The new big iron
By Hal Stern
You can't avoid the popular notion in the computing industry that the mainframe is near death. Certainly, deployment of considerably less-expensive and technologically more-adept and -adaptable midrange and high-end Unix servers is a powerfully attractive alternative. But while Unix servers (and even some PCs) offer more MIPS than their mainframe predecessors, not all Unix servers are large enough to handle the data-management demands of even a moderately sized mainframe application. Strategic applications that crunch tens of terabytes of data on line are simply beyond the scale of any single Unix machine.
The key issue for Unix system architects, therefore, is scalability: What do you do when your application needs to grow beyond the capacity of a single system? How can you scale the environment with the predictability and control offered by today's data center? The standard "big iron" solution is to add more mainframes, modify resource allocations on those hosts, and tie the world together with SNA networks. A similar trend is underway in the Unix camp under the banner of cluster technologies. Unix clusters range from a few high-end database servers to hundreds or even thousands of desktops linked together in a high-performance compute farm that can rival a supercomputer's power.
Addressing questions of scale requires a brief review of the benefits and drawbacks of clustering technologies. If you can provide a high-performance environment with the reliability and ruggedness that the data center demands, you'll make everyone happy. The key to achieving that bliss through clustering is in making sure your applications fit the computing model. We review the software components needed for clustering, and cover issues of application separability and host scalability, touching on some strategies for managing data on multiple nodes. A look at the management issues and costs associated with Unix server clusters rounds out the evaluation roadmap.
Take two, they're small
Clustering is achieved primarily through software that creates a shared-resource space out of multiple machines. The shared space may include memory, disks, or disjointed application images (see sidebar Ganging up on the problem). Hardware groupies will note that shared-memory clusters and massively parallel machines use special-purpose hardware to share resource pools. In shared-disk and shared-nothing clusters, the connections are general-purpose networking hardware, which is coming more into vogue. In either case, the software used in the cluster environment determines the application impact of addressing multiple hosts.
Applications on large-scale compute clusters almost always "feel" the cluster design through task-distribution software. Tymlab's LoadBalancer, IBM's LoadLeveler, HP's TaskBroker, and Platform Computing's Load Sharing Facility distribute individual compute jobs to the least-loaded node in a very loosely coupled cluster. Fine-grain, distributed programming tools like Scientific Computing Associates' Linda, the publicly available Parallel Virtual Machine (PVM), and High Performance Fortran let developers thread applications for parallel execution on the elements of a computer cluster, whether they are individual CPUs in shared memory, symmetric multiprocessors (SMP), or networked uniprocessor hosts.
Oracle's Parallel Server runs on a shared-disk cluster, in which two or more uniprocessor or SMP servers simultaneously process queries and transactions on a single copy of the Oracle database. The single database image is spread across a shared and often redundant disk-storage system, so that every host has equitable access to every disk block, and every disk block is replicated for higher levels of data integrity. Although the shared-disk cluster nodes run independent copies of the operating system, each has a single database view to applications. Database architectures tailored to shared-nothing clusters, like Informix XMP and Sybase Navigation Server, also hide the machine boundaries from users and application developers, but each machine has its own private view of local disk resources.
Separation of powers
Regardless of the cluster configuration, why would you want to deal with more than one host in the first place? SMP systems boast shared address spaces, single-data and filesystem views, and anywhere from 16 to 64 CPUs. With that much horsepower, why scale out of the box? Reliability and performance are the primary motivators.
Consider this simple case: A SPARCcenter 2000 with 16 CPUs delivers 500 megabytes per second of sustained CPU-to-memory bandwidth, or a bit more than 30 megabytes per second per CPU. Divide the same compute horsepower into eight dual-CPU SPARCstation 20s and the size of the memory pipe grows: Each desktop can sustain 130 megabytes per second to memory, so you more than double the total memory bandwidth to greater than one gigabyte per second. Compute-bound jobs that move large datasets to and from memory live and die by memory bandwidth, so they can benefit enormously from a multiple-host approach.
A similar scalability argument works for I/O systems. As you add hosts, you add capacity through multiple I/O buses, much the same way you might add channels to a mainframe to scale up its I/O system.
Scalability and reliability are often dual problems. As you make a system larger it is more prone to failure due to the additional disk, memory, and CPU-cache units. Clustering deals with this trade-off by isolating the hardware units prone to failure and by running multiple copies of the operating system. (Assuming you can't dismiss all of your vendors' operating system and database bugs, and that your own application code hasn't been tested under infinite load and user scenarios, you can rest assured that you will eventually lose a system to a software problem.) Multiple hosts also provide the basics for high availability, and by doing less on each host, you may reduce the complexity to the point where you improve the reliability of the separated, smaller systems.
