 10000 /* Set my open file limit to 10k open files */
# ulimit -n /* Check it, to make sure */
10000 /* Looks good */
# ./of /* Run "of" as root */
9997 File Opens /* 9,997 file opens */
# ulimit -n 100000 /* Let's try 100k */
# ulimit -n /* Took it */
100000
# ./of /* Run the "of" program */
99997 File Opens /* Son-of-a-gun. 100k open files. */
#
As illustrated, we can use the appropriate shell command to tweak our
open file limit to either the max limit for non-root users or some
arbitrarily high value as root. The "supported" limits are up to 1k open files per user in 2.5.1 and 64k open files in Solaris 2.6. The example
above was done on a 2.6 system, but I ran the same test on Solaris
2.5.1, and it was successful. An alternative method of manipulating
resource limits is using the C language interfaces. Solaris provides
two system calls, setrlimit(2) and
getrlimit(2) for setting and getting resource limits
programmatically. See the man pages for more.
In case you're curious, the reason the number of open files was always the max value minus three is because every process has three open files as soon as it comes into existence: stdin, stdout, and stderr(standard input, output, and error), which represent the input, output, and error output files for the process. Also, for the non-programmers among you, here's what the of program source code looks like:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
main()
{
int count=0, err;
while (err != -1) {
err=open("/dev/null",O_RDWR);
if (err != -1)
count++;
}
printf("%d File Opens\n",count);
}
So the rule of thumb here is that on a per-process basis, a process can
only open up to rlim_fd_cur files, whatever that value is.
You can determine that by using the ulimit(1) or
limit(1) command, depending on which shell you're using.
As root, you can bypass the resource limit check and set the open
process limit to theoretically 3 billion (signed int data type max
value). Obviously, you would never get anywhere near that amount
because you would run out of process virtual address space for the
per-process file structures (uf_entry) that you need for
every file you open. Fortunately, we never encounter situations where
a requirement exists that needs that many files opened. We do, of
course, see installations more and more where per-process open files go
into the thousands, and even tens of thousands. The support issues can
get tricky here, so I always suggest working with your local service
organization if you have a production environment that requires more
than the documented limits.
We now have an understanding of the main structures involved in open files and what the open file resource limit is all about, so this seems like a good place to break. We'll finish up next month. In March, we'll cover how the API you use can affect your open file limits. We'll also get into file flags and talk a little about the sticky bit.
See you next month.
![]()
Resources
About the author
Jim Mauro is currently an area technology manager for Sun
Microsystems in the Northeast area, focusing on server systems,
clusters, and high availability. He has a total of 18 years industry
experience, working in service, educational services (he developed
and delivered courses on Unix internals and administration), and
software consulting.
Reach Jim at jim.mauro@sunworld.com.
|
|
|
|
If you have technical problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/swol-02-1998/swol-02-insidesolaris.html
Last modified: