![]()
I am terrible about New Year's resolutions, particularly the negative ones that start with "I will not" I'm usually engaging in the first proscribed activity by the time I've thought of three or four additional promises. I resolve about as well as a DNS server that was installed with a Christmas party hangover. I'm a much bigger fan of positive improvement goals: Tell me what to measure, how to measure it, and what constitutes improvement.
What works for people works for systems as well. This month, we'll go through the issues of defining performance and usage metrics. Appropriate time spans for measurement and high-value ratios for interpreting the results form the core of the discussion. Some attention to detail and accuracy completes the picture. You won't find suggested management techniques and courses of corrective action. Our goal is to highlight creative ways of looking at system performance.
One for good measure
Finding a single figure of merit for systems measurement is like finding a
single feature that defines the appeal of an automobile to a large range of
drivers. Measuring interactions between resources and events, positive and
negative, in reasonably complex systems requires creative crafting of a
few, concise metrics that describe those interactions. You don't need or
want complex measurements, which only mirror the obfuscation we're trying
to resolve. Jazz great Charles Mingus put it simply: "Anyone can take
something simple and make it complex. Taking something complex and making
it simple, that's creativity."
Start by looking at related units of management. Ratios are important because scalar values represent a resource-utilization point without any relation to the resource-consuming events. A network that is 90 percent loaded might be perfectly fine if it's handling point-to-point file transfers with low latency and few user complaints. Conversely, it could be perfectly awful for the NFS traffic of a dozen workstations. Relating load and latency or utilization and work type tells you much more than a single measurement.
Noticing that you're using 20 percent of the CPU doesn't mean anything until you know the kind of work that's using the cycles. If you're CPU-bound, then you have headroom to increase the workload by a factor of four or five. An I/O-bound job, however, that uses 20 percent of the CPU might be improved by adding disk spindles. As you increase the disk count and I/O load, to ease the bottleneck, you'll use more CPU to deal with the I/O setup, system calls, and interrupts from the additional work. You run the risk of morphing a disk problem into a CPU shortage. How do you know when relaxing one constraint pops another one into the foreground? Define the right relationships -- CPU time used per disk I/O tells you how much system time you eat up as you add disk load -- and measure with your tailored yardstick.
Isolate and measure those interactions that limit scalability. Can the CPU drive both the network and the disks in your server? Just clocking CPU utilization as a function of disk I/O doesn't allow for getting the data to or from the network. Even if the local disk subsystem is well served by the processor, the network interface might be cycle-starved. The sheer number of combinations of measurement variables is impressive, but only a few will tell you how you're doing and how you might improve.
Ratios: Toasters to children
Statisticians love to use ratios to express the most bizarre relationships
between people and their possessions. In theory, this helps marketing
masters identify those demographic segments with sub-average ratios of,
say, toasters to children. They find the area of weakness and promote the
wonders of toast until they bring the ratio for that segment back into
line. As silly and obvious as that seems, our example exhibits the first
good characteristic of a useful ratio: At least one variable must be
easily measured and related to your unit of work. Disk I/O operations,
transactions, NFS operations, or compile/debug sessions are fair units of
work because they are discrete, easily counted events. Be sure you can
control granularity of the denominator. That is, you shouldn't be able to
cheat by increasing the denominator and lowering a cost-oriented ratio,
showing false improvement. Bugs per line of code is a bad metric because
the code size can be inflated. Quality is the same but the metric says
you've made progress.
Complement your work-based variable with one you can control and that demonstrates improvement. The other half of the ratio should be a unit of cost or a unit of performance. Latency, response time, capacity, or utilization figures make good numerators because changes in their values reflect a change for the better or worse. The key is to find two values that are related during the course of running your workload. Summarizing Ethernet collisions per disk I/O won't tell you much, because not all Ethernet traffic involves disk I/O and vice versa. Be sure you're not measuring two totally independent sets of data points, where the changes in one don't affect the other, or the ratio degrades into a randomly scaled single figure of merit.
Those who are Lotus, SAS- or Minitab-enabled will recognize the problem as one of determining the correlation between two variables. Simply put, correlation tells you how much fluctuations in one variable are caused by variations in the other. Correlation, or r-squared, ranges from 0 (independent variables) to 1 (completely correlated). Highly correlated variables make for useful ratios because they measure the efficiency of the causal relationship. A ratio comprising two independent variables is not more useful than the time series of the variables outside of the ratio. One is not exerting influence on the other, so there is no information to be gleaned by looking at their relative values. Too much theory? Experiment with correlations by plugging streams of measurements into your favorite spreadsheet or statistics application, and see how much information those pretty graphs drawn by your network management tool are really telling you. The less correlated the variables, the more your 3-D graph can be replaced with a series of 2-D pictures.
Let's pick apart some sample ratios:
Transaction response time per disk capacity used. Do your
transactions run faster when your disks are only half full? Transaction
response time is probably a function of disk seek times, which may increase
as your disk fills up. You don't have to become I/O-bound to take notice of
a performance slip; just watch for the disk-capacity point at which you
start doing more long seeks than short, track-to-track ones.
Physical disk I/O per logical or expected disk I/O. The LADDIS benchmark does about 0.7 logical disk I/Os per operation, a number derived by multiplying the worst possible I/O load for an operation by its representation in the RPC mix. Count the actual number of I/O operations done using iostat or sar, and check the efficiency of your memory cache. The lower the ratio of physical to logical operations, the better your server is caching the workload. Compare the ratios for a group of servers and see if you can improve on those at the high end of the scale by shuffling filesystems or memory resources.
Collisions per packet size. Does network latency depend on the size of packets shuttled by the wire? Gathering the data for this one is hard, because you have to measure on the wire (with snoop, etherfind, or etherman) to get the packet size and on a few systems to count collisions. If you have to add a set of terminal servers to one of your networks, look for the one with the smallest collision-per-packet size ratio, because the telnet traffic from the terminal servers will add a large number of small packets to the selected network.
Problem plus/minus count per active user. Ever have one of those days when the problems pile up faster than you can solve them? Have the interruptions outnumbered the chances to mend crises by two to one? Take a page from the hockey statistics book and chalk up your plus/minus value: The number of things you fix minus the number that get put onto the task list (in hockey it's the number of goals your team scored minus the number that were scored against you while you were on the ice). Now graph your problem-resolution powers as a function of the number of users, and look for telltale patterns: Does your productivity fall off once there are 100 people on the network? Do you go into the red when your user census tops 200? This trivial arrival and dispatch model is graphic justification for more help.
Interval research
Knowing where to look is only half of the issue. To gather reasonable data
for your ratios, you need to know the right measurement interval.
Physicists live for instantaneous data, but they have precise scientific
instruments with which to measure acceleration, velocity, and mass. They
also have a penchant for the calculus needed to interpret the instantaneous
data. Enough higher math for one month. Computer systems' measurements are
neither as exact or short-lived as computer events, and the business events
that drive them tend to have lifetimes measured in seconds or minutes.
Almost all Unix kernels update system statistics no more frequently than
once a second.
The two problems are measuring the peak and the average variable values. To get both, you'll need a combination of short- and long-term measurements. Long-term averages are good for smoothing out the short-term peaks to determine a typical workload. Solving for the peak, or worst case, is either impractical or economically unsound. The major problem with long-term measurement is that it can be misleading. A bank that completes 9,000 transactions a day should know the time distribution of that work. Spread out over a 5-hour period, that's a relatively serene workload of one transaction every 2 seconds, but if all of the transactions are processed in the last 15 minutes of the day, it's an intense 600 transactions a second. Short-term data tells you something about the actual distribution of points in a long-term average.
Short measurement periods give you the system administrator's equivalent of instantaneous data. Choose the right sampling interval and you'll see the spikes in network load, disk I/O, and CPU utilization that are the first pangs of performance fear. How short is short? Take your short-term measurements at the same frequency as your expected peaks, so you don't blend two peaks into one as shown in the diagram Twin peaks. Consider measuring every 10 minutes for the long-term average and every 10 seconds for a short-term period. If you find several short-term samples with no activity, lengthen the short-term interval.
Sensitivity, correctness, and weighty
issues
Now you know what to measure and for how long. How confident are you in
your data? How much does a change in the denominator change the numerator?
If the denominator is too small, minor fluctuations can send your ratio
into wild gyrations. Ideally, the relationship between numerator and
denominator should be sublinear. Otherwise, doubling the bottom changes
more than doubling the top, producing a ratio that can explode. At the same
time, evaluate the maximum error represented in the ratio. How accurately
are you measuring events? Could you use a longer measurement period? Is it
possible to miss data while measuring? The accuracy of a ratio is
multiplied by its sensitivity; a small understatement in a ratio that grows
superlinearly with its denominator turns into a large error. When you
multiply two inexact numbers, you also multiply their errors together.
Looking at 50 I/O operations per second, plus or minus 5 Iops is
reasonable, but 50 Iops plus or minus 45 Iops is the same as taking a
guess.