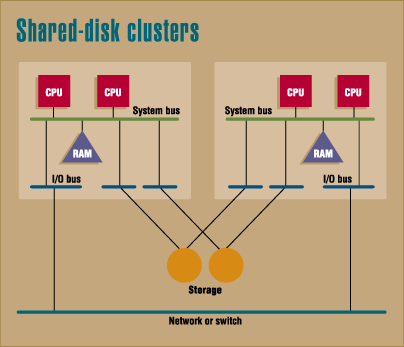
Shared-disk clusters attach the disks to I/O buses on more than one system. They usually come packaged as server hosts for parallel-database systems.
Here's a final motivation for spreading your workload across multiple systems: It lets you roll out minor software revisions in a controlled, minimal-impact fashion. Let's say you are running forty different in-house applications on version x of the database. A bug in one application requires that you upgrade to version x+1. Doing the upgrade requires significant retesting, minor porting work, and possibly some amount of unscheduled downtime. With a cluster, choose one machine to upgrade, and isolate all of the upward-revision applications on that host. The hard task of clustering is apportioning applications to servers so that you balance the peak and average loads of each. With several hundred applications to distribute, the combinations are nearly infinite and you'll have to approximate a best-case machine allocation. The key factors in load distribution remain to be the degree to which you can slice your application, and the effects of spreading those slices out.
There are downsides to clustering. Shared-disk clusters, for example, have limited data scalability. Since each machine must access all of the data, the total size of the database is bound by the disk capacity of a single node. You can throw more computing horsepower at the problem and thereby improve transaction throughput, but you won't be able to increase your database's size by moving to a cluster. Of course, the measure of availability provided by multiple hosts is a point in favor of shared-disk clusters.
Loosely coupled machines do a better job of scaling for some jobs, but ganging together multiple hosts isn't a magic solution, either. You're still faced with the problem of splitting your job across the hosts. The larger aggregate memory pipe only functions properly when it's not constricted by a relatively tiny network. We'll come back to separability criteria, because they are frequently the defining issues in cluster evaluations.
Unnecessary zoom
By now, the fundamental questions of cluster analysis should have germinated: Just how far can you zoom in on your data? Should you build a fine-grained cluster out of neat stacks of blazingly fast desktops, or a coarse-grained, shared-nothing or shared-disk cluster from a few well-configured, scalable database engines? The first step is to evaluate the demands your application will place on the cluster. Will it need a single data view, or can you make the application handle several databases? Will you have to worry about selecting one machine out of many, and if so, can your application make an informed choice? Most importantly, how big a cluster will you need, and what are your performance goals in that target environment?
All these questions center around issues of separability. As you chase your databases' transactions wielding Occam's razor, what about their independence? Can they be executed in parallel, or are there serialization constraints requiring a particular order of completion? Posting dividends to bank accounts is a prime example of highly independent transactions, since every account could be updated in parallel. If you can spread your account data across all of the machines in the cluster, then this application scales well. At the other end of the spectrum, a picking application such as on-line order entry, order fulfillment, or stock trade execution isn't as conducive to separation because one or more key database rows get involved in almost every transaction.
Aggregations or a summary of rows in the database can be parallelized by producing partial products on groups of rows and then merging the results. Table joins fall into a middle ground, depending upon the number of rows that need to be selected from each table. If you are only moving a few rows across the cluster connect, or through the host-disk interconnect in a shared-disk arrangement, then you'll see good performance. If you need to do full Cartesian products of tables, however, you may end up with a table that is too big for the individual cluster node to handle without excessive paging. In general, the more contention you have for any part of the database, the less well suited it is for a cluster. The distributed locking overhead needed to maintain consistency and the data migration between nodes in the cluster impair scalability. Applications that are read-mostly, like decision support, tend to fit well in the cluster environment, while those that are update- and insert-intense, like on-line transaction processing, stress the distributed-locking and data-transport mechanisms.
Compute clusters have a related scalability constraint. Will one computation need data from the dataset of another? Or can it operate on your data in a grid, minimizing the number of data items that get passed between its cells? Many mechanical engineering problems, such as fluid flow, fit the grid model. In a compute cluster optimized for a flow problem, multiple hosts work on one or more cells, exchanging boundary data with neighboring hosts in the virtual grid. If the time required to exchange the data is small compared to the time spent processing each grid's elements, the problem fits the multiple-host model well. On the other hand, simulation codes that require access to every datapoint during every iteration of the model don't parallelize across clusters well, although they can usually be run on large, shared-memory SMP machines with the right parallelizing compiler technology. The gating factor is the overhead of data communications between cluster nodes.
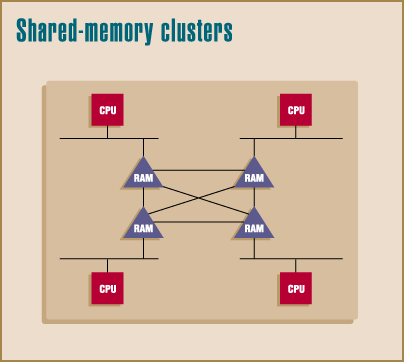
Shared-memory clusters require high-speed mesh or crossbar interconnect between elements, with a front-end system typically performing I/O for the parallel-CPU nodes.
It's also critical to look at both the sustained throughput of the node interconnect as well as its latency under the expected load. If your application passes short, 100-byte messages between a few cluster nodes, you'll fare better with Ethernet than with FDDI connecting the nodes, because Ethernet has a lower latency with few hosts and small packets.
Shuffling a megabyte of boundary data, though, suggests FDDI or larger pipes between the hosts. If cluster nodes use the network or a switch to exchange the results of I/O operations, then your total inter-host I/O operation count is limited by the switch bandwidth. Assuming you're using a 2-kilobyte database block, a 10-megabyte-per-second switch will handle no more than 5,000 random I/O operations per second -- about the peak you'd get from 100 SCSI disks. If you're doing sequential I/O, with the disks feeding the switch at 5 megabytes per second each, then even a 30-megabyte-per-second switch saturates with six disks. Unfortunately, those read-mostly applications best-suited for clusters also include those that rely on sequential full-table scans, which tax the cluster interconnect most heavily. Evaluate the way in which you access data because it will determine whether the cluster interconnect is a potential bottleneck.
Atomic forces
The node size in your cluster should reflect the atomic, indivisible unit of work that you expect to handle. Don't pick a node size that's too small for the nastiest subproblem, or you'll find that your cluster scalability goes into the red in a hurry. Compute clusters may benefit from many desktop, uniprocessor machines, provided they each have sufficient memory to keep the subproblems resident. Database clusters may require mid- or high-end servers to ensure that I/O traffic doesn't completely control the execution time for a typical transaction. If you're doing I/O between cluster nodes because a single node is too small, you've sacrificed many of the benefits of clustering.
Atomic node sizes are also shaped by the amount of data that you'll put on each system. Evaluating the scalability and atomic node size of a multiple-host solution requires careful thought about your transaction types, applications workflow, and management techniques. Can you slice your data into 1, 10, or 10,000 pieces? Strategies for creating data subdivisions include the following:
As you size your proposed cluster, be sure to consider the costs and operational aspects of the system. If you want both reliability and scalability from a multiple-machine solution, you'll need to put a rigorous management plan into place.
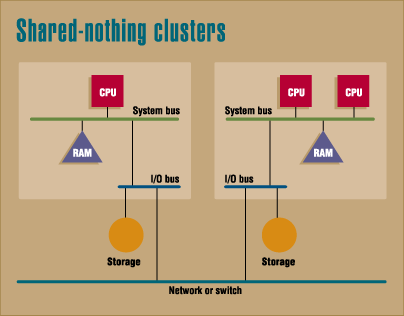
Shared-nothing cluster, typical of workstation "farms," boost aggregate system performance through loading sharing cluster-management software and coarse-grained multiprossing.
The new three Rs
A new commercial computing project deployed without a management plan is doomed to failure. Tools and procedures that work for single hosts don't magically extend to cover the clustered system. At the same time, new issues of availability and performance scalability surface with clusters. Plan a management strategy around the three Rs: Repair (recovery from backups or hardware failures), Reliability, and Redundancy in services.
Backup and restore become more difficult as you add machines, particularly if they all have live data on them. How will you pull data off of the machines in the cluster, and how long will it take to roll to tape? What is your restore strategy, and should part or all of the cluster fail? Can you restore the lost data on one or two cluster nodes, or do you have to rebuild all of the disks in the cluster?
In all clustered solutions, you need to keep the hosts consistent. What tools will you use for distributing applications, ensuring consistency in name services (so that applications agree on TCP/IP port numbers, for example) and host configuration? How hard will it be to do upgrades or install patches on multiple machines? Tied closely to the host-management issue is that of host reliability. What happens to your compute cluster if one or more of the hosts aren't available? How will you deal with network failures that segregate the cluster? Can you choose from a pool of machines, or are machine names hard-coded?