Don't think purely of two-variable quotients. Sometimes the ratio of variable products proves more useful as a momentum indicator. The best example is the stock market, which uses the Arms index to track the number of shares moving up/down versus the total up/down volume ratio. The Arms index tells you whether the up or down stocks are trading in a proportionate volume. When equal to one, there is little momentum. When the index goes above one, the down stocks dominate trading, and the further the index falls below one, the more the up stocks are leading the trading through higher volume.
Consider something like byte-days for user storage as a measure of the average age of your disk space. For each file in the system, multiply its size by its age (last accessed) in days, and take an average. Since the average is weighted, large, unused files increase the metric, which gives a better feel for how much data you might migrate to hierarchical storage than a simple unscaled average of access times. Divide the average by the number of days the disk has been in service by the filesystem size, and you get a feel for how well your data is aging. The smaller that ratio, the more frequently your data is being accessed. The closer the ratio is to unity, the more your disk has filled up with untouched junk.
Ratios are applicable to systems, networks, and other inanimate objects
because they live in a black-and-white world. People who manage these
systems can't be judged as easily. Bugs fixed per programmer is only
partially useful, because it doesn't account for the difficulty of the bug
or the quality of the fix. Do you want someone who works faster but with
less emphasis on correctness? In addition to measuring your performance,
tackle the soft problems of career and personal growth or you might find
BeanMasters with the green eyeshades more interesting than WebMasters. See
the sidebar, How do you do what you
do? for some ideas. Set goals for improving yourself and your systems,
and generate measured enthusiasm for your job. ![]()
About the author
Hal Stern is an area technology manager for Sun. He can be reached at
hal.stern@sunworld.com.
![]() You can buy Hal Stern's
Managing NFS and NIS at Amazon.com Books.
You can buy Hal Stern's
Managing NFS and NIS at Amazon.com Books.
(A list of Hal Stern's Sysadmin columns in SunWorld Online.)
![]()
![]()
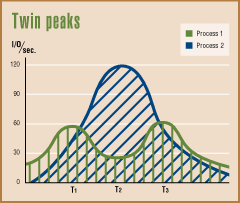
If you measure at time intervals T1, T2, and T3, you'll see the difference between the two processes. Sample at T1 and T3 only, however, and the process 1 and process 2 I/O patterns are indistinguishable. The total number of I/Os completed during the sample times (the area under the curves) are about the same.
![]()
![]()
![]()
![]()
Talk to facilities planners. The space under the machine room floor is home to power raceways, cooling pipes, and possibly some cold air. Engineers who design machine rooms and physical plants can teach you wonders about alternating current and air conditioning. Take the time to learn about your facility from harmonics (noise generated on your power distribution lines by computer equipment) to halon (a commonly used but now less favored fire-extinguishing gas). Could your machine room handle more systems? What happens if the air conditioner fails? How much does floor space cost, in real dollars? How might you change your disk-buying plans after learning the cost of location, location, and location? You can meet a variety of facilities managers, contingency planners, and building experts through the Uninterruptible Uptime User's Group, which meets semi-annually. Contact UUUG at PO Box 2697, New York, NY 10163, or call them at 212-575-2275 for more information.
Play out some worst-case scenarios. Risk analysis sounds like the exclusive domain of military planners and investment counselors, but it's a very real part of any job in which you assume responsibility for critical people or data assets. What are the technical risks that could hurt you the most? Could you react if a supplier wanted to use Electronic Data Interchange (EDI) instead of paperwork? If you were required to reduce paper consumption by 25 percent, could you implement the controls and provide alternatives for the printer hounds? If one of your vendors could no longer deliver a product, what would your insurance plan dictate? Would your lawyers like to escrow code and documentation, to be accessed if a small vendor failed after you utilized their product as a critical component of your environment? Do you escrow your own products, notes, and documentation? Instead of losing products, what if you lose one or two system managers to a start-up? In the worst-case scenario, what if you lost a system administrator to a budget cut and the layoff ax?
Put your ideas into writing. Don't overlook the power of publishing at technical conferences, trade shows, or on your own World Wide Web page. Use the documentation process as a chance to explore HTML. The better you get at telling a convincing and concise story, the more successful you'll be at dealing with upper management (a topic we'll return to next month). Find those aspects of your job that are not repetitive and that you consider your defining and differentiating work. What are you doing safer, faster, or more creatively than the next company or person out there? Turn those nuggets into technical papers. If you can't find anything unique, it's a fair bet that you're stuck in fire-fighting mode or doing repetitive, low value-add tasks.
![]()
![]()
If you have problems with this magazine, contact webmaster@sunworld.com
URL:
http://www.sunworld.com/asm-01-1995/asm-01-sysadmin.html.
Last updated: 1 January 1995.