Large compute jobs often benefit from a restart capability. If you're cruising along at the 90 percent of completion point and one of the machines in the cluster fails, it's not pleasant to restart the entire job on all machines. If you've been checkpointing applications on each host, you can restart the failed subprocess on another machine, and minimize the impact of a single failure. (Checkpointing techniques are covered in this month's SysAdmin column.)
Also consider the goals of cluster scalability and reliability carefully. You may find that going from a 2-node to a 4-node database cluster buys you only another 10 percent in top-end performance. Is it worth doubling your expense for such a small gain? In a 2-node cluster, you risk running at only 50 percent of your peak capacity if one host fails. The 4-node cluster can survive up to three host failures and continue processing. Better still, it delivers 75 percent of its peak capacity after a single failure. If you run each machine at, say, 70 percent of peak capacity, you could survive a node failure in a 4-way cluster and see little variation in response time as the load on the remaining three machines increases to about 90 percent of their respective peaks.
One of the biggest costs you'll encounter will be enforcing change control as well as accountability and auditing measures on every node in the cluster. When you rely on homogeneity across hosts, disks, operating system configurations, and applications, and the slightest perturbation in network usage affects your throughput, you have to track every change made to every system with religious fervor. Hence, controlling the rate of change improves the reliability and quality of the solution.
As part of your reliability evaluation, think about security on the interconnect or network as well as host-oriented security. Are you distributing sensitive information over an exposed network? If someone breaks into your corporate network, can they watch the inner workings of your cluster without even having to login to one of its hosts? Be sure you can control all of the network or interconnect elements, enforcing security through checksums, encryption, or complete physical isolation from other network access points. Look at your reliability concerns, and choose a solution that meets the application and user requirements with a minimal set of moving parts.
Soft iron?
Recent failures of massively parallel vendors such as Thinking Machines and Kendall Square Research seem to bode badly for large-scale, fine-grained clusters. But large compute farm and database cluster successes have been achieved and many more are probably being quietly utilized to deliver high return to their owners. Large strategic investments are not frequently shared with the world until the technology becomes pervasive. Coarse-grained, loosely coupled clusters, on the other hand, already have an existence proof of their success: companies with several mainframes connected through SNA networks.
Multiple Unix hosts "clustered" with general-purpose network technology is the new paradigm that will complement and supplant the multiple-host, multiple-region mainframe model that dominates the data center today. Applying Unix system clusters to real-world, nontechnical applications remains a wide-open area as we define the meaning of "big" for the next generation of big iron.
![]()
About the author
Hal Stern is an area technology manager for Sun. He can be reached at hal.stern@sunworld.com.
Clusters come in three basic flavors: shared-disk, shared-memory, and shared-nothing (see the diagrams Cluster architecture). Digital's VAXcluster, now the OpenVMS cluster, ranks first in fame among fielded shared-disk solutions, and Digital has followed up on it with its OSF/1-based AdvantageClusters. All sport a single disk and filesystem view so that any machine in the cluster can access any file, regardless of its physical location. Most Unix vendors offer a shared-disk cluster product to support Oracle's Parallel Server option.
Shared-nothing designs loosen the coupling between systems in the cluster further than shared-disk designs. The clustered systems are attached via standard networks, or a private, high-speed switch, but they do not share memory or disk resources. Generally, these loosely coupled servers are used for large segmented address spaces, where a single application is spread over tens or hundreds of machines. Fine-grain clusters use desktops or uniprocessor servers, while coarse-grain clusters are built out of multiprocessing servers with higher-end I/O systems.
Shared-memory architectures are more complex, managing a single global address space across multiple machines. Typically, a mesh or cross-bar type switch connects processors to each other and their memory units, so that each CPU can see the memory of some or all of its neighbors. Fielded examples include the Connection Machine from Thinking Machines, the Paragon, and the nCube -- all of which have earned the "massively parallel" (MPP) title, surpassing the ranks of their clustered brethren in media attention. Many of the application partitioning and distribution rules apply to MPP machines as well, although MPP systems require that you slice your problem with the fineness and skill of a Benihana chef. Such exceptionally fine-grain parallelism is found mostly in scientific applications or single-instruction, multiple-data (SIMD) models where the same operation is performed repeatedly on a huge dataset.
If you have problems with this magazine, contact webmaster@sunworld.com
URL: http://www.sunworld.com/asm-12-1994/asm-12-big.iron.html
Last updated: 1 December 1